注意
前往末尾 下载完整示例代码。或通过 JupyterLite 或 Binder 在浏览器中运行此示例
使用稀疏特征的文本文档分类#
这是一个示例,展示了 scikit-learn 如何使用 词袋模型 将文档按主题分类。此示例使用 Tf-idf 加权的文档-词稀疏矩阵来编码特征,并演示了各种能够高效处理稀疏矩阵的分类器。
对于通过无监督学习方法进行的文档分析,请参阅示例脚本 使用 k-means 对文本文档进行聚类。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
加载并向量化 20 个新闻组文本数据集#
我们定义了一个函数,用于从 20 个新闻组文本数据集 加载数据,该数据集包含大约 18,000 篇关于 20 个主题的新闻组帖子,分为两个子集:一个用于训练(或开发),另一个用于测试(或性能评估)。请注意,默认情况下,文本样本包含一些消息元数据,例如 'headers'(标题)、'footers'(签名)和引用其他帖子的 'quotes'。因此,fetch_20newsgroups 函数接受一个名为 remove 的参数,以尝试剥离此类信息,这些信息可能会使分类问题“过于简单”。这是通过简单的启发式方法实现的,这些方法既不完美也不标准化,因此默认情况下是禁用的。
from time import time
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
categories = [
"alt.atheism",
"talk.religion.misc",
"comp.graphics",
"sci.space",
]
def size_mb(docs):
return sum(len(s.encode("utf-8")) for s in docs) / 1e6
def load_dataset(verbose=False, remove=()):
"""Load and vectorize the 20 newsgroups dataset."""
data_train = fetch_20newsgroups(
subset="train",
categories=categories,
shuffle=True,
random_state=42,
remove=remove,
)
data_test = fetch_20newsgroups(
subset="test",
categories=categories,
shuffle=True,
random_state=42,
remove=remove,
)
# order of labels in `target_names` can be different from `categories`
target_names = data_train.target_names
# split target in a training set and a test set
y_train, y_test = data_train.target, data_test.target
# Extracting features from the training data using a sparse vectorizer
t0 = time()
vectorizer = TfidfVectorizer(
sublinear_tf=True, max_df=0.5, min_df=5, stop_words="english"
)
X_train = vectorizer.fit_transform(data_train.data)
duration_train = time() - t0
# Extracting features from the test data using the same vectorizer
t0 = time()
X_test = vectorizer.transform(data_test.data)
duration_test = time() - t0
feature_names = vectorizer.get_feature_names_out()
if verbose:
# compute size of loaded data
data_train_size_mb = size_mb(data_train.data)
data_test_size_mb = size_mb(data_test.data)
print(
f"{len(data_train.data)} documents - "
f"{data_train_size_mb:.2f}MB (training set)"
)
print(f"{len(data_test.data)} documents - {data_test_size_mb:.2f}MB (test set)")
print(f"{len(target_names)} categories")
print(
f"vectorize training done in {duration_train:.3f}s "
f"at {data_train_size_mb / duration_train:.3f}MB/s"
)
print(f"n_samples: {X_train.shape[0]}, n_features: {X_train.shape[1]}")
print(
f"vectorize testing done in {duration_test:.3f}s "
f"at {data_test_size_mb / duration_test:.3f}MB/s"
)
print(f"n_samples: {X_test.shape[0]}, n_features: {X_test.shape[1]}")
return X_train, X_test, y_train, y_test, feature_names, target_names
词袋文档分类器分析#
我们现在将训练一个分类器两次,一次是在包含元数据的文本样本上,另一次是在剥离元数据之后。对于这两种情况,我们将使用混淆矩阵分析测试集上的分类错误,并检查定义训练模型分类函数的系数。
不剥离元数据的模型#
我们首先使用自定义函数 load_dataset 加载不带元数据剥离的数据。
X_train, X_test, y_train, y_test, feature_names, target_names = load_dataset(
verbose=True
)
2034 documents - 3.98MB (training set)
1353 documents - 2.87MB (test set)
4 categories
vectorize training done in 0.355s at 11.218MB/s
n_samples: 2034, n_features: 7831
vectorize testing done in 0.233s at 12.285MB/s
n_samples: 1353, n_features: 7831
我们的第一个模型是 RidgeClassifier 类的一个实例。这是一种线性分类模型,它使用 {-1, 1} 编码目标上的均方误差,每个可能的类别对应一个目标。与 LogisticRegression 不同,RidgeClassifier 不提供概率预测(没有 predict_proba 方法),但通常训练速度更快。
from sklearn.linear_model import RidgeClassifier
clf = RidgeClassifier(tol=1e-2, solver="sparse_cg")
clf.fit(X_train, y_train)
pred = clf.predict(X_test)
我们绘制此分类器的混淆矩阵,以找出分类错误中是否存在模式。
import matplotlib.pyplot as plt
from sklearn.metrics import ConfusionMatrixDisplay
fig, ax = plt.subplots(figsize=(10, 5))
ConfusionMatrixDisplay.from_predictions(y_test, pred, ax=ax)
ax.xaxis.set_ticklabels(target_names)
ax.yaxis.set_ticklabels(target_names)
_ = ax.set_title(
f"Confusion Matrix for {clf.__class__.__name__}\non the original documents"
)
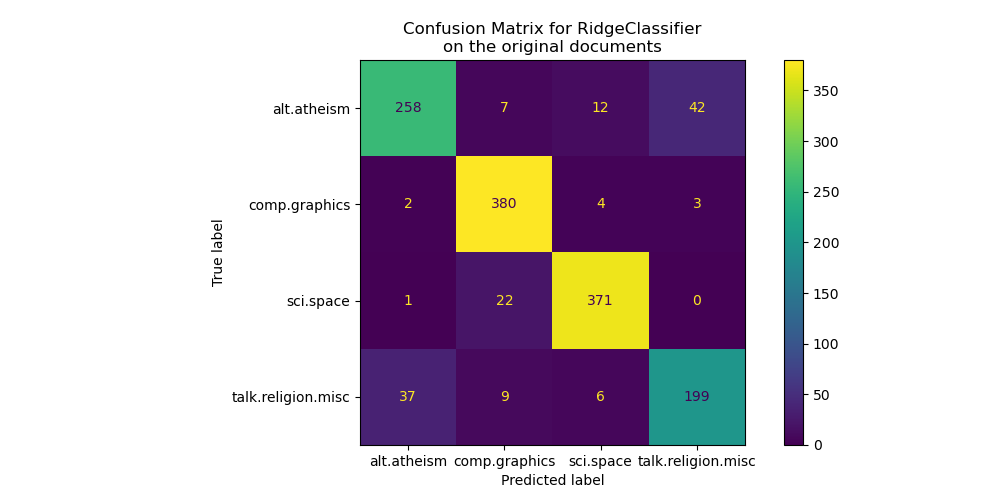
混淆矩阵突出显示,alt.atheism 类别的文档经常与 talk.religion.misc 类别的文档混淆,反之亦然,这是预期的,因为这些主题在语义上是相关的。
我们还观察到,sci.space 类别的某些文档可能被错误地归类为 comp.graphics,而反过来则要罕见得多。需要对这些分类错误的文档进行手动检查,以了解这种不对称性。可能空间主题的词汇比计算机图形学的词汇更具特异性。
通过查看具有最高平均特征效果的词语,我们可以更深入地了解此分类器如何做出决策
import numpy as np
import pandas as pd
def plot_feature_effects():
# learned coefficients weighted by frequency of appearance
average_feature_effects = clf.coef_ * np.asarray(X_train.mean(axis=0)).ravel()
for i, label in enumerate(target_names):
top5 = np.argsort(average_feature_effects[i])[-5:][::-1]
if i == 0:
top = pd.DataFrame(feature_names[top5], columns=[label])
top_indices = top5
else:
top[label] = feature_names[top5]
top_indices = np.concatenate((top_indices, top5), axis=None)
top_indices = np.unique(top_indices)
predictive_words = feature_names[top_indices]
# plot feature effects
bar_size = 0.25
padding = 0.75
y_locs = np.arange(len(top_indices)) * (4 * bar_size + padding)
fig, ax = plt.subplots(figsize=(10, 8))
for i, label in enumerate(target_names):
ax.barh(
y_locs + (i - 2) * bar_size,
average_feature_effects[i, top_indices],
height=bar_size,
label=label,
)
ax.set(
yticks=y_locs,
yticklabels=predictive_words,
ylim=[
0 - 4 * bar_size,
len(top_indices) * (4 * bar_size + padding) - 4 * bar_size,
],
)
ax.legend(loc="lower right")
print("top 5 keywords per class:")
print(top)
return ax
_ = plot_feature_effects().set_title("Average feature effect on the original data")
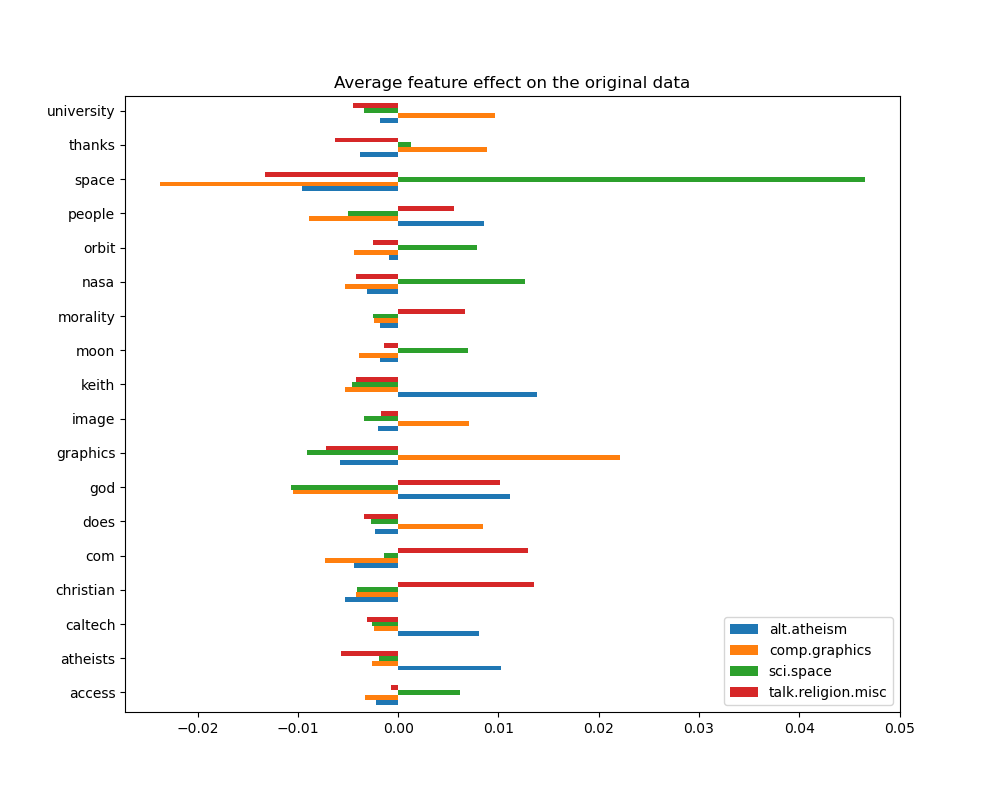
top 5 keywords per class:
alt.atheism comp.graphics sci.space talk.religion.misc
0 keith graphics space christian
1 god university nasa com
2 atheists thanks orbit god
3 people does moon morality
4 caltech image access people
我们可以观察到,最具预测性的词语通常与单个类别强烈正相关,而与所有其他类别负相关。大多数这些正相关性都非常容易解释。然而,一些词语如 "god" 和 "people" 与 "talk.misc.religion" 和 "alt.atheism" 都呈正相关,因为这两个类别预期会共享一些共同词汇。然而请注意,也有一些词语如 "christian" 和 "morality" 仅与 "talk.misc.religion" 呈正相关。此外,在此版本的数据集中,词语 "caltech" 是无神论的顶级预测特征之一,这归因于数据集中来自某种元数据(例如讨论中先前电子邮件发件人的电子邮件地址)的污染,如下所示
data_train = fetch_20newsgroups(
subset="train", categories=categories, shuffle=True, random_state=42
)
for doc in data_train.data:
if "caltech" in doc:
print(doc)
break
From: livesey@solntze.wpd.sgi.com (Jon Livesey)
Subject: Re: Morality? (was Re: <Political Atheists?)
Organization: sgi
Lines: 93
Distribution: world
NNTP-Posting-Host: solntze.wpd.sgi.com
In article <1qlettINN8oi@gap.caltech.edu>, keith@cco.caltech.edu (Keith Allan Schneider) writes:
|> livesey@solntze.wpd.sgi.com (Jon Livesey) writes:
|>
|> >>>Explain to me
|> >>>how instinctive acts can be moral acts, and I am happy to listen.
|> >>For example, if it were instinctive not to murder...
|> >
|> >Then not murdering would have no moral significance, since there
|> >would be nothing voluntary about it.
|>
|> See, there you go again, saying that a moral act is only significant
|> if it is "voluntary." Why do you think this?
If you force me to do something, am I morally responsible for it?
|>
|> And anyway, humans have the ability to disregard some of their instincts.
Well, make up your mind. Is it to be "instinctive not to murder"
or not?
|>
|> >>So, only intelligent beings can be moral, even if the bahavior of other
|> >>beings mimics theirs?
|> >
|> >You are starting to get the point. Mimicry is not necessarily the
|> >same as the action being imitated. A Parrot saying "Pretty Polly"
|> >isn't necessarily commenting on the pulchritude of Polly.
|>
|> You are attaching too many things to the term "moral," I think.
|> Let's try this: is it "good" that animals of the same species
|> don't kill each other. Or, do you think this is right?
It's not even correct. Animals of the same species do kill
one another.
|>
|> Or do you think that animals are machines, and that nothing they do
|> is either right nor wrong?
Sigh. I wonder how many times we have been round this loop.
I think that instinctive bahaviour has no moral significance.
I am quite prepared to believe that higher animals, such as
primates, have the beginnings of a moral sense, since they seem
to exhibit self-awareness.
|>
|>
|> >>Animals of the same species could kill each other arbitarily, but
|> >>they don't.
|> >
|> >They do. I and other posters have given you many examples of exactly
|> >this, but you seem to have a very short memory.
|>
|> Those weren't arbitrary killings. They were slayings related to some
|> sort of mating ritual or whatnot.
So what? Are you trying to say that some killing in animals
has a moral significance and some does not? Is this your
natural morality>
|>
|> >>Are you trying to say that this isn't an act of morality because
|> >>most animals aren't intelligent enough to think like we do?
|> >
|> >I'm saying:
|> > "There must be the possibility that the organism - it's not
|> > just people we are talking about - can consider alternatives."
|> >
|> >It's right there in the posting you are replying to.
|>
|> Yes it was, but I still don't understand your distinctions. What
|> do you mean by "consider?" Can a small child be moral? How about
|> a gorilla? A dolphin? A platypus? Where is the line drawn? Does
|> the being need to be self aware?
Are you blind? What do you think that this sentence means?
"There must be the possibility that the organism - it's not
just people we are talking about - can consider alternatives."
What would that imply?
|>
|> What *do* you call the mechanism which seems to prevent animals of
|> the same species from (arbitrarily) killing each other? Don't
|> you find the fact that they don't at all significant?
I find the fact that they do to be significant.
jon.
这些标题、签名页脚(以及引用自先前消息的元数据)可以被视为侧面信息,通过识别注册成员人为地揭示了新闻组,人们更希望我们的文本分类器只从每个文本文档的“主要内容”中学习,而不是依赖于泄露的作者身份。
剥离元数据的模型#
scikit-learn 中 20 个新闻组数据集加载器的 remove 选项允许启发式地尝试过滤掉一些不需要的元数据,这些元数据会人为地使分类问题变得更容易。请注意,这种文本内容过滤远非完美。
让我们尝试利用此选项来训练一个不过分依赖此类元数据做出决策的文本分类器
(
X_train,
X_test,
y_train,
y_test,
feature_names,
target_names,
) = load_dataset(remove=("headers", "footers", "quotes"))
clf = RidgeClassifier(tol=1e-2, solver="sparse_cg")
clf.fit(X_train, y_train)
pred = clf.predict(X_test)
fig, ax = plt.subplots(figsize=(10, 5))
ConfusionMatrixDisplay.from_predictions(y_test, pred, ax=ax)
ax.xaxis.set_ticklabels(target_names)
ax.yaxis.set_ticklabels(target_names)
_ = ax.set_title(
f"Confusion Matrix for {clf.__class__.__name__}\non filtered documents"
)
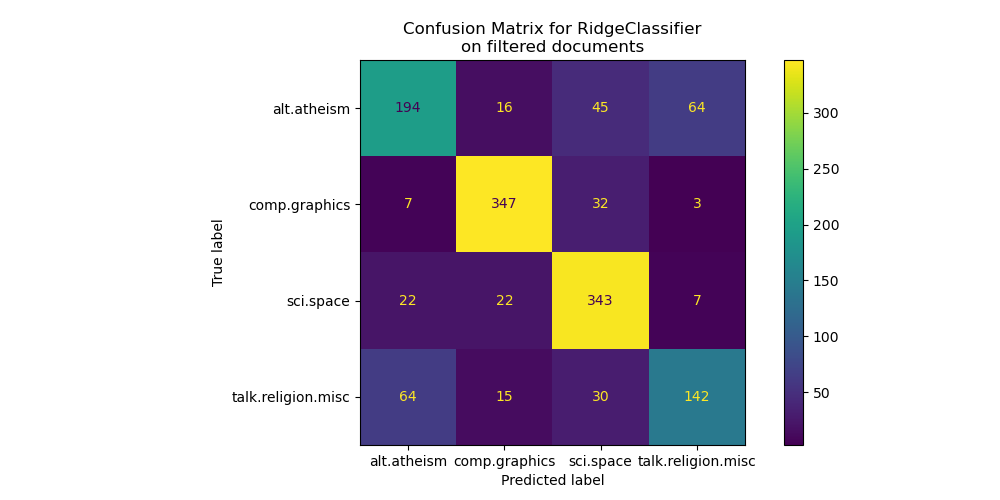
通过查看混淆矩阵,更明显的是,使用元数据训练的模型的得分过于乐观。无法访问元数据的分类问题准确性较低,但更能代表预期的文本分类问题。
_ = plot_feature_effects().set_title("Average feature effects on filtered documents")
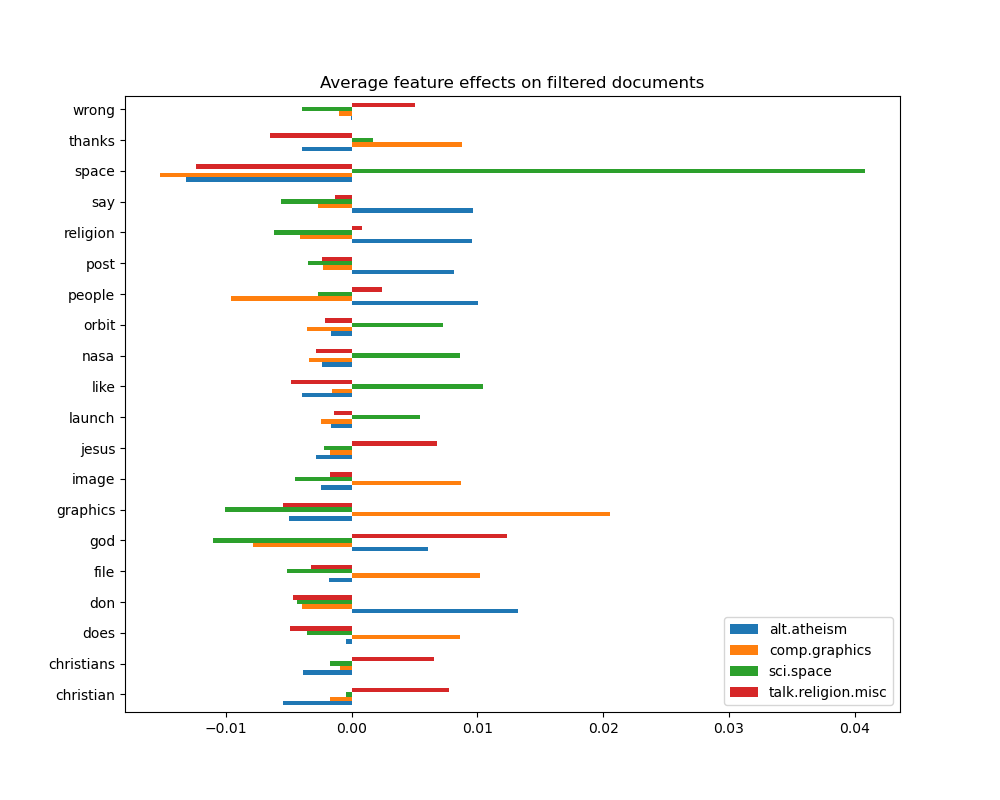
top 5 keywords per class:
alt.atheism comp.graphics sci.space talk.religion.misc
0 don graphics space god
1 people file like christian
2 say thanks nasa jesus
3 religion image orbit christians
4 post does launch wrong
在下一节中,我们将保留不含元数据的数据集,以比较多个分类器。
基准测试分类器#
Scikit-learn 提供了许多不同类型的分类算法。在本节中,我们将针对相同的文本分类问题训练其中一些分类器,并测量它们的泛化性能(测试集上的准确性)和计算性能(速度),包括训练时间和测试时间。为此,我们定义了以下基准测试工具
from sklearn import metrics
from sklearn.utils.extmath import density
def benchmark(clf, custom_name=False):
print("_" * 80)
print("Training: ")
print(clf)
t0 = time()
clf.fit(X_train, y_train)
train_time = time() - t0
print(f"train time: {train_time:.3}s")
t0 = time()
pred = clf.predict(X_test)
test_time = time() - t0
print(f"test time: {test_time:.3}s")
score = metrics.accuracy_score(y_test, pred)
print(f"accuracy: {score:.3}")
if hasattr(clf, "coef_"):
print(f"dimensionality: {clf.coef_.shape[1]}")
print(f"density: {density(clf.coef_)}")
print()
print()
if custom_name:
clf_descr = str(custom_name)
else:
clf_descr = clf.__class__.__name__
return clf_descr, score, train_time, test_time
我们现在使用 8 种不同的分类模型训练和测试数据集,并获得每个模型的性能结果。本研究的目标是突出显示不同类型分类器在此类多类别文本分类问题中的计算/准确性权衡。
请注意,最重要的超参数值是使用网格搜索过程进行调优的,为简化起见,本笔记本中未显示此过程。有关如何进行此类调优的演示,请参阅示例脚本 文本特征提取和评估的示例管道 # noqa: E501。
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression, SGDClassifier
from sklearn.naive_bayes import ComplementNB
from sklearn.neighbors import KNeighborsClassifier, NearestCentroid
from sklearn.svm import LinearSVC
results = []
for clf, name in (
(LogisticRegression(C=5, max_iter=1000), "Logistic Regression"),
(RidgeClassifier(alpha=1.0, solver="sparse_cg"), "Ridge Classifier"),
(KNeighborsClassifier(n_neighbors=100), "kNN"),
(RandomForestClassifier(), "Random Forest"),
# L2 penalty Linear SVC
(LinearSVC(C=0.1, dual=False, max_iter=1000), "Linear SVC"),
# L2 penalty Linear SGD
(
SGDClassifier(
loss="log_loss", alpha=1e-4, n_iter_no_change=3, early_stopping=True
),
"log-loss SGD",
),
# NearestCentroid (aka Rocchio classifier)
(NearestCentroid(), "NearestCentroid"),
# Sparse naive Bayes classifier
(ComplementNB(alpha=0.1), "Complement naive Bayes"),
):
print("=" * 80)
print(name)
results.append(benchmark(clf, name))
================================================================================
Logistic Regression
________________________________________________________________________________
Training:
LogisticRegression(C=5, max_iter=1000)
train time: 0.157s
test time: 0.000566s
accuracy: 0.772
dimensionality: 5316
density: 1.0
================================================================================
Ridge Classifier
________________________________________________________________________________
Training:
RidgeClassifier(solver='sparse_cg')
train time: 0.0318s
test time: 0.000492s
accuracy: 0.76
dimensionality: 5316
density: 1.0
================================================================================
kNN
________________________________________________________________________________
Training:
KNeighborsClassifier(n_neighbors=100)
train time: 0.00077s
test time: 0.0644s
accuracy: 0.752
================================================================================
Random Forest
________________________________________________________________________________
Training:
RandomForestClassifier()
train time: 1.58s
test time: 0.0516s
accuracy: 0.7
================================================================================
Linear SVC
________________________________________________________________________________
Training:
LinearSVC(C=0.1, dual=False)
train time: 0.0276s
test time: 0.000478s
accuracy: 0.752
dimensionality: 5316
density: 1.0
================================================================================
log-loss SGD
________________________________________________________________________________
Training:
SGDClassifier(early_stopping=True, loss='log_loss', n_iter_no_change=3)
train time: 0.0287s
test time: 0.000526s
accuracy: 0.764
dimensionality: 5316
density: 1.0
================================================================================
NearestCentroid
________________________________________________________________________________
Training:
NearestCentroid()
train time: 0.159s
test time: 0.00159s
accuracy: 0.748
================================================================================
Complement naive Bayes
________________________________________________________________________________
Training:
ComplementNB(alpha=0.1)
train time: 0.00191s
test time: 0.000477s
accuracy: 0.779
绘制每个分类器的准确性、训练时间和测试时间#
散点图显示了每个分类器的测试准确性与训练和测试时间之间的权衡。
indices = np.arange(len(results))
results = [[x[i] for x in results] for i in range(4)]
clf_names, score, training_time, test_time = results
training_time = np.array(training_time)
test_time = np.array(test_time)
fig, ax1 = plt.subplots(figsize=(10, 8))
ax1.scatter(score, training_time, s=60)
ax1.set(
title="Score-training time trade-off",
yscale="log",
xlabel="test accuracy",
ylabel="training time (s)",
)
fig, ax2 = plt.subplots(figsize=(10, 8))
ax2.scatter(score, test_time, s=60)
ax2.set(
title="Score-test time trade-off",
yscale="log",
xlabel="test accuracy",
ylabel="test time (s)",
)
for i, txt in enumerate(clf_names):
ax1.annotate(txt, (score[i], training_time[i]))
ax2.annotate(txt, (score[i], test_time[i]))
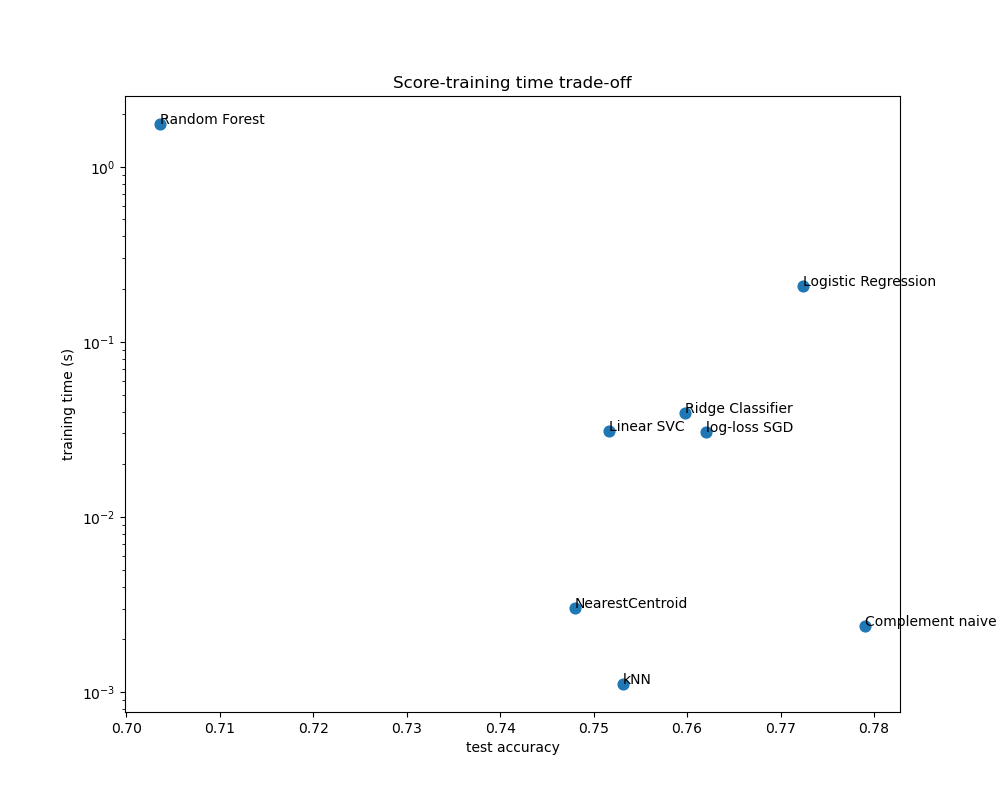
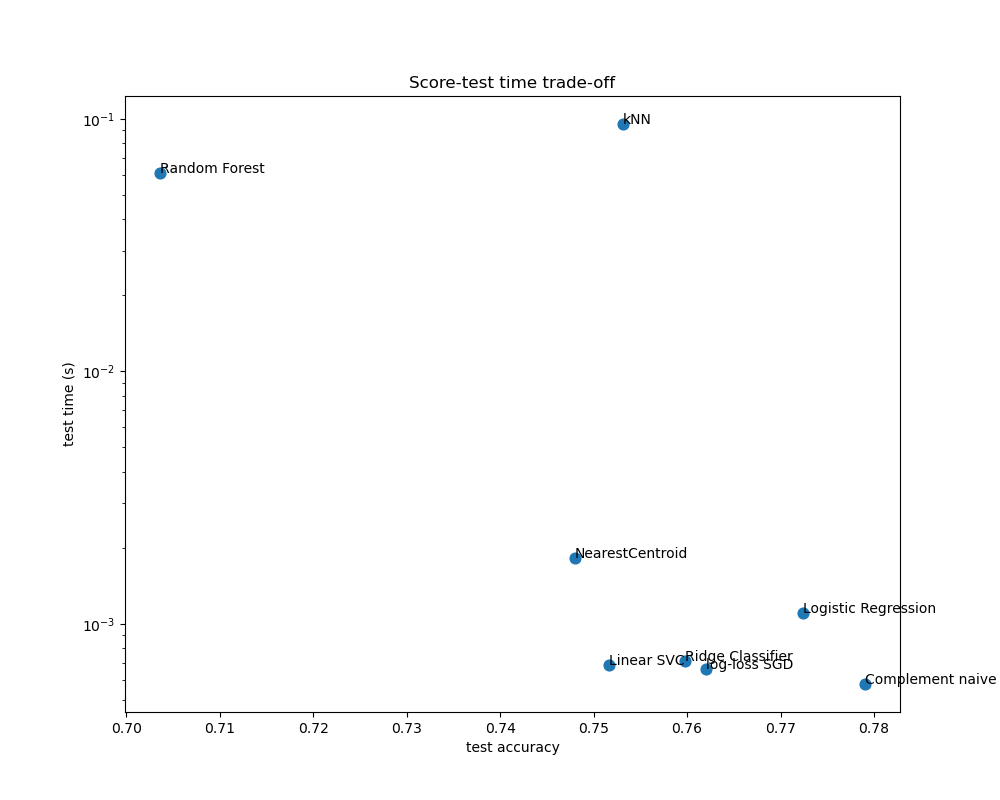
朴素贝叶斯模型在分数和训练/测试时间之间具有最佳权衡,而随机森林训练慢、预测成本高,并且准确性相对较差。这是预期的:对于高维预测问题,线性模型通常更适用,因为当特征空间具有 10,000 维或更多时,大多数问题会变得线性可分。
线性模型训练速度和准确性的差异可以通过它们优化的损失函数和使用的正则化类型来解释。请注意,一些具有相同损失但不同求解器或正则化配置的线性模型可能会产生不同的拟合时间和测试准确性。我们可以在第二张图上观察到,一旦训练完成,所有线性模型的预测速度都大致相同,这是预期的,因为它们都实现了相同的预测函数。
KNeighborsClassifier 准确率相对较低,并且测试时间最长。长的预测时间也是预期的:对于每次预测,模型必须计算测试样本与训练集中每个文档之间的成对距离,这在计算上是昂贵的。此外,“维度灾难”损害了该模型在文本分类问题的高维特征空间中产生有竞争力准确率的能力。
脚本总运行时间:(0 分 6.520 秒)
相关示例