注意
转到末尾以下载完整示例代码或通过 JupyterLite 或 Binder 在浏览器中运行此示例。
scikit-learn 1.8 发布亮点#
我们很高兴地宣布 scikit-learn 1.8 发布!新增了许多错误修复和改进,以及一些关键的新功能。下面我们详细介绍了本次发布的亮点。有关所有更改的详尽列表,请参阅发布说明。
要安装最新版本(使用 pip)
pip install --upgrade scikit-learn
或使用 conda
conda install -c conda-forge scikit-learn
Array API 支持(启用 GPU 计算)#
scikit-learn 中逐步采用 Python array API 标准意味着可以直接使用 PyTorch 和 CuPy 输入数组。这意味着在 scikit-learn 估计器和函数中,非 CPU 设备(例如 GPU)可用于执行计算。因此,性能得到改善,并且与这些库的集成更加容易。
在 scikit-learn 1.8 中,一些估计器和函数已更新以支持 array API 兼容输入,例如 PyTorch 张量和 CuPy 数组。
以下估计器添加了 Array API 支持:preprocessing.StandardScaler、preprocessing.PolynomialFeatures、linear_model.RidgeCV、linear_model.RidgeClassifierCV、mixture.GaussianMixture 和 calibration.CalibratedClassifierCV。
Array API 支持也已添加到 sklearn.metrics 模块中的多个指标,有关更多详细信息,请参阅支持 Array API 兼容输入。
有关使用 scikit-learn 和 PyTorch 或 CuPy 等 array API 兼容库的说明,请参阅array API 支持页面。注意:Array API 支持是实验性的,必须在 SciPy 和 scikit-learn 中显式启用。
下面是使用 PyTorch 在 CPU 上使用特征工程预处理器,然后将 calibration.CalibratedClassifierCV 和 linear_model.RidgeCV 一起在 GPU 上使用的摘录
ridge_pipeline_gpu = make_pipeline(
# Ensure that all features (including categorical features) are preprocessed
# on the CPU and mapped to a numerical representation.
feature_preprocessor,
# Move the results to the GPU and perform computations there
FunctionTransformer(
lambda x: torch.tensor(x.to_numpy().astype(np.float32), device="cuda"))
,
CalibratedClassifierCV(
RidgeClassifierCV(alphas=alphas), method="temperature"
),
)
with sklearn.config_context(array_api_dispatch=True):
cv_results = cross_validate(ridge_pipeline_gpu, features, target)
有关更多详细信息,请参阅 Google Colab 上的完整笔记本。在这个特定示例中,使用 Colab GPU 与使用单个 CPU 核心相比,速度提高了 10 倍,这对于此类工作负载来说非常典型。
支持自由线程 CPython 3.14#
scikit-learn 支持自由线程 CPython,特别是对于 Python 3.14 上所有受支持的平台,均提供自由线程 wheel。
我们非常希望得到用户反馈。您可以尝试以下几项:
安装自由线程 CPython 3.14,运行您喜欢的 scikit-learn 脚本并检查是否没有意外中断。请注意,强烈建议使用 CPython 3.14(而不是 3.13),因为自 CPython 3.13 以来已修复了许多自由线程错误。
如果您使用带
n_jobs参数的估计器,请尝试使用joblib.parallel_config将默认后端更改为线程,如以下代码片段所示。这可能会加快您的代码速度,因为默认的 joblib 后端是基于进程的,并且比线程产生更多的开销。grid_search = GridSearchCV(clf, param_grid=param_grid, n_jobs=4) with joblib.parallel_config(backend="threading"): grid_search.fit(X, y)
请通过打开 GitHub issue 毫不犹豫地报告任何问题或意外的性能行为!
自由线程(也称为 nogil)CPython 是 CPython 的一个版本,旨在通过删除全局解释器锁 (GIL) 来实现高效的多线程用例。
有关自由线程 CPython 的更多详细信息,请参阅 py-free-threading doc,特别是如何安装自由线程 CPython 和 生态系统兼容性跟踪。
在 scikit-learn 中,对于自由线程 Python,希望通过在函数或估计器中传递 n_jobs>1 时使用线程工作器而不是子进程工作器进行并行计算,从而更有效地利用多核 CPU。通过消除对进程间通信的需求,有望提高效率。请注意,切换默认的 joblib 后端并测试所有功能在自由线程 Python 中是否正常运行是一项正在进行的长期努力。
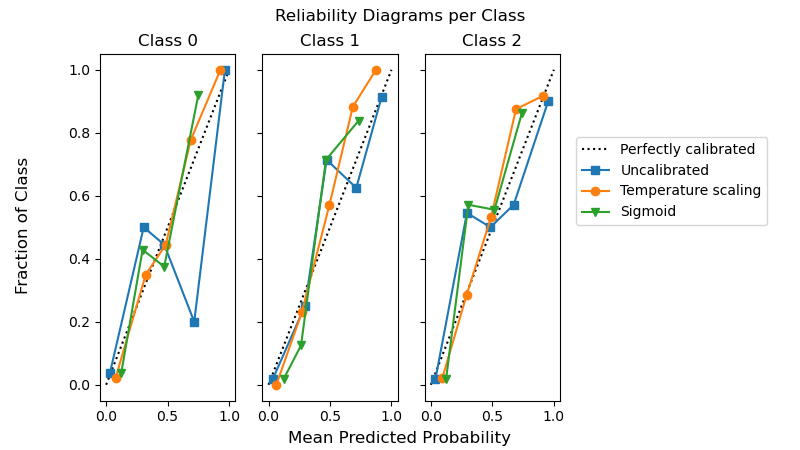
CalibratedClassifierCV 中的温度缩放#
通过设置 method="temperature",可以在 calibration.CalibratedClassifierCV 中使用温度缩放对分类器进行概率校准。此方法特别适用于多类问题,因为它使用单个自由参数提供(更好)校准的概率。这与所有其他可用的校准方法形成对比,后者使用“一对多”方案,为每个类添加更多参数。
from sklearn.calibration import CalibratedClassifierCV
from sklearn.datasets import make_classification
from sklearn.naive_bayes import GaussianNB
X, y = make_classification(n_classes=3, n_informative=8, random_state=42)
clf = GaussianNB().fit(X, y)
sig = CalibratedClassifierCV(clf, method="sigmoid", ensemble=False).fit(X, y)
ts = CalibratedClassifierCV(clf, method="temperature", ensemble=False).fit(X, y)
以下示例显示,在具有 3 个类的多类分类问题中,温度缩放可以产生比 sigmoid 校准更好的校准概率。
import matplotlib.pyplot as plt
from sklearn.calibration import CalibrationDisplay
fig, axes = plt.subplots(
figsize=(8, 4.5),
ncols=3,
sharey=True,
)
for i, c in enumerate(ts.classes_):
CalibrationDisplay.from_predictions(
y == c, clf.predict_proba(X)[:, i], name="Uncalibrated", ax=axes[i], marker="s"
)
CalibrationDisplay.from_predictions(
y == c,
ts.predict_proba(X)[:, i],
name="Temperature scaling",
ax=axes[i],
marker="o",
)
CalibrationDisplay.from_predictions(
y == c, sig.predict_proba(X)[:, i], name="Sigmoid", ax=axes[i], marker="v"
)
axes[i].set_title(f"Class {c}")
axes[i].set_xlabel(None)
axes[i].set_ylabel(None)
axes[i].get_legend().remove()
fig.suptitle("Reliability Diagrams per Class")
fig.supxlabel("Mean Predicted Probability")
fig.supylabel("Fraction of Class")
fig.legend(*axes[0].get_legend_handles_labels(), loc=(0.72, 0.5))
plt.subplots_adjust(right=0.7)
_ = fig.show()
线性模型中的效率改进#
对于基于平方误差且带有 L1 惩罚的估计器,拟合时间已大大减少:ElasticNet、Lasso、MultiTaskElasticNet、MultiTaskLasso 及其 CV 变体。拟合时间改进主要通过安全间隙筛选规则实现。它们使坐标下降求解器能够尽早将特征系数设置为零,并且不再查看它们。L1 惩罚越强,特征就可以越早地从进一步更新中排除。
from time import time
from sklearn.datasets import make_regression
from sklearn.linear_model import ElasticNetCV
X, y = make_regression(n_features=10_000, random_state=0)
model = ElasticNetCV()
tic = time()
model.fit(X, y)
toc = time()
print(f"Fitting ElasticNetCV took {toc - tic:.3} seconds.")
Fitting ElasticNetCV took 12.9 seconds.
估计器的 HTML 表示#
HTML 表示的下拉表格中的超参数现在包含指向在线文档的链接。将鼠标悬停在上面时,文档字符串描述也会显示为工具提示。
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
clf = make_pipeline(StandardScaler(), LogisticRegression(random_state=0, C=10))
通过点击“LogisticRegression”然后点击“Parameters”来展开下面的估计器图。
clf
带有 criterion="absolute_error" 的 DecisionTreeRegressor#
带有 criterion="absolute_error" 的 tree.DecisionTreeRegressor 现在运行速度快得多。现在它具有 O(n * log(n)) 复杂度,而之前是 O(n**2),这使得它可以扩展到数百万个数据点。
作为一个例证,在包含 100,000 个样本和 1 个特征的数据集上,进行一次拆分大约需要 100 毫秒,而之前需要约 20 秒。
import time
from sklearn.datasets import make_regression
from sklearn.tree import DecisionTreeRegressor
X, y = make_regression(n_samples=100_000, n_features=1)
tree = DecisionTreeRegressor(criterion="absolute_error", max_depth=1)
tic = time.time()
tree.fit(X, y)
elapsed = time.time() - tic
print(f"Fit took {elapsed:.2f} seconds")
Fit took 0.13 seconds
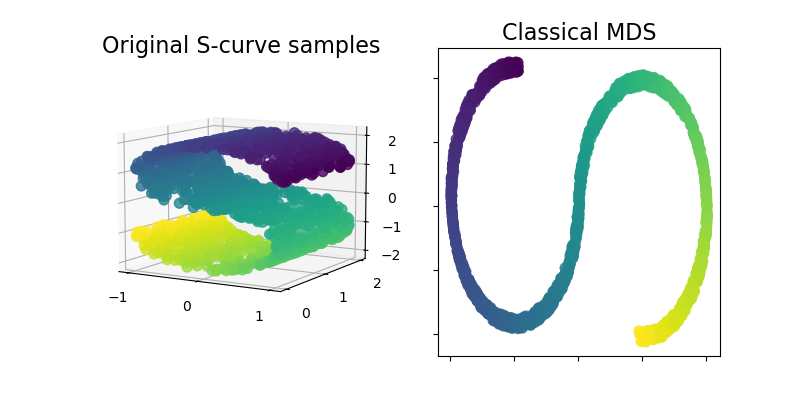
ClassicalMDS#
Classical MDS,也称为“主坐标分析”(PCoA)或“Torgerson's scaling”,现在可在 sklearn.manifold 模块中使用。Classical MDS 接近 PCA,它不是近似距离,而是近似成对标量积,这在特征分解方面具有精确的解析解。
让我们通过在 S 曲线数据集上使用它来获得数据的低维表示,从而说明这一新增功能。
import matplotlib.pyplot as plt
from matplotlib import ticker
from sklearn import datasets, manifold
n_samples = 1500
S_points, S_color = datasets.make_s_curve(n_samples, random_state=0)
md_classical = manifold.ClassicalMDS(n_components=2)
S_scaling = md_classical.fit_transform(S_points)
fig = plt.figure(figsize=(8, 4))
ax1 = fig.add_subplot(1, 2, 1, projection="3d")
x, y, z = S_points.T
ax1.scatter(x, y, z, c=S_color, s=50, alpha=0.8)
ax1.set_title("Original S-curve samples", size=16)
ax1.view_init(azim=-60, elev=9)
for axis in (ax1.xaxis, ax1.yaxis, ax1.zaxis):
axis.set_major_locator(ticker.MultipleLocator(1))
ax2 = fig.add_subplot(1, 2, 2)
x2, y2 = S_scaling.T
ax2.scatter(x2, y2, c=S_color, s=50, alpha=0.8)
ax2.set_title("Classical MDS", size=16)
for axis in (ax2.xaxis, ax2.yaxis):
axis.set_major_formatter(ticker.NullFormatter())
plt.show()
脚本总运行时间: (0 minutes 13.717 seconds)
相关示例