注意
转到末尾 下载完整的示例代码或通过 JupyterLite 或 Binder 在浏览器中运行此示例。
核主成分分析(Kernel PCA)#
此示例展示了主成分分析 (PCA) 及其核化版本 (KernelPCA) 之间的区别。
一方面,我们展示了 KernelPCA 能够找到一个线性分离数据的投影,而 PCA 则无法做到。
最后,我们展示了使用 KernelPCA 对该投影进行反演是一种近似,而使用 PCA 则是精确的。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
投影数据:PCA vs. KernelPCA#
在本节中,我们将展示在使用主成分分析 (PCA) 投影数据时使用核的优势。我们创建了一个由两个嵌套圆圈组成的数据集。
from sklearn.datasets import make_circles
from sklearn.model_selection import train_test_split
X, y = make_circles(n_samples=1_000, factor=0.3, noise=0.05, random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)
让我们快速查看一下生成的数据集。
import matplotlib.pyplot as plt
_, (train_ax, test_ax) = plt.subplots(ncols=2, sharex=True, sharey=True, figsize=(8, 4))
train_ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train)
train_ax.set_ylabel("Feature #1")
train_ax.set_xlabel("Feature #0")
train_ax.set_title("Training data")
test_ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test)
test_ax.set_xlabel("Feature #0")
_ = test_ax.set_title("Testing data")
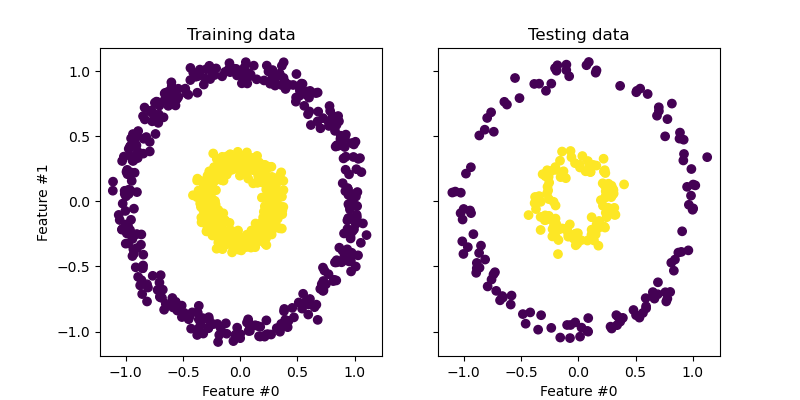
来自每个类别的样本无法线性分离:没有直线可以将内部集合的样本与外部集合的样本分开。
现在,我们将使用带有核和不带核的 PCA 来查看使用此类核的效果。这里使用的核是径向基函数(RBF)核。
fig, (orig_data_ax, pca_proj_ax, kernel_pca_proj_ax) = plt.subplots(
ncols=3, figsize=(14, 4)
)
orig_data_ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test)
orig_data_ax.set_ylabel("Feature #1")
orig_data_ax.set_xlabel("Feature #0")
orig_data_ax.set_title("Testing data")
pca_proj_ax.scatter(X_test_pca[:, 0], X_test_pca[:, 1], c=y_test)
pca_proj_ax.set_ylabel("Principal component #1")
pca_proj_ax.set_xlabel("Principal component #0")
pca_proj_ax.set_title("Projection of testing data\n using PCA")
kernel_pca_proj_ax.scatter(X_test_kernel_pca[:, 0], X_test_kernel_pca[:, 1], c=y_test)
kernel_pca_proj_ax.set_ylabel("Principal component #1")
kernel_pca_proj_ax.set_xlabel("Principal component #0")
_ = kernel_pca_proj_ax.set_title("Projection of testing data\n using KernelPCA")
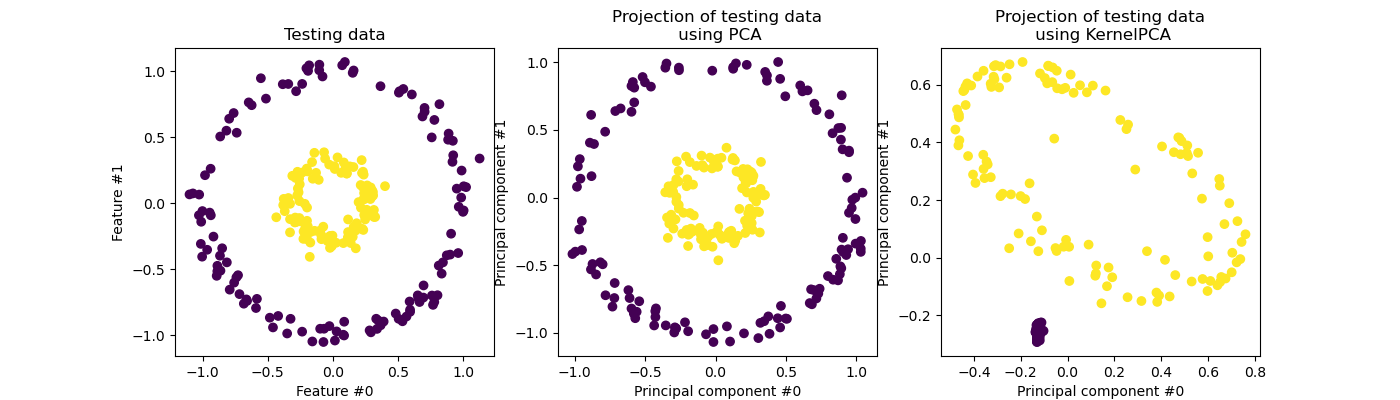
我们回顾一下,PCA 对数据进行线性变换。直观地说,这意味着坐标系将以其方差为中心,在每个分量上重新缩放,最后旋转。通过此变换获得的数据是各向同性的,现在可以投影到其主成分上。
因此,查看使用 PCA 进行的投影(即中间图),我们看到缩放方面没有变化;事实上,数据是两个以零为中心的同心圆,原始数据已经是各向同性的。但是,我们可以看到数据已经旋转。总而言之,我们看到如果定义一个线性分类器来区分两个类别的样本,这样的投影将无济于事。
使用核可以进行非线性投影。在这里,通过使用 RBF 核,我们期望投影将展开数据集,同时大致保留原始空间中彼此接近的数据点对的相对距离。
我们在右侧的图中观察到了这种行为:给定类别的样本彼此之间比与相反类别的样本更接近,从而解开了两个样本集。现在,我们可以使用线性分类器来分离两个类别的样本。
投影回原始特征空间#
使用 KernelPCA 时需要记住的一个特殊性与重建有关(即反向投影到原始特征空间)。使用 PCA 时,如果 n_components 与原始特征的数量相同,则重建将是精确的。本例中就是这种情况。
我们可以研究使用 KernelPCA 进行反向投影时是否得到原始数据集。
X_reconstructed_pca = pca.inverse_transform(pca.transform(X_test))
X_reconstructed_kernel_pca = kernel_pca.inverse_transform(kernel_pca.transform(X_test))
fig, (orig_data_ax, pca_back_proj_ax, kernel_pca_back_proj_ax) = plt.subplots(
ncols=3, sharex=True, sharey=True, figsize=(13, 4)
)
orig_data_ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test)
orig_data_ax.set_ylabel("Feature #1")
orig_data_ax.set_xlabel("Feature #0")
orig_data_ax.set_title("Original test data")
pca_back_proj_ax.scatter(X_reconstructed_pca[:, 0], X_reconstructed_pca[:, 1], c=y_test)
pca_back_proj_ax.set_xlabel("Feature #0")
pca_back_proj_ax.set_title("Reconstruction via PCA")
kernel_pca_back_proj_ax.scatter(
X_reconstructed_kernel_pca[:, 0], X_reconstructed_kernel_pca[:, 1], c=y_test
)
kernel_pca_back_proj_ax.set_xlabel("Feature #0")
_ = kernel_pca_back_proj_ax.set_title("Reconstruction via KernelPCA")
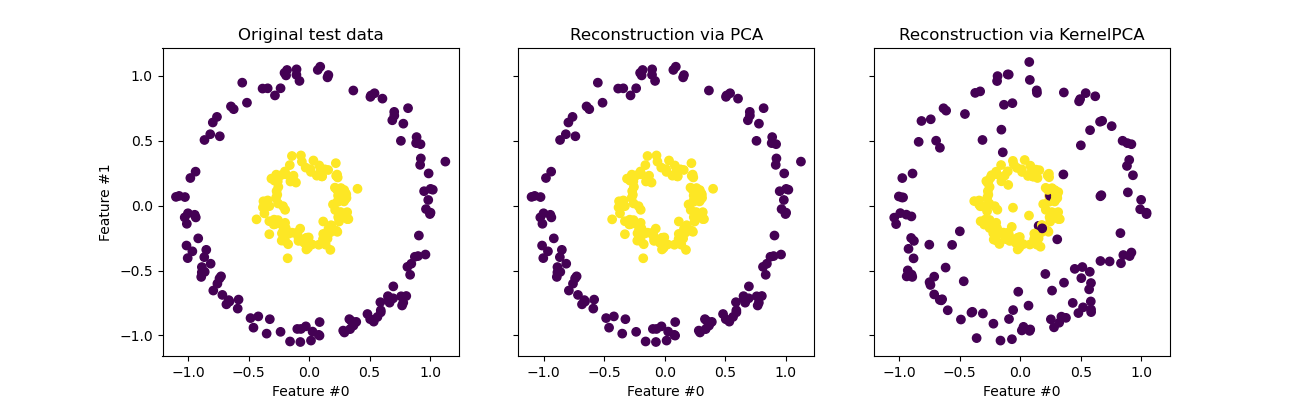
虽然我们看到使用 PCA 进行了完美的重建,但对于 KernelPCA,我们观察到了不同的结果。
事实上,inverse_transform 不能依赖于解析反向投影,因此不能进行精确重建。相反,内部会训练一个 KernelRidge 来学习从核化 PCA 基础到原始特征空间的映射。因此,这种方法带有近似性,在反向投影到原始特征空间时会引入细微差异。
为了改进使用 inverse_transform 的重建,可以调整 KernelPCA 中的 alpha,这是一个正则化项,用于控制在训练映射时对训练数据的依赖程度。
脚本总运行时间: (0 minutes 0.508 seconds)
相关示例