注意
转到末尾 下载完整示例代码,或通过 JupyterLite 或 Binder 在浏览器中运行此示例
F检验与互信息比较#
本示例阐释了单变量 F 检验统计量与互信息之间的区别。
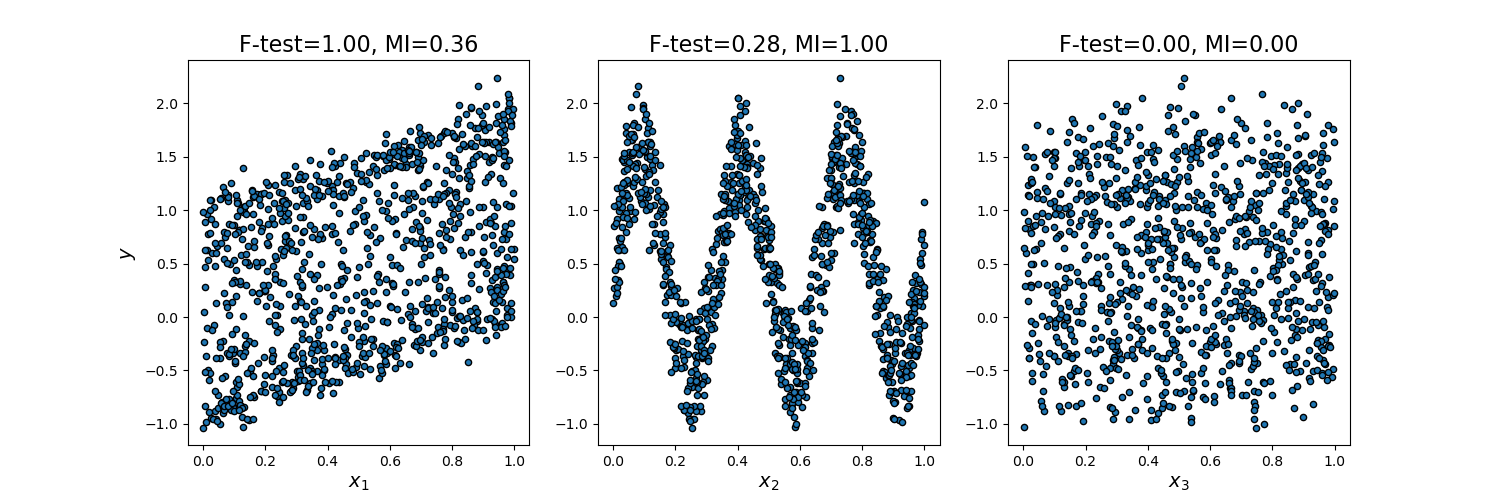
我们考虑在 [0, 1] 上均匀分布的 3 个特征 x_1、x_2、x_3,目标变量 y 依赖于它们,具体如下:
y = x_1 + sin(6 * pi * x_2) + 0.1 * N(0, 1),这意味着第三个特征完全不相关。
下面的代码绘制了 y 对各个 x_i 的依赖关系,以及单变量 F 检验统计量和互信息的归一化值。
由于 F 检验仅捕获线性依赖关系,它将 x_1 评为最具区分度的特征。另一方面,互信息可以捕获变量间的任何类型的依赖关系,它将 x_2 评为最具区分度的特征,这可能更符合我们对此示例的直观认知。两种方法都正确地将 x_3 标记为不相关。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
from sklearn.feature_selection import f_regression, mutual_info_regression
np.random.seed(0)
X = np.random.rand(1000, 3)
y = X[:, 0] + np.sin(6 * np.pi * X[:, 1]) + 0.1 * np.random.randn(1000)
f_test, _ = f_regression(X, y)
f_test /= np.max(f_test)
mi = mutual_info_regression(X, y)
mi /= np.max(mi)
plt.figure(figsize=(15, 5))
for i in range(3):
plt.subplot(1, 3, i + 1)
plt.scatter(X[:, i], y, edgecolor="black", s=20)
plt.xlabel("$x_{}$".format(i + 1), fontsize=14)
if i == 0:
plt.ylabel("$y$", fontsize=14)
plt.title("F-test={:.2f}, MI={:.2f}".format(f_test[i], mi[i]), fontsize=16)
plt.show()
脚本总运行时间: (0 分钟 0.223 秒)
相关示例