注意
转到末尾以下载完整示例代码或通过 JupyterLite 或 Binder 在浏览器中运行此示例。
带协方差椭球的线性和二次判别分析#
此示例绘制了每个类别的协方差椭球以及 LinearDiscriminantAnalysis (LDA) 和 QuadraticDiscriminantAnalysis (QDA) 学习到的决策边界。椭球显示了每个类别的双标准差。对于 LDA,所有类别的标准差相同,而对于 QDA,每个类别都有自己的标准差。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
数据生成#
首先,我们定义一个函数来生成合成数据。它创建两个分别以 (0, 0) 和 (1, 1) 为中心的团块。每个团块被分配给一个特定的类别。团块的离散程度由参数 cov_class_1 和 cov_class_2 控制,这些参数是用于从高斯分布生成样本的协方差矩阵。
import numpy as np
def make_data(n_samples, n_features, cov_class_1, cov_class_2, seed=0):
rng = np.random.RandomState(seed)
X = np.concatenate(
[
rng.randn(n_samples, n_features) @ cov_class_1,
rng.randn(n_samples, n_features) @ cov_class_2 + np.array([1, 1]),
]
)
y = np.concatenate([np.zeros(n_samples), np.ones(n_samples)])
return X, y
我们生成三个数据集。在第一个数据集中,两个类别共享相同的协方差矩阵,并且该协方差矩阵具有球形(各向同性)的特性。第二个数据集与第一个数据集相似,但不强制协方差为球形。最后,第三个数据集的每个类别都有一个非球形协方差矩阵。
covariance = np.array([[1, 0], [0, 1]])
X_isotropic_covariance, y_isotropic_covariance = make_data(
n_samples=1_000,
n_features=2,
cov_class_1=covariance,
cov_class_2=covariance,
seed=0,
)
covariance = np.array([[0.0, -0.23], [0.83, 0.23]])
X_shared_covariance, y_shared_covariance = make_data(
n_samples=300,
n_features=2,
cov_class_1=covariance,
cov_class_2=covariance,
seed=0,
)
cov_class_1 = np.array([[0.0, -1.0], [2.5, 0.7]]) * 2.0
cov_class_2 = cov_class_1.T
X_different_covariance, y_different_covariance = make_data(
n_samples=300,
n_features=2,
cov_class_1=cov_class_1,
cov_class_2=cov_class_2,
seed=0,
)
绘图函数#
下面的代码用于绘制所用估计器(即 LinearDiscriminantAnalysis (LDA) 和 QuadraticDiscriminantAnalysis (QDA))的几条信息。显示的信息包括:
基于估计器概率估计的决策边界;
带有圆圈的散点图,表示分类正确的样本;
带有叉号的散点图,表示分类错误的样本;
估计器估计的每个类别的均值,用星号标记;
估计的协方差,用一个在均值处且距离均值2个标准差的椭圆表示。
import matplotlib as mpl
from matplotlib import colors
from sklearn.inspection import DecisionBoundaryDisplay
def plot_ellipse(mean, cov, color, ax):
v, w = np.linalg.eigh(cov)
u = w[0] / np.linalg.norm(w[0])
angle = np.arctan(u[1] / u[0])
angle = 180 * angle / np.pi # convert to degrees
# filled Gaussian at 2 standard deviation
ell = mpl.patches.Ellipse(
mean,
2 * v[0] ** 0.5,
2 * v[1] ** 0.5,
angle=180 + angle,
facecolor=color,
edgecolor="black",
linewidth=2,
)
ell.set_clip_box(ax.bbox)
ell.set_alpha(0.4)
ax.add_artist(ell)
def plot_result(estimator, X, y, ax):
cmap = colors.ListedColormap(["tab:red", "tab:blue"])
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="predict_proba",
plot_method="pcolormesh",
ax=ax,
cmap="RdBu",
alpha=0.3,
)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="predict_proba",
plot_method="contour",
ax=ax,
alpha=1.0,
levels=[0.5],
)
y_pred = estimator.predict(X)
X_right, y_right = X[y == y_pred], y[y == y_pred]
X_wrong, y_wrong = X[y != y_pred], y[y != y_pred]
ax.scatter(X_right[:, 0], X_right[:, 1], c=y_right, s=20, cmap=cmap, alpha=0.5)
ax.scatter(
X_wrong[:, 0],
X_wrong[:, 1],
c=y_wrong,
s=30,
cmap=cmap,
alpha=0.9,
marker="x",
)
ax.scatter(
estimator.means_[:, 0],
estimator.means_[:, 1],
c="yellow",
s=200,
marker="*",
edgecolor="black",
)
if isinstance(estimator, LinearDiscriminantAnalysis):
covariance = [estimator.covariance_] * 2
else:
covariance = estimator.covariance_
plot_ellipse(estimator.means_[0], covariance[0], "tab:red", ax)
plot_ellipse(estimator.means_[1], covariance[1], "tab:blue", ax)
ax.set_box_aspect(1)
ax.spines["top"].set_visible(False)
ax.spines["bottom"].set_visible(False)
ax.spines["left"].set_visible(False)
ax.spines["right"].set_visible(False)
ax.set(xticks=[], yticks=[])
LDA 和 QDA 的比较#
我们比较了 LDA 和 QDA 在所有三个数据集上的表现。
import matplotlib.pyplot as plt
from sklearn.discriminant_analysis import (
LinearDiscriminantAnalysis,
QuadraticDiscriminantAnalysis,
)
fig, axs = plt.subplots(nrows=3, ncols=2, sharex="row", sharey="row", figsize=(8, 12))
lda = LinearDiscriminantAnalysis(solver="svd", store_covariance=True)
qda = QuadraticDiscriminantAnalysis(solver="svd", store_covariance=True)
for ax_row, X, y in zip(
axs,
(X_isotropic_covariance, X_shared_covariance, X_different_covariance),
(y_isotropic_covariance, y_shared_covariance, y_different_covariance),
):
lda.fit(X, y)
plot_result(lda, X, y, ax_row[0])
qda.fit(X, y)
plot_result(qda, X, y, ax_row[1])
axs[0, 0].set_title("Linear Discriminant Analysis")
axs[0, 0].set_ylabel("Data with fixed and spherical covariance")
axs[1, 0].set_ylabel("Data with fixed covariance")
axs[0, 1].set_title("Quadratic Discriminant Analysis")
axs[2, 0].set_ylabel("Data with varying covariances")
fig.suptitle(
"Linear Discriminant Analysis vs Quadratic Discriminant Analysis",
y=0.94,
fontsize=15,
)
plt.show()
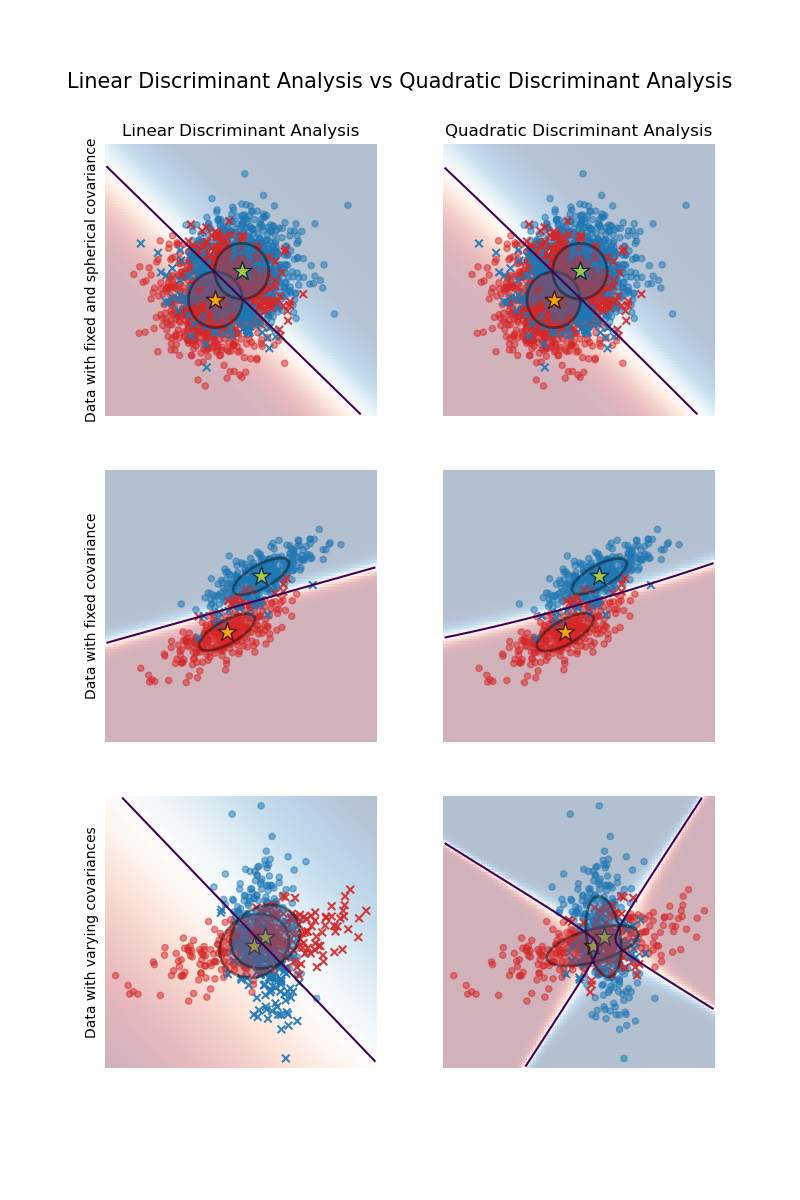
首先需要注意的重要一点是,对于第一个和第二个数据集,LDA 和 QDA 是等效的。事实上,主要区别在于 LDA 假设每个类别的协方差矩阵相等,而 QDA 为每个类别估计一个协方差矩阵。由于在这些情况下数据生成过程对两个类别使用了相同的协方差矩阵,QDA 估计的两个协方差矩阵(几乎)相等,因此与 LDA 估计的协方差矩阵等效。
在第一个数据集中,用于生成数据集的协方差矩阵是球形的,这导致判别边界与两个均值之间的垂直平分线对齐。对于第二个数据集,情况不再如此。判别边界仅穿过两个均值的中间位置。
最后,在第三个数据集中,我们观察到了 LDA 和 QDA 之间的真正区别。QDA 拟合两个协方差矩阵并提供一个非线性的判别边界,而 LDA 则因为假设两个类别共享一个协方差矩阵而欠拟合。
脚本总运行时间: (0 minutes 0.356 seconds)
相关示例