注意
转到末尾以下载完整示例代码,或通过 JupyterLite 或 Binder 在浏览器中运行此示例
精确率-召回率#
精确率-召回率指标用于评估分类器输出质量的示例。
当类别非常不平衡时,精确率-召回率是衡量预测成功程度的有用指标。在信息检索中,精确率衡量实际返回的项目中相关项目的比例,而召回率衡量所有应该返回的项目中已返回项目的比例。这里的“相关性”指的是被正向标记的项目,即真阳性(true positives)和假阴性(false negatives)。
精确率(\(P\))定义为真阳性(\(T_p\))的数量除以真阳性数量加上假阳性(\(F_p\))数量。
召回率(\(R\))定义为真阳性(\(T_p\))的数量除以真阳性数量加上假阴性(\(F_n\))数量。
精确率-召回率曲线显示了不同阈值下精确率和召回率之间的权衡。曲线下的高面积表示高召回率和高精确率。通过在返回结果中减少假阳性来达到高精确率,通过在相关结果中减少假阴性来达到高召回率。两者都得分高表明分类器返回的结果既准确(高精确率),又返回了大多数相关结果(高召回率)。
召回率高但精确率低的系统会返回大多数相关项目,但返回结果中错误标记的比例很高。精确率高但召回率低的系统则恰恰相反,它返回的相关项目很少,但其预测的大部分标签与实际标签相比是正确的。一个理想的精确率和召回率都高的系统将返回大多数相关项目,并且大多数结果标记正确。
精确率(\(\frac{T_p}{T_p + F_p}\))的定义表明,降低分类器的阈值可能会通过增加返回结果的数量来增加分母。如果之前的阈值设置过高,新的结果可能都是真阳性,这将提高精确率。如果之前的阈值设置得恰到好处或过低,进一步降低阈值将引入假阳性,从而降低精确率。
召回率定义为 \(\frac{T_p}{T_p+F_n}\),其中 \(T_p+F_n\) 不依赖于分类器阈值。改变分类器阈值只能改变分子 \(T_p\)。降低分类器阈值可能会通过增加真阳性结果的数量来提高召回率。也有可能降低阈值会使召回率保持不变,而精确率波动。因此,精确率不一定随召回率的降低而降低。
召回率和精确率之间的关系可以在图表的阶梯区域中观察到——在这些阶梯的边缘,阈值的微小变化会显著降低精确率,而召回率仅有微小的提升。
**平均精确率** (AP) 将此类图表总结为每个阈值下获得的精确率的加权平均值,其中权重是与前一阈值相比召回率的增加量
\(\text{AP} = \sum_n (R_n - R_{n-1}) P_n\)
其中 \(P_n\) 和 \(R_n\) 分别是第 n 个阈值下的精确率和召回率。一对 \((R_k, P_k)\) 被称为一个 工作点。
AP 和工作点下的梯形面积(sklearn.metrics.auc)是总结精确率-召回率曲线的常用方法,它们会产生不同的结果。请在用户指南中阅读更多内容。
精确率-召回率曲线通常用于二分类中,以研究分类器的输出。为了将精确率-召回率曲线和平均精确率扩展到多类别或多标签分类,需要对输出进行二值化。可以为每个标签绘制一条曲线,也可以将标签指示矩阵的每个元素视为二元预测来绘制精确率-召回率曲线(微平均)。
注意
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
在二分类设置中#
数据集和模型#
我们将使用 Linear SVC 分类器来区分两种鸢尾花。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
X, y = load_iris(return_X_y=True)
# Add noisy features
random_state = np.random.RandomState(0)
n_samples, n_features = X.shape
X = np.concatenate([X, random_state.randn(n_samples, 200 * n_features)], axis=1)
# Limit to the two first classes, and split into training and test
X_train, X_test, y_train, y_test = train_test_split(
X[y < 2], y[y < 2], test_size=0.5, random_state=random_state
)
Linear SVC 要求每个特征具有相似的值范围。因此,我们将首先使用 StandardScaler 对数据进行缩放。
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
classifier = make_pipeline(StandardScaler(), LinearSVC(random_state=random_state))
classifier.fit(X_train, y_train)
绘制精确率-召回率曲线#
要绘制精确率-召回率曲线,应使用 PrecisionRecallDisplay。实际上,根据您是否已计算分类器的预测结果,有两种可用方法。
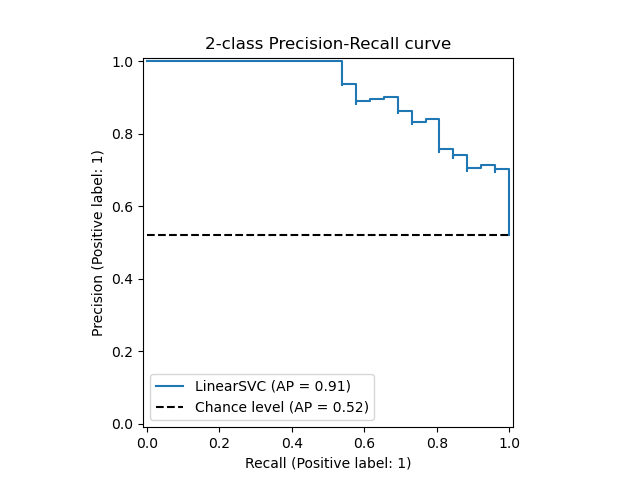
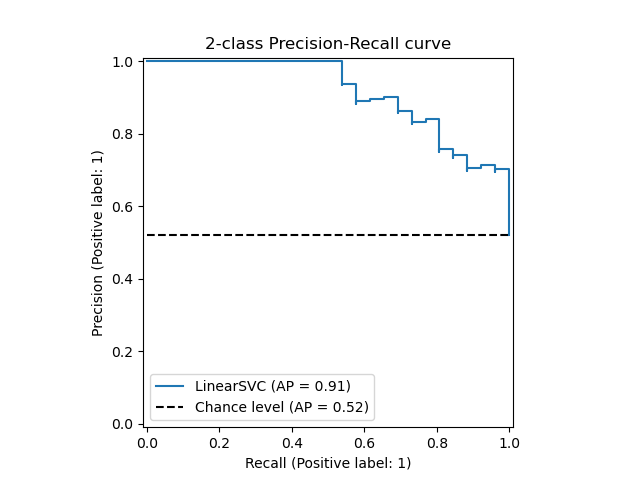
让我们首先绘制没有分类器预测结果的精确率-召回率曲线。我们使用 from_estimator,它会在绘图前为我们计算预测结果。
from sklearn.metrics import PrecisionRecallDisplay
display = PrecisionRecallDisplay.from_estimator(
classifier, X_test, y_test, name="LinearSVC", plot_chance_level=True, despine=True
)
_ = display.ax_.set_title("2-class Precision-Recall curve")
如果我们已经获得了模型的估计概率或分数,那么我们可以使用 from_predictions。
y_score = classifier.decision_function(X_test)
display = PrecisionRecallDisplay.from_predictions(
y_test, y_score, name="LinearSVC", plot_chance_level=True, despine=True
)
_ = display.ax_.set_title("2-class Precision-Recall curve")
在多标签设置中#
精确率-召回率曲线不支持多标签设置。但是,可以决定如何处理这种情况。下面我们将展示一个这样的示例。
创建多标签数据,拟合并预测#
我们创建一个多标签数据集,以说明多标签设置中的精确率-召回率。
from sklearn.preprocessing import label_binarize
# Use label_binarize to be multi-label like settings
Y = label_binarize(y, classes=[0, 1, 2])
n_classes = Y.shape[1]
# Split into training and test
X_train, X_test, Y_train, Y_test = train_test_split(
X, Y, test_size=0.5, random_state=random_state
)
我们使用 OneVsRestClassifier 进行多标签预测。
from sklearn.multiclass import OneVsRestClassifier
classifier = OneVsRestClassifier(
make_pipeline(StandardScaler(), LinearSVC(random_state=random_state))
)
classifier.fit(X_train, Y_train)
y_score = classifier.decision_function(X_test)
多标签设置中的平均精确率得分#
from sklearn.metrics import average_precision_score, precision_recall_curve
# For each class
precision = dict()
recall = dict()
average_precision = dict()
for i in range(n_classes):
precision[i], recall[i], _ = precision_recall_curve(Y_test[:, i], y_score[:, i])
average_precision[i] = average_precision_score(Y_test[:, i], y_score[:, i])
# A "micro-average": quantifying score on all classes jointly
precision["micro"], recall["micro"], _ = precision_recall_curve(
Y_test.ravel(), y_score.ravel()
)
average_precision["micro"] = average_precision_score(Y_test, y_score, average="micro")
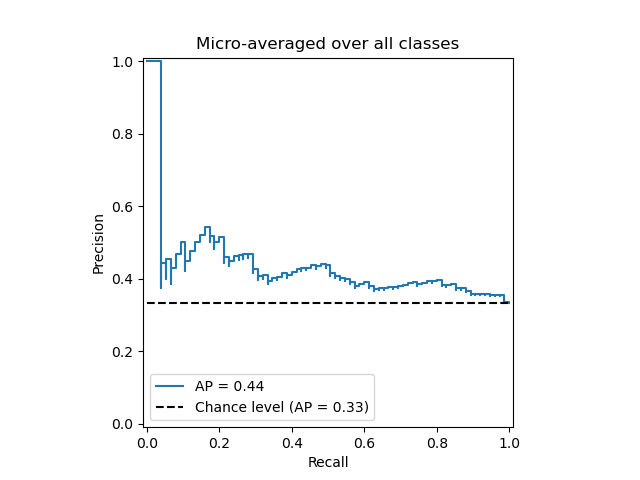
绘制微平均精确率-召回率曲线#
from collections import Counter
display = PrecisionRecallDisplay(
recall=recall["micro"],
precision=precision["micro"],
average_precision=average_precision["micro"],
prevalence_pos_label=Counter(Y_test.ravel())[1] / Y_test.size,
)
display.plot(plot_chance_level=True, despine=True)
_ = display.ax_.set_title("Micro-averaged over all classes")
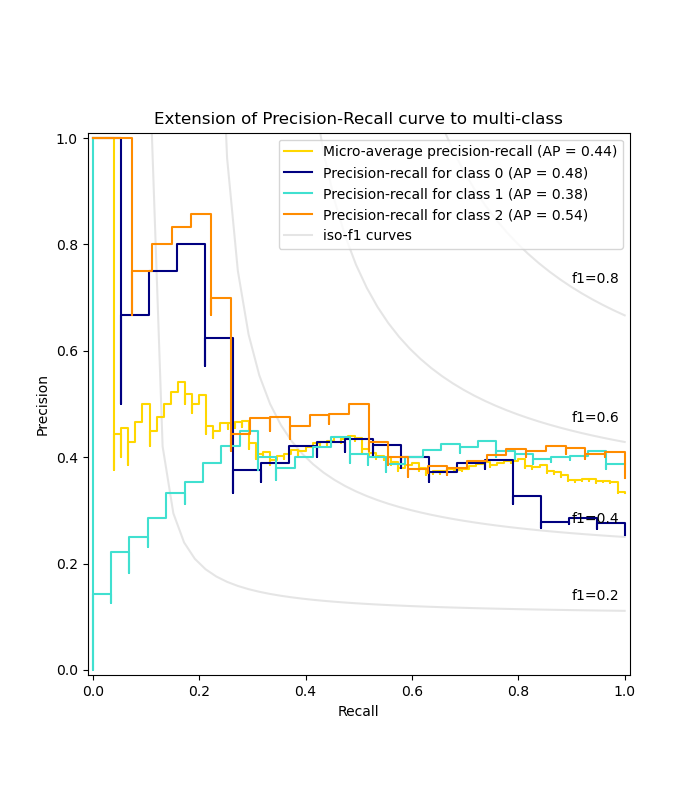
为每个类别和 iso-f1 曲线绘制精确率-召回率曲线#
from itertools import cycle
import matplotlib.pyplot as plt
# setup plot details
colors = cycle(["navy", "turquoise", "darkorange", "cornflowerblue", "teal"])
_, ax = plt.subplots(figsize=(7, 8))
f_scores = np.linspace(0.2, 0.8, num=4)
lines, labels = [], []
for f_score in f_scores:
x = np.linspace(0.01, 1)
y = f_score * x / (2 * x - f_score)
(l,) = plt.plot(x[y >= 0], y[y >= 0], color="gray", alpha=0.2)
plt.annotate("f1={0:0.1f}".format(f_score), xy=(0.9, y[45] + 0.02))
display = PrecisionRecallDisplay(
recall=recall["micro"],
precision=precision["micro"],
average_precision=average_precision["micro"],
)
display.plot(ax=ax, name="Micro-average precision-recall", color="gold")
for i, color in zip(range(n_classes), colors):
display = PrecisionRecallDisplay(
recall=recall[i],
precision=precision[i],
average_precision=average_precision[i],
)
display.plot(
ax=ax, name=f"Precision-recall for class {i}", color=color, despine=True
)
# add the legend for the iso-f1 curves
handles, labels = display.ax_.get_legend_handles_labels()
handles.extend([l])
labels.extend(["iso-f1 curves"])
# set the legend and the axes
ax.legend(handles=handles, labels=labels, loc="best")
ax.set_title("Extension of Precision-Recall curve to multi-class")
plt.show()
**脚本总运行时间:** (0 分钟 0.364 秒)
相关示例