注意
前往末尾 下载完整示例代码。或者通过 JupyterLite 或 Binder 在浏览器中运行此示例
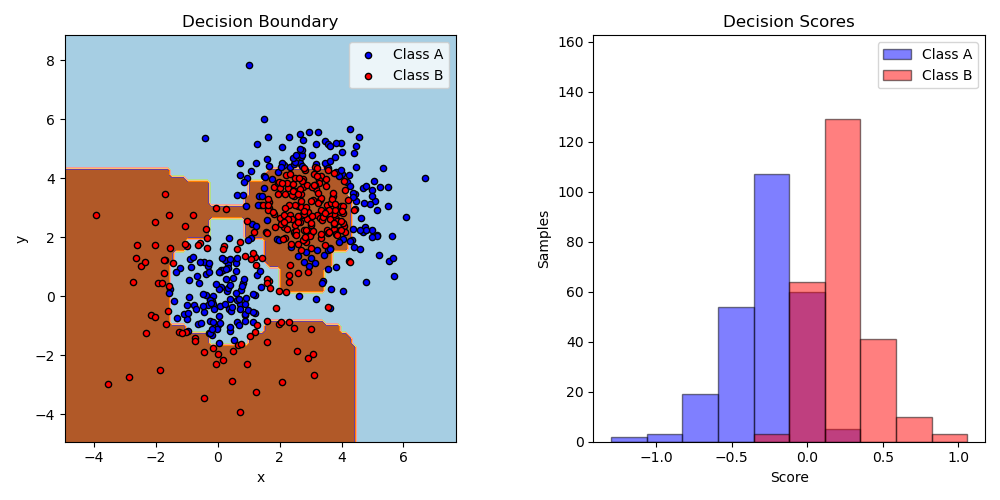
二分类 AdaBoost#
此示例在由两个“高斯分位数”聚类(参见 sklearn.datasets.make_gaussian_quantiles)组成的非线性可分分类数据集上拟合一个 AdaBoosted 决策树桩,并绘制决策边界和决策分数。决策分数的分布分别显示了 A 类和 B 类样本。每个样本的预测类别标签由决策分数符号决定。决策分数大于零的样本被分类为 B,否则分类为 A。决策分数的大小决定了与预测类别标签的相似程度。此外,可以构建一个新数据集,例如,仅选择决策分数高于某个值的样本,以包含所需纯度的 B 类样本。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_gaussian_quantiles
from sklearn.ensemble import AdaBoostClassifier
from sklearn.inspection import DecisionBoundaryDisplay
from sklearn.tree import DecisionTreeClassifier
# Construct dataset
X1, y1 = make_gaussian_quantiles(
cov=2.0, n_samples=200, n_features=2, n_classes=2, random_state=1
)
X2, y2 = make_gaussian_quantiles(
mean=(3, 3), cov=1.5, n_samples=300, n_features=2, n_classes=2, random_state=1
)
X = np.concatenate((X1, X2))
y = np.concatenate((y1, -y2 + 1))
# Create and fit an AdaBoosted decision tree
bdt = AdaBoostClassifier(DecisionTreeClassifier(max_depth=1), n_estimators=200)
bdt.fit(X, y)
plot_colors = "br"
plot_step = 0.02
class_names = "AB"
plt.figure(figsize=(10, 5))
# Plot the decision boundaries
ax = plt.subplot(121)
disp = DecisionBoundaryDisplay.from_estimator(
bdt,
X,
cmap=plt.cm.Paired,
response_method="predict",
ax=ax,
xlabel="x",
ylabel="y",
)
x_min, x_max = disp.xx0.min(), disp.xx0.max()
y_min, y_max = disp.xx1.min(), disp.xx1.max()
plt.axis("tight")
# Plot the training points
for i, n, c in zip(range(2), class_names, plot_colors):
idx = (y == i).nonzero()
plt.scatter(
X[idx, 0],
X[idx, 1],
c=c,
s=20,
edgecolor="k",
label="Class %s" % n,
)
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.legend(loc="upper right")
plt.title("Decision Boundary")
# Plot the two-class decision scores
twoclass_output = bdt.decision_function(X)
plot_range = (twoclass_output.min(), twoclass_output.max())
plt.subplot(122)
for i, n, c in zip(range(2), class_names, plot_colors):
plt.hist(
twoclass_output[y == i],
bins=10,
range=plot_range,
facecolor=c,
label="Class %s" % n,
alpha=0.5,
edgecolor="k",
)
x1, x2, y1, y2 = plt.axis()
plt.axis((x1, x2, y1, y2 * 1.2))
plt.legend(loc="upper right")
plt.ylabel("Samples")
plt.xlabel("Score")
plt.title("Decision Scores")
plt.tight_layout()
plt.subplots_adjust(wspace=0.35)
plt.show()
脚本总运行时间: (0 分 0.669 秒)
相关示例