注意
转到末尾以下载完整示例代码或通过 JupyterLite 或 Binder 在浏览器中运行此示例。
scikit-learn 1.7 发布亮点#
我们很高兴地宣布 scikit-learn 1.7 发布!其中添加了许多错误修复和改进,以及一些关键的新功能。下面我们详细介绍本次发布的亮点。有关所有更改的详尽列表,请参阅发布说明。
要安装最新版本(使用 pip)
pip install --upgrade scikit-learn
或使用 conda
conda install -c conda-forge scikit-learn
改进的估计器 HTML 表示#
估计器的 HTML 表示现在包含一个包含参数列表及其值的章节。非默认参数以橙色突出显示。还提供了一个复制按钮,无需调用get_params方法即可复制“完全限定”参数名称。当为具有复杂管道的网格搜索或随机搜索定义参数网格时,它特别有用。
请参阅下面的示例,然后单击不同的估计器块以查看改进的 HTML 表示。
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
model = make_pipeline(StandardScaler(with_std=False), LogisticRegression(C=2.0))
model
基于直方图的梯度提升估计器的自定义验证集#
ensemble.HistGradientBoostingClassifier 和 ensemble.HistGradientBoostingRegressor 现在支持使用 X_val、y_val 和 sample_weight_val 参数直接向 fit 方法传递用于提前停止的自定义验证集。在 pipeline.Pipeline 中,可以使用 transform_input 参数将验证集 X_val 与 X 一起转换。
import sklearn
from sklearn.datasets import make_classification
from sklearn.ensemble import HistGradientBoostingClassifier
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
sklearn.set_config(enable_metadata_routing=True)
X, y = make_classification(random_state=0)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=0)
clf = HistGradientBoostingClassifier()
clf.set_fit_request(X_val=True, y_val=True)
model = Pipeline([("sc", StandardScaler()), ("clf", clf)], transform_input=["X_val"])
model.fit(X, y, X_val=X_val, y_val=y_val)
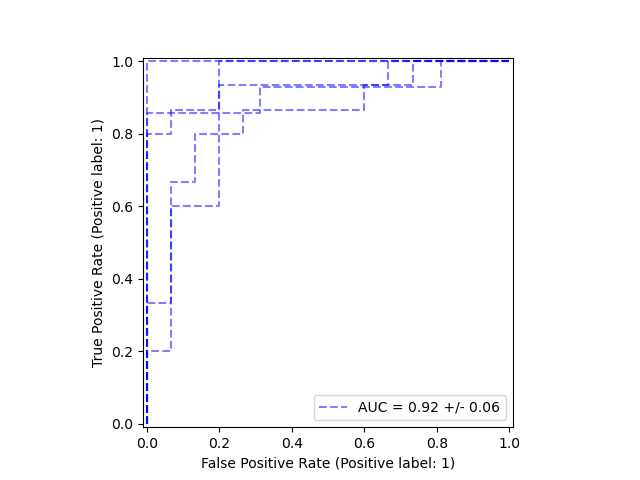
从交叉验证结果中绘制 ROC 曲线#
类 metrics.RocCurveDisplay 有一个新的类方法 from_cv_results,允许从 model_selection.cross_validate 的结果中轻松绘制多个 ROC 曲线。
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import RocCurveDisplay
from sklearn.model_selection import cross_validate
X, y = make_classification(n_samples=150, random_state=0)
clf = LogisticRegression(random_state=0)
cv_results = cross_validate(clf, X, y, cv=5, return_estimator=True, return_indices=True)
_ = RocCurveDisplay.from_cv_results(cv_results, X, y)
Array API 支持#
自版本 1.6 以来,一些函数已更新以支持与 array API 兼容的输入,特别是来自 sklearn.metrics 模块的指标。
此外,不再需要安装 array-api-compat 包即可使用 scikit-learn 中的实验性 array API 支持。
请参阅 array API support 页面,了解如何将 scikit-learn 与 PyTorch 或 CuPy 等 array API 兼容库一起使用的说明。
改进多层感知器的 API 一致性#
neural_network.MLPRegressor 有一个新参数 loss,现在除了默认的“squared_error”损失之外还支持“poisson”损失。此外,neural_network.MLPClassifier 和 neural_network.MLPRegressor 估计器现在支持样本权重。进行这些改进是为了提高这些估计器与 scikit-learn 中其他估计器的一致性。
向稀疏数组迁移#
为了准备 SciPy 从稀疏矩阵向稀疏数组迁移,所有接受稀疏矩阵作为输入的 scikit-learn 估计器现在也接受稀疏数组。
脚本总运行时间: (0 minutes 0.131 seconds)
相关示例