章节导航
__sklearn_is_fitted__
FrozenEstimator
set_output
涉及 sklearn.multioutput 模块的示例。
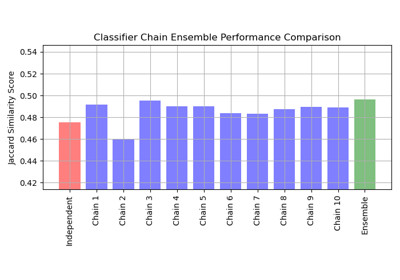
sklearn.multioutput
使用分类器链的多标签分类