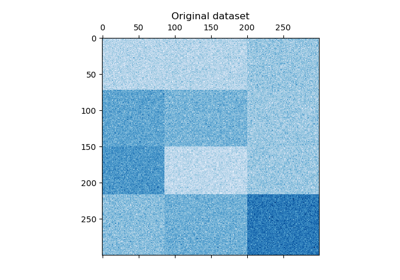
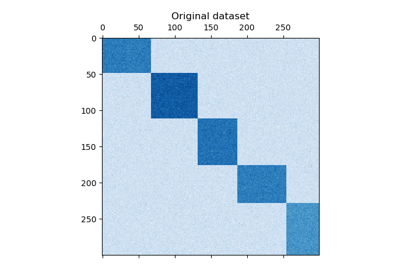
Biclustering# Examples concerning biclustering techniques. 谱双聚类算法演示 谱双聚类算法演示 谱协同聚类算法演示 谱协同聚类算法演示 使用谱协同聚类算法对文档进行双聚类 使用谱协同聚类算法对文档进行双聚类