注意
转到末尾 下载完整的示例代码或通过 JupyterLite 或 Binder 在浏览器中运行此示例。
多项式和样条插值#
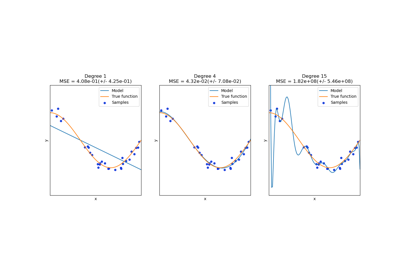
此示例演示如何使用岭回归将函数近似为最高次数为 degree 的多项式。我们展示了给定 n_samples 个一维点 x_i 的两种不同方法。
PolynomialFeatures生成最高次数为degree的所有单项式。这为我们提供了所谓的范德蒙矩阵,该矩阵有n_samples行和degree + 1列。[[1, x_0, x_0 ** 2, x_0 ** 3, ..., x_0 ** degree], [1, x_1, x_1 ** 2, x_1 ** 3, ..., x_1 ** degree], ...]
直观地看,这个矩阵可以被解释为伪特征(点提升到某个幂次)的矩阵。这个矩阵类似于(但不同于)由多项式核引起的矩阵。
SplineTransformer生成 B 样条基函数。B 样条的基函数是次数为degree的分段多项式函数,它仅在degree+1个连续节点之间非零。给定n_knots个节点数,这会生成一个有n_samples行和n_knots + degree - 1列的矩阵。[[basis_1(x_0), basis_2(x_0), ...], [basis_1(x_1), basis_2(x_1), ...], ...]
此示例表明,这两个转换器非常适合使用线性模型对非线性效应进行建模,使用管道添加非线性特征。核方法扩展了这一思想,可以诱导非常高维(甚至是无限维)的特征空间。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import Ridge
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures, SplineTransformer
我们首先定义一个我们打算近似的函数并准备绘制它。
def f(x):
"""Function to be approximated by polynomial interpolation."""
return x * np.sin(x)
# whole range we want to plot
x_plot = np.linspace(-1, 11, 100)
为了使它更有趣,我们只给出了一小部分点用于训练。
x_train = np.linspace(0, 10, 100)
rng = np.random.RandomState(0)
x_train = np.sort(rng.choice(x_train, size=20, replace=False))
y_train = f(x_train)
# create 2D-array versions of these arrays to feed to transformers
X_train = x_train[:, np.newaxis]
X_plot = x_plot[:, np.newaxis]
现在我们准备创建多项式特征和样条,拟合训练点并展示它们的插值效果。
# plot function
lw = 2
fig, ax = plt.subplots()
ax.set_prop_cycle(
color=["black", "teal", "yellowgreen", "gold", "darkorange", "tomato"]
)
ax.plot(x_plot, f(x_plot), linewidth=lw, label="ground truth")
# plot training points
ax.scatter(x_train, y_train, label="training points")
# polynomial features
for degree in [3, 4, 5]:
model = make_pipeline(PolynomialFeatures(degree), Ridge(alpha=1e-3))
model.fit(X_train, y_train)
y_plot = model.predict(X_plot)
ax.plot(x_plot, y_plot, label=f"degree {degree}")
# B-spline with 4 + 3 - 1 = 6 basis functions
model = make_pipeline(SplineTransformer(n_knots=4, degree=3), Ridge(alpha=1e-3))
model.fit(X_train, y_train)
y_plot = model.predict(X_plot)
ax.plot(x_plot, y_plot, label="B-spline")
ax.legend(loc="lower center")
ax.set_ylim(-20, 10)
plt.show()
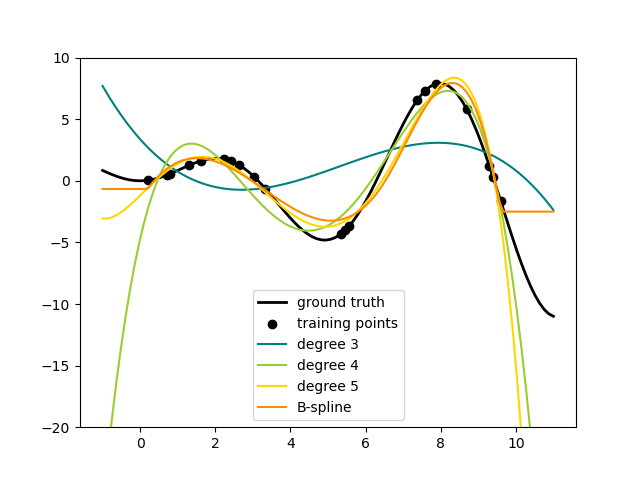
这清楚地表明,较高次数的多项式可以更好地拟合数据。但同时,过高的幂次可能会表现出不希望的振荡行为,并且对于超出拟合数据范围的推断特别危险。这是 B 样条的一个优势。它们通常能像多项式一样很好地拟合数据,并且表现出非常平滑的行为。它们还具有很好的选项来控制推断,默认为继续保持常数。请注意,大多数情况下,您宁愿增加节点的数量但保持 degree=3。
为了更深入地了解生成的特征基,我们分别绘制了两个转换器的所有列。
fig, axes = plt.subplots(ncols=2, figsize=(16, 5))
pft = PolynomialFeatures(degree=3).fit(X_train)
axes[0].plot(x_plot, pft.transform(X_plot))
axes[0].legend(axes[0].lines, [f"degree {n}" for n in range(4)])
axes[0].set_title("PolynomialFeatures")
splt = SplineTransformer(n_knots=4, degree=3).fit(X_train)
axes[1].plot(x_plot, splt.transform(X_plot))
axes[1].legend(axes[1].lines, [f"spline {n}" for n in range(6)])
axes[1].set_title("SplineTransformer")
# plot knots of spline
knots = splt.bsplines_[0].t
axes[1].vlines(knots[3:-3], ymin=0, ymax=0.8, linestyles="dashed")
plt.show()
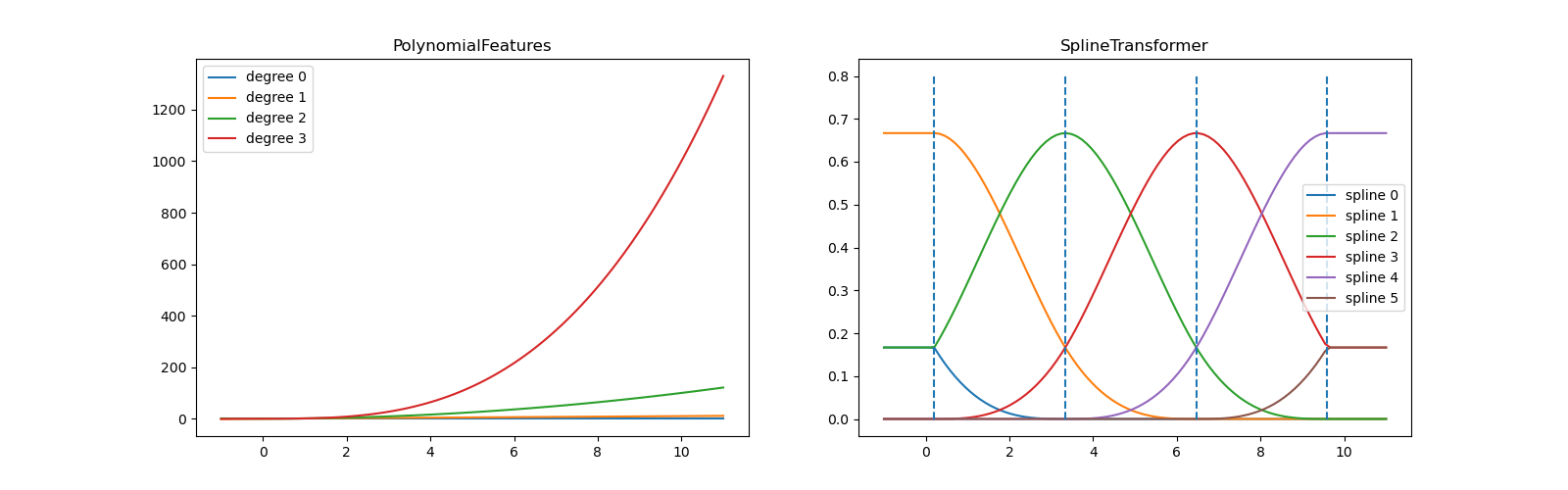
在左图中,我们识别出对应于从 x**0 到 x**3 的简单单项式的线条。在右图中,我们看到了 degree=3 的六个 B 样条基函数,以及在 fit 期间选择的四个节点位置。请注意,在拟合区间的左侧和右侧各有 degree 个额外的节点。这些是出于技术原因而存在的,所以我们避免显示它们。每个基函数都有局部支持,并在拟合范围之外继续为常数。这种推断行为可以通过参数 extrapolation 来改变。
周期性样条#
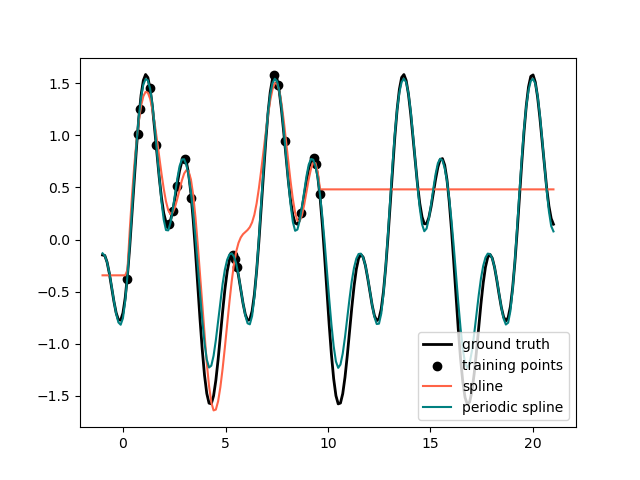
在前面的示例中,我们看到了多项式和样条在超出训练观测范围进行推断时的局限性。在某些设置中,例如有季节性效应时,我们期望底层信号具有周期性延续。这种效应可以使用周期性样条进行建模,周期性样条在第一个和最后一个节点处具有相等的函数值和相等的导数。在下面的例子中,我们展示了周期性样条如何提供更好的拟合,无论是在训练数据范围内还是范围之外,前提是我们给出了周期性的附加信息。样条周期是第一个节点和最后一个节点之间的距离,我们手动指定它。
周期性样条也可用于自然周期性特征(例如一年中的某一天),因为边界节点处的平滑性可以防止转换值发生跳跃(例如从 12 月 31 日到 1 月 1 日)。对于此类自然周期性特征或更一般的已知周期的特征,建议通过手动设置节点将此信息明确传递给 SplineTransformer。
def g(x):
"""Function to be approximated by periodic spline interpolation."""
return np.sin(x) - 0.7 * np.cos(x * 3)
y_train = g(x_train)
# Extend the test data into the future:
x_plot_ext = np.linspace(-1, 21, 200)
X_plot_ext = x_plot_ext[:, np.newaxis]
lw = 2
fig, ax = plt.subplots()
ax.set_prop_cycle(color=["black", "tomato", "teal"])
ax.plot(x_plot_ext, g(x_plot_ext), linewidth=lw, label="ground truth")
ax.scatter(x_train, y_train, label="training points")
for transformer, label in [
(SplineTransformer(degree=3, n_knots=10), "spline"),
(
SplineTransformer(
degree=3,
knots=np.linspace(0, 2 * np.pi, 10)[:, None],
extrapolation="periodic",
),
"periodic spline",
),
]:
model = make_pipeline(transformer, Ridge(alpha=1e-3))
model.fit(X_train, y_train)
y_plot_ext = model.predict(X_plot_ext)
ax.plot(x_plot_ext, y_plot_ext, label=label)
ax.legend()
fig.show()
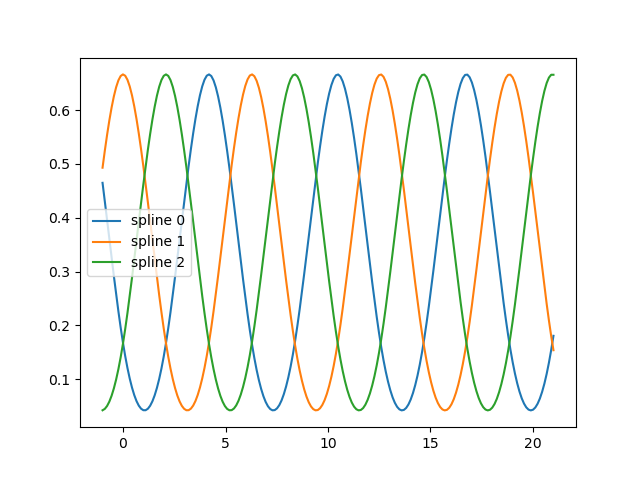
fig, ax = plt.subplots()
knots = np.linspace(0, 2 * np.pi, 4)
splt = SplineTransformer(knots=knots[:, None], degree=3, extrapolation="periodic").fit(
X_train
)
ax.plot(x_plot_ext, splt.transform(X_plot_ext))
ax.legend(ax.lines, [f"spline {n}" for n in range(3)])
plt.show()
脚本总运行时间: (0 minutes 0.348 seconds)
相关示例