注意
转至末尾以下载完整示例代码,或通过 JupyterLite 或 Binder 在浏览器中运行此示例。
自训练中不同阈值的影响#
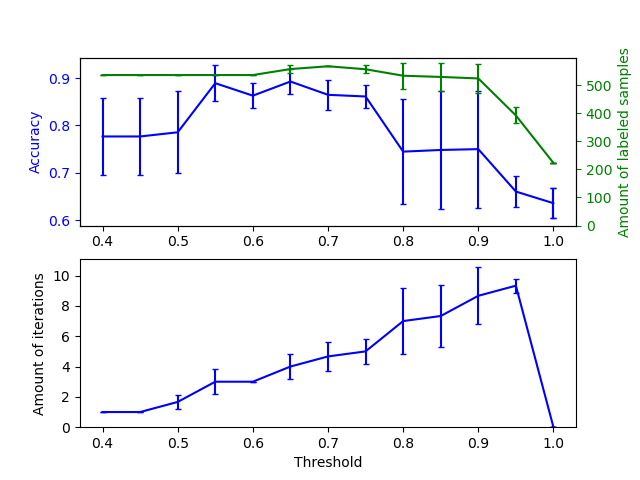
此示例说明了不同阈值对自训练的影响。加载 breast_cancer 数据集,并删除标签,使 569 个样本中只有 50 个具有标签。在具有不同阈值的此数据集上拟合 SelfTrainingClassifier。
上图显示了分类器在拟合结束时可用的带标签样本数量以及分类器的准确性。下图显示了样本被标记的最后一次迭代。所有值均使用 3 折交叉验证。
在低阈值([0.4, 0.5] 中)下,分类器从以低置信度标记的样本中学习。这些低置信度样本可能具有不正确的预测标签,因此,在这些不正确的标签上进行拟合会产生较差的准确性。请注意,分类器标记了几乎所有样本,并且只进行了一次迭代。
对于非常高的阈值([0.9, 1) 中),我们观察到分类器不会增加其数据集(自标记样本的数量为 0)。因此,使用 0.9999 的阈值获得的准确性与普通有监督分类器获得的准确性相同。
最佳准确性介于这两个极端之间,阈值约为 0.7。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets
from sklearn.metrics import accuracy_score
from sklearn.model_selection import StratifiedKFold
from sklearn.semi_supervised import SelfTrainingClassifier
from sklearn.svm import SVC
from sklearn.utils import shuffle
n_splits = 3
X, y = datasets.load_breast_cancer(return_X_y=True)
X, y = shuffle(X, y, random_state=42)
y_true = y.copy()
y[50:] = -1
total_samples = y.shape[0]
base_classifier = SVC(probability=True, gamma=0.001, random_state=42)
x_values = np.arange(0.4, 1.05, 0.05)
x_values = np.append(x_values, 0.99999)
scores = np.empty((x_values.shape[0], n_splits))
amount_labeled = np.empty((x_values.shape[0], n_splits))
amount_iterations = np.empty((x_values.shape[0], n_splits))
for i, threshold in enumerate(x_values):
self_training_clf = SelfTrainingClassifier(base_classifier, threshold=threshold)
# We need manual cross validation so that we don't treat -1 as a separate
# class when computing accuracy
skfolds = StratifiedKFold(n_splits=n_splits)
for fold, (train_index, test_index) in enumerate(skfolds.split(X, y)):
X_train = X[train_index]
y_train = y[train_index]
X_test = X[test_index]
y_test = y[test_index]
y_test_true = y_true[test_index]
self_training_clf.fit(X_train, y_train)
# The amount of labeled samples that at the end of fitting
amount_labeled[i, fold] = (
total_samples
- np.unique(self_training_clf.labeled_iter_, return_counts=True)[1][0]
)
# The last iteration the classifier labeled a sample in
amount_iterations[i, fold] = np.max(self_training_clf.labeled_iter_)
y_pred = self_training_clf.predict(X_test)
scores[i, fold] = accuracy_score(y_test_true, y_pred)
ax1 = plt.subplot(211)
ax1.errorbar(
x_values, scores.mean(axis=1), yerr=scores.std(axis=1), capsize=2, color="b"
)
ax1.set_ylabel("Accuracy", color="b")
ax1.tick_params("y", colors="b")
ax2 = ax1.twinx()
ax2.errorbar(
x_values,
amount_labeled.mean(axis=1),
yerr=amount_labeled.std(axis=1),
capsize=2,
color="g",
)
ax2.set_ylim(bottom=0)
ax2.set_ylabel("Amount of labeled samples", color="g")
ax2.tick_params("y", colors="g")
ax3 = plt.subplot(212, sharex=ax1)
ax3.errorbar(
x_values,
amount_iterations.mean(axis=1),
yerr=amount_iterations.std(axis=1),
capsize=2,
color="b",
)
ax3.set_ylim(bottom=0)
ax3.set_ylabel("Amount of iterations")
ax3.set_xlabel("Threshold")
plt.show()
脚本总运行时间: (0 minutes 5.289 seconds)
相关示例