注意
转到末尾以下载完整示例代码,或通过 JupyterLite 或 Binder 在浏览器中运行此示例。
文本数据集上的半监督分类#
此示例演示了在标记数据稀缺时,半监督学习在TF-IDF特征上进行文本分类的有效性。为此,我们比较了四种不同的方法:
使用训练集中 100% 标记的监督学习(最佳情况)
使用
SGDClassifier进行完全监督代表标记数据充足时可能的最佳性能
使用训练集中 20% 标记的监督学习(基准)
与最佳情况相同的模型,但在标记训练数据的随机 20% 子集上进行训练
显示由于标记数据有限而导致的完全监督模型的性能下降
-
使用 20% 标记数据 + 80% 未标记数据进行训练
迭代预测未标记数据的标签
演示自训练如何提高性能
LabelSpreading(半监督)使用 20% 标记数据 + 80% 未标记数据进行训练
通过数据流形传播标签
展示基于图的方法如何利用未标记数据
此示例使用 20 newsgroups 数据集,重点关注五个类别。结果表明,通过有效利用未标记样本,半监督方法在标记数据有限的情况下可以实现优于监督学习的性能。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
from sklearn.linear_model import SGDClassifier
from sklearn.metrics import f1_score
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.semi_supervised import LabelSpreading, SelfTrainingClassifier
# Loading dataset containing first five categories
data = fetch_20newsgroups(
subset="train",
categories=[
"alt.atheism",
"comp.graphics",
"comp.os.ms-windows.misc",
"comp.sys.ibm.pc.hardware",
"comp.sys.mac.hardware",
],
)
# Parameters
sdg_params = dict(alpha=1e-5, penalty="l2", loss="log_loss")
vectorizer_params = dict(ngram_range=(1, 2), min_df=5, max_df=0.8)
# Supervised Pipeline
pipeline = Pipeline(
[
("vect", CountVectorizer(**vectorizer_params)),
("tfidf", TfidfTransformer()),
("clf", SGDClassifier(**sdg_params)),
]
)
# SelfTraining Pipeline
st_pipeline = Pipeline(
[
("vect", CountVectorizer(**vectorizer_params)),
("tfidf", TfidfTransformer()),
("clf", SelfTrainingClassifier(SGDClassifier(**sdg_params))),
]
)
# LabelSpreading Pipeline
ls_pipeline = Pipeline(
[
("vect", CountVectorizer(**vectorizer_params)),
("tfidf", TfidfTransformer()),
("clf", LabelSpreading()),
]
)
def eval_and_get_f1(clf, X_train, y_train, X_test, y_test):
"""Evaluate model performance and return F1 score"""
print(f" Number of training samples: {len(X_train)}")
print(f" Unlabeled samples in training set: {sum(1 for x in y_train if x == -1)}")
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
f1 = f1_score(y_test, y_pred, average="micro")
print(f" Micro-averaged F1 score on test set: {f1:.3f}")
print("\n")
return f1
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
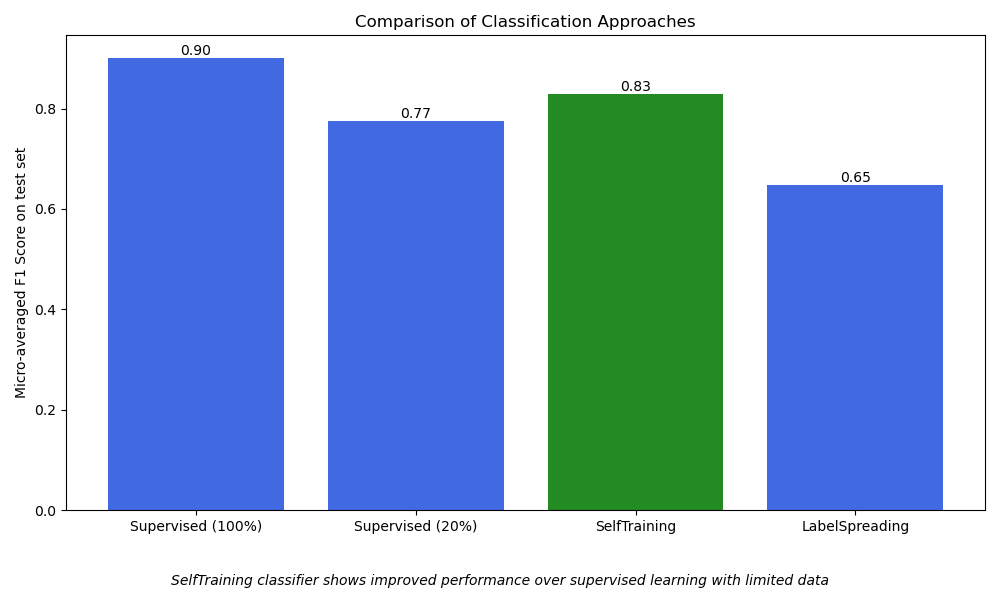
1. 评估使用 100%(标记)训练集的监督式 SGDClassifier。这代表了当模型可以完全访问所有标记示例时的最佳性能。
f1_scores = {}
print("1. Supervised SGDClassifier on 100% of the data:")
f1_scores["Supervised (100%)"] = eval_and_get_f1(
pipeline, X_train, y_train, X_test, y_test
)
1. Supervised SGDClassifier on 100% of the data:
Number of training samples: 2117
Unlabeled samples in training set: 0
Micro-averaged F1 score on test set: 0.901
2. 评估仅使用 20% 数据进行训练的监督式 SGDClassifier。这作为一个基准,用于说明限制训练样本所导致的性能下降。
import numpy as np
print("2. Supervised SGDClassifier on 20% of the training data:")
rng = np.random.default_rng(42)
y_mask = rng.random(len(y_train)) < 0.2
# X_20 and y_20 are the subset of the train dataset indicated by the mask
X_20, y_20 = map(list, zip(*((x, y) for x, y, m in zip(X_train, y_train, y_mask) if m)))
f1_scores["Supervised (20%)"] = eval_and_get_f1(pipeline, X_20, y_20, X_test, y_test)
2. Supervised SGDClassifier on 20% of the training data:
Number of training samples: 434
Unlabeled samples in training set: 0
Micro-averaged F1 score on test set: 0.775
3. 评估使用 20% 标记数据和 80% 未标记数据的半监督 SelfTrainingClassifier。剩余的 80% 训练标签被屏蔽为未标记 (-1),允许模型迭代地对它们进行标记和学习。
print(
"3. SelfTrainingClassifier (semi-supervised) using 20% labeled "
"+ 80% unlabeled data):"
)
y_train_semi = y_train.copy()
y_train_semi[~y_mask] = -1
f1_scores["SelfTraining"] = eval_and_get_f1(
st_pipeline, X_train, y_train_semi, X_test, y_test
)
3. SelfTrainingClassifier (semi-supervised) using 20% labeled + 80% unlabeled data):
Number of training samples: 2117
Unlabeled samples in training set: 1683
Micro-averaged F1 score on test set: 0.829
4. 评估使用 20% 标记数据和 80% 未标记数据的半监督 LabelSpreading 模型。与 SelfTraining 类似,模型推断未标记部分数据的标签以提高性能。
print("4. LabelSpreading (semi-supervised) using 20% labeled + 80% unlabeled data:")
f1_scores["LabelSpreading"] = eval_and_get_f1(
ls_pipeline, X_train, y_train_semi, X_test, y_test
)
4. LabelSpreading (semi-supervised) using 20% labeled + 80% unlabeled data:
Number of training samples: 2117
Unlabeled samples in training set: 1683
Micro-averaged F1 score on test set: 0.647
绘制结果#
使用条形图可视化不同分类方法的性能。这有助于比较每种方法基于微平均f1_score的性能。微平均计算跨所有类别的指标,提供一个单一的整体性能衡量标准,并允许在存在类别不平衡的情况下公平比较不同方法。
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
models = list(f1_scores.keys())
scores = list(f1_scores.values())
colors = ["royalblue", "royalblue", "forestgreen", "royalblue"]
bars = plt.bar(models, scores, color=colors)
plt.title("Comparison of Classification Approaches")
plt.ylabel("Micro-averaged F1 Score on test set")
plt.xticks()
for bar in bars:
height = bar.get_height()
plt.text(
bar.get_x() + bar.get_width() / 2.0,
height,
f"{height:.2f}",
ha="center",
va="bottom",
)
plt.figtext(
0.5,
0.02,
"SelfTraining classifier shows improved performance over "
"supervised learning with limited data",
ha="center",
va="bottom",
fontsize=10,
style="italic",
)
plt.tight_layout()
plt.subplots_adjust(bottom=0.15)
plt.show()
脚本总运行时间: (0 分钟 4.771 秒)
相关示例