注意
转到末尾以下载完整示例代码,或通过 JupyterLite 或 Binder 在浏览器中运行此示例。
在手写数字数据上演示 K-Means 聚类#
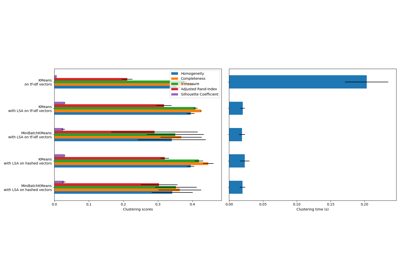
在此示例中,我们比较了 K-means 的各种初始化策略在运行时间和结果质量方面的表现。
由于此处的真实标签已知,我们还应用了不同的聚类质量指标来判断聚类标签与真实标签的拟合优度。
评估的聚类质量指标(有关指标的定义和讨论,请参见聚类性能评估)
缩写 |
全名 |
|---|---|
homo |
同质性分数 (homogeneity score) |
compl |
完整性分数 (completeness score) |
v-meas |
V 度量 (V measure) |
ARI |
调整兰德指数 (adjusted Rand index) |
AMI |
调整互信息 (adjusted mutual information) |
silhouette |
轮廓系数 (silhouette coefficient) |
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
加载数据集#
我们将从加载 digits 数据集开始。该数据集包含从 0 到 9 的手写数字。在聚类上下文中,人们希望将图像分组,使得图像上的手写数字相同。
import numpy as np
from sklearn.datasets import load_digits
data, labels = load_digits(return_X_y=True)
(n_samples, n_features), n_digits = data.shape, np.unique(labels).size
print(f"# digits: {n_digits}; # samples: {n_samples}; # features {n_features}")
# digits: 10; # samples: 1797; # features 64
定义我们的评估基准#
我们将首先定义我们的评估基准。在此基准测试中,我们打算比较 KMeans 的不同初始化方法。我们的基准将:
创建一个管道,使用
StandardScaler对数据进行缩放;训练并计时管道拟合过程;
通过不同的指标衡量获得的聚类性能。
from time import time
from sklearn import metrics
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
def bench_k_means(kmeans, name, data, labels):
"""Benchmark to evaluate the KMeans initialization methods.
Parameters
----------
kmeans : KMeans instance
A :class:`~sklearn.cluster.KMeans` instance with the initialization
already set.
name : str
Name given to the strategy. It will be used to show the results in a
table.
data : ndarray of shape (n_samples, n_features)
The data to cluster.
labels : ndarray of shape (n_samples,)
The labels used to compute the clustering metrics which requires some
supervision.
"""
t0 = time()
estimator = make_pipeline(StandardScaler(), kmeans).fit(data)
fit_time = time() - t0
results = [name, fit_time, estimator[-1].inertia_]
# Define the metrics which require only the true labels and estimator
# labels
clustering_metrics = [
metrics.homogeneity_score,
metrics.completeness_score,
metrics.v_measure_score,
metrics.adjusted_rand_score,
metrics.adjusted_mutual_info_score,
]
results += [m(labels, estimator[-1].labels_) for m in clustering_metrics]
# The silhouette score requires the full dataset
results += [
metrics.silhouette_score(
data,
estimator[-1].labels_,
metric="euclidean",
sample_size=300,
)
]
# Show the results
formatter_result = (
"{:9s}\t{:.3f}s\t{:.0f}\t{:.3f}\t{:.3f}\t{:.3f}\t{:.3f}\t{:.3f}\t{:.3f}"
)
print(formatter_result.format(*results))
运行基准测试#
我们将比较三种方法:
使用
k-means++进行初始化。该方法是随机的,我们将运行初始化 4 次;随机初始化。该方法也是随机的,我们将运行初始化 4 次;
基于
PCA投影的初始化。具体来说,我们将使用PCA的主成分来初始化 KMeans。该方法是确定性的,一次初始化就足够了。
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
print(82 * "_")
print("init\t\ttime\tinertia\thomo\tcompl\tv-meas\tARI\tAMI\tsilhouette")
kmeans = KMeans(init="k-means++", n_clusters=n_digits, n_init=4, random_state=0)
bench_k_means(kmeans=kmeans, name="k-means++", data=data, labels=labels)
kmeans = KMeans(init="random", n_clusters=n_digits, n_init=4, random_state=0)
bench_k_means(kmeans=kmeans, name="random", data=data, labels=labels)
pca = PCA(n_components=n_digits).fit(data)
kmeans = KMeans(init=pca.components_, n_clusters=n_digits, n_init=1)
bench_k_means(kmeans=kmeans, name="PCA-based", data=data, labels=labels)
print(82 * "_")
__________________________________________________________________________________
init time inertia homo compl v-meas ARI AMI silhouette
k-means++ 0.033s 69545 0.598 0.645 0.621 0.469 0.617 0.158
random 0.038s 69735 0.681 0.723 0.701 0.574 0.698 0.173
PCA-based 0.014s 69513 0.600 0.647 0.622 0.468 0.618 0.162
__________________________________________________________________________________
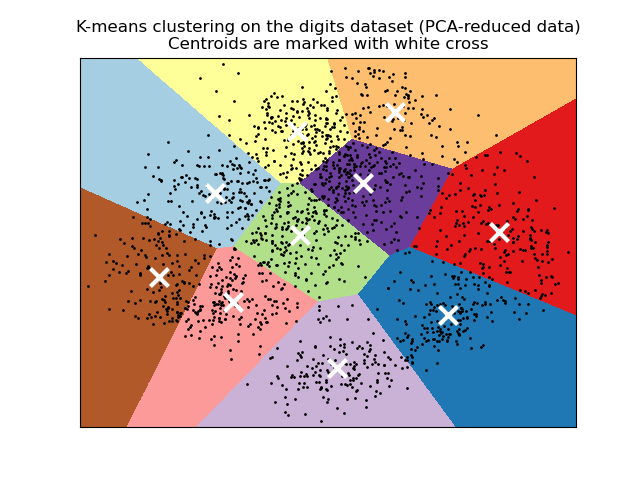
在 PCA 降维数据上可视化结果#
PCA 允许将数据从原始的 64 维空间投影到较低维空间。随后,我们可以使用 PCA 投影到 2 维空间,并在新空间中绘制数据和聚类。
import matplotlib.pyplot as plt
reduced_data = PCA(n_components=2).fit_transform(data)
kmeans = KMeans(init="k-means++", n_clusters=n_digits, n_init=4)
kmeans.fit(reduced_data)
# Step size of the mesh. Decrease to increase the quality of the VQ.
h = 0.02 # point in the mesh [x_min, x_max]x[y_min, y_max].
# Plot the decision boundary. For that, we will assign a color to each
x_min, x_max = reduced_data[:, 0].min() - 1, reduced_data[:, 0].max() + 1
y_min, y_max = reduced_data[:, 1].min() - 1, reduced_data[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Obtain labels for each point in mesh. Use last trained model.
Z = kmeans.predict(np.c_[xx.ravel(), yy.ravel()])
# Put the result into a color plot
Z = Z.reshape(xx.shape)
plt.figure(1)
plt.clf()
plt.imshow(
Z,
interpolation="nearest",
extent=(xx.min(), xx.max(), yy.min(), yy.max()),
cmap=plt.cm.Paired,
aspect="auto",
origin="lower",
)
plt.plot(reduced_data[:, 0], reduced_data[:, 1], "k.", markersize=2)
# Plot the centroids as a white X
centroids = kmeans.cluster_centers_
plt.scatter(
centroids[:, 0],
centroids[:, 1],
marker="x",
s=169,
linewidths=3,
color="w",
zorder=10,
)
plt.title(
"K-means clustering on the digits dataset (PCA-reduced data)\n"
"Centroids are marked with white cross"
)
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.xticks(())
plt.yticks(())
plt.show()
脚本总运行时间: (0 分钟 4.309 秒)
相关示例