注意
跳转到末尾 下载完整示例代码,或通过 JupyterLite 或 Binder 在浏览器中运行此示例
聚类性能评估中的随机性调整#
本笔记本探讨了均匀分布随机标签对某些聚类评估指标行为的影响。为此,指标是在固定样本数下计算的,并且是估计器分配的聚类数量的函数。该示例分为两个实验
第一个实验是固定“真实标签”(因此类别数固定)和随机“预测标签”;
第二个实验是变化“真实标签”,随机“预测标签”。“预测标签”具有与“真实标签”相同的类别数和聚类数。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
定义要评估的指标列表#
聚类算法本质上是无监督学习方法。然而,由于本示例中我们为合成聚类分配了类别标签,因此可以使用利用这种“监督”真实信息来量化所得聚类质量的评估指标。此类指标的示例如下:
V-measure,完整性和同质性的调和平均值;
Rand 指数,衡量数据点对根据聚类算法结果和真实类别分配一致分组的频率;
调整 Rand 指数 (ARI),一个经过随机性调整的 Rand 指数,使得随机聚类分配的 ARI 期望值为 0.0;
互信息 (MI) 是一种信息论度量,用于量化两个标签之间的依赖程度。请注意,完美标签的 MI 最大值取决于聚类数量和样本数量;
归一化互信息 (NMI),一个在大量数据点极限下定义在 0(无互信息)到 1(完美匹配标签分配,可进行标签置换)之间的互信息。它未针对随机性进行调整:因此当聚类数据点数量不够大时,随机标签的 MI 或 NMI 期望值可能显著不为零;
调整互信息 (AMI),一个经过随机性调整的互信息。与 ARI 类似,随机聚类分配的 AMI 期望值为 0.0。
更多信息,请参阅聚类性能评估模块。
from sklearn import metrics
score_funcs = [
("V-measure", metrics.v_measure_score),
("Rand index", metrics.rand_score),
("ARI", metrics.adjusted_rand_score),
("MI", metrics.mutual_info_score),
("NMI", metrics.normalized_mutual_info_score),
("AMI", metrics.adjusted_mutual_info_score),
]
第一个实验:固定真实标签和不断增加的聚类数量#
我们首先定义一个生成均匀分布随机标签的函数。
import numpy as np
rng = np.random.RandomState(0)
def random_labels(n_samples, n_classes):
return rng.randint(low=0, high=n_classes, size=n_samples)
另一个函数将使用 random_labels 函数创建一组固定分布在 n_classes 中的真实标签(labels_a),然后对几组随机“预测”标签(labels_b)进行评分,以评估给定度量在给定 n_clusters 下的变异性。
def fixed_classes_uniform_labelings_scores(
score_func, n_samples, n_clusters_range, n_classes, n_runs=5
):
scores = np.zeros((len(n_clusters_range), n_runs))
labels_a = random_labels(n_samples=n_samples, n_classes=n_classes)
for i, n_clusters in enumerate(n_clusters_range):
for j in range(n_runs):
labels_b = random_labels(n_samples=n_samples, n_classes=n_clusters)
scores[i, j] = score_func(labels_a, labels_b)
return scores
在第一个示例中,我们将类别数(真实聚类数)设置为 n_classes=10。聚类数量在 n_clusters_range 提供的值范围内变化。
import matplotlib.pyplot as plt
import seaborn as sns
n_samples = 1000
n_classes = 10
n_clusters_range = np.linspace(2, 100, 10).astype(int)
plots = []
names = []
sns.color_palette("colorblind")
plt.figure(1)
for marker, (score_name, score_func) in zip("d^vx.,", score_funcs):
scores = fixed_classes_uniform_labelings_scores(
score_func, n_samples, n_clusters_range, n_classes=n_classes
)
plots.append(
plt.errorbar(
n_clusters_range,
scores.mean(axis=1),
scores.std(axis=1),
alpha=0.8,
linewidth=1,
marker=marker,
)[0]
)
names.append(score_name)
plt.title(
"Clustering measures for random uniform labeling\n"
f"against reference assignment with {n_classes} classes"
)
plt.xlabel(f"Number of clusters (Number of samples is fixed to {n_samples})")
plt.ylabel("Score value")
plt.ylim(bottom=-0.05, top=1.05)
plt.legend(plots, names, bbox_to_anchor=(0.5, 0.5))
plt.show()
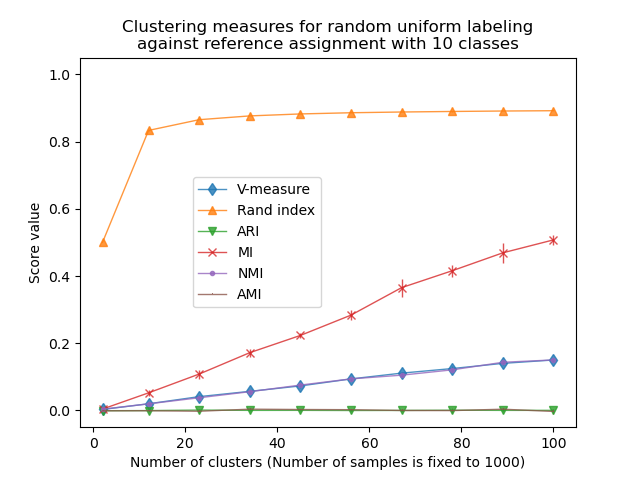
当 n_clusters > n_classes 时,Rand 指数趋于饱和。其他未调整的度量(如 V-Measure)显示出聚类数量和样本数量之间存在线性关系。
经过随机性调整的度量,如 ARI 和 AMI,显示出一些围绕平均得分 0.0 的随机变动,这与样本和聚类的数量无关。
第二个实验:变化的类别数和聚类数#
本节中,我们定义了一个类似的函数,使用多个指标对 2 个均匀分布的随机标签进行评分。在此情况下,对于 n_clusters_range 中的每个可能值,类别数和分配的聚类数都是匹配的。
def uniform_labelings_scores(score_func, n_samples, n_clusters_range, n_runs=5):
scores = np.zeros((len(n_clusters_range), n_runs))
for i, n_clusters in enumerate(n_clusters_range):
for j in range(n_runs):
labels_a = random_labels(n_samples=n_samples, n_classes=n_clusters)
labels_b = random_labels(n_samples=n_samples, n_classes=n_clusters)
scores[i, j] = score_func(labels_a, labels_b)
return scores
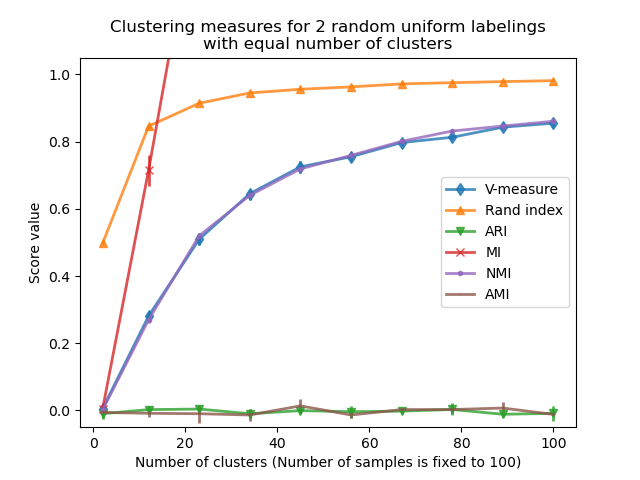
在此情况下,我们使用 n_samples=100 来展示聚类数量与样本数量相似或相等时的效果。
n_samples = 100
n_clusters_range = np.linspace(2, n_samples, 10).astype(int)
plt.figure(2)
plots = []
names = []
for marker, (score_name, score_func) in zip("d^vx.,", score_funcs):
scores = uniform_labelings_scores(score_func, n_samples, n_clusters_range)
plots.append(
plt.errorbar(
n_clusters_range,
np.median(scores, axis=1),
scores.std(axis=1),
alpha=0.8,
linewidth=2,
marker=marker,
)[0]
)
names.append(score_name)
plt.title(
"Clustering measures for 2 random uniform labelings\nwith equal number of clusters"
)
plt.xlabel(f"Number of clusters (Number of samples is fixed to {n_samples})")
plt.ylabel("Score value")
plt.legend(plots, names)
plt.ylim(bottom=-0.05, top=1.05)
plt.show()
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:49: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
/home/circleci/project/sklearn/metrics/cluster/_supervised.py:50: UserWarning:
The number of unique classes is greater than 50% of the number of samples.
我们观察到与第一个实验类似的结果:经过随机性调整的指标始终接近零,而其他指标则随着更细粒度的标签而趋于增大。随着聚类数量接近用于计算度量的总样本数,随机标签的平均 V-measure 显著增加。此外,原始互信息没有上限,其尺度取决于聚类问题的维度和真实类别的基数。这就是为什么曲线会超出图表的原因。
因此,只有经过调整的度量才能安全地用作共识指数,以评估聚类算法在数据集的各种重叠子样本上对于给定 k 值的平均稳定性。
因此,未调整的聚类评估指标可能会产生误导,因为它们对细粒度标签输出较大的值,这可能导致人们认为标签捕获了有意义的组,而实际上它们可能是完全随机的。特别是,不应使用此类未调整的指标来比较输出不同聚类数量的不同聚类算法的结果。
脚本总运行时间: (0 分 1.057 秒)
相关示例