注意
转到末尾以下载完整示例代码,或通过 JupyterLite 或 Binder 在浏览器中运行此示例。
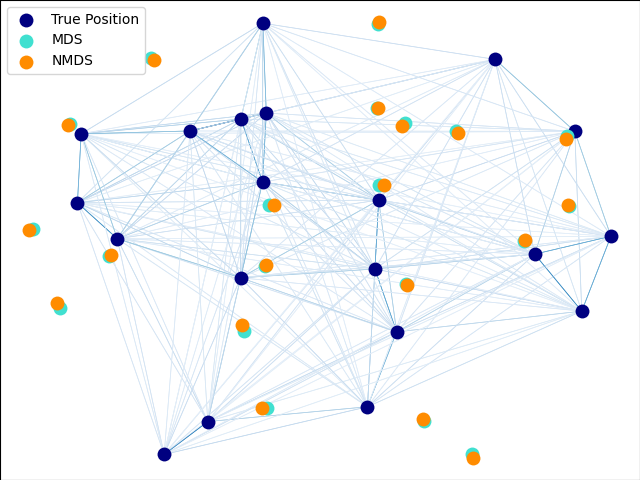
多维标度#
在生成的带噪声数据上演示度量和非度量MDS。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
数据集准备#
我们首先在二维空间中均匀生成20个点。
import numpy as np
from matplotlib import pyplot as plt
from matplotlib.collections import LineCollection
from sklearn import manifold
from sklearn.decomposition import PCA
from sklearn.metrics import euclidean_distances
# Generate the data
EPSILON = np.finfo(np.float32).eps
n_samples = 20
rng = np.random.RandomState(seed=3)
X_true = rng.randint(0, 20, 2 * n_samples).astype(float)
X_true = X_true.reshape((n_samples, 2))
# Center the data
X_true -= X_true.mean()
现在我们计算所有点之间的成对距离,并向距离矩阵添加少量噪声。我们确保保持带噪声的距离矩阵对称。
# Compute pairwise Euclidean distances
distances = euclidean_distances(X_true)
# Add noise to the distances
noise = rng.rand(n_samples, n_samples)
noise = noise + noise.T
np.fill_diagonal(noise, 0)
distances += noise
在这里,我们计算带噪声距离矩阵的度量、非度量和经典MDS。
mds = manifold.MDS(
n_components=2,
max_iter=3000,
eps=1e-9,
n_init=1,
random_state=42,
metric="precomputed",
n_jobs=1,
init="classical_mds",
)
X_mds = mds.fit(distances).embedding_
nmds = manifold.MDS(
n_components=2,
metric_mds=False,
max_iter=3000,
eps=1e-12,
metric="precomputed",
random_state=42,
n_jobs=1,
n_init=1,
init="classical_mds",
)
X_nmds = nmds.fit_transform(distances)
cmds = manifold.ClassicalMDS(
n_components=2,
metric="precomputed",
)
X_cmds = cmds.fit_transform(distances)
重新缩放非度量MDS解,使其与原始数据的分布相匹配。
为了使视觉比较更容易,我们将原始数据和所有MDS解旋转到它们的PCA轴上。如果需要,翻转水平和垂直MDS轴,以匹配原始数据方向。
# Rotate the data (CMDS does not need to be rotated, it is inherently PCA-aligned)
pca = PCA(n_components=2)
X_true = pca.fit_transform(X_true)
X_mds = pca.fit_transform(X_mds)
X_nmds = pca.fit_transform(X_nmds)
# Align the sign of PCs
for i in [0, 1]:
if np.corrcoef(X_mds[:, i], X_true[:, i])[0, 1] < 0:
X_mds[:, i] *= -1
if np.corrcoef(X_nmds[:, i], X_true[:, i])[0, 1] < 0:
X_nmds[:, i] *= -1
if np.corrcoef(X_cmds[:, i], X_true[:, i])[0, 1] < 0:
X_cmds[:, i] *= -1
最后,我们绘制原始数据和所有MDS重建。
fig = plt.figure(1)
ax = plt.axes([0.0, 0.0, 1.0, 1.0])
s = 100
plt.scatter(X_true[:, 0], X_true[:, 1], color="navy", s=s, lw=0, label="True Position")
plt.scatter(X_mds[:, 0], X_mds[:, 1], color="turquoise", s=s, lw=0, label="MDS")
plt.scatter(
X_nmds[:, 0], X_nmds[:, 1], color="darkorange", s=s, lw=0, label="Non-metric MDS"
)
plt.scatter(
X_cmds[:, 0], X_cmds[:, 1], color="lightcoral", s=s, lw=0, label="Classical MDS"
)
plt.legend(scatterpoints=1, loc="best", shadow=False)
# Plot the edges
start_idx, end_idx = X_mds.nonzero()
# a sequence of (*line0*, *line1*, *line2*), where::
# linen = (x0, y0), (x1, y1), ... (xm, ym)
segments = [
[X_true[i, :], X_true[j, :]] for i in range(len(X_true)) for j in range(len(X_true))
]
edges = distances.max() / (distances + EPSILON) * 100
np.fill_diagonal(edges, 0)
edges = np.abs(edges)
lc = LineCollection(
segments, zorder=0, cmap=plt.cm.Blues, norm=plt.Normalize(0, edges.max())
)
lc.set_array(edges.flatten())
lc.set_linewidths(np.full(len(segments), 0.5))
ax.add_collection(lc)
plt.show()
脚本总运行时间: (0 minutes 0.151 seconds)
相关示例