注意
转到末尾 下载完整的示例代码,或通过 JupyterLite 或 Binder 在浏览器中运行此示例。
HDBSCAN 聚类算法演示#
在此演示中,我们将从概括 cluster.DBSCAN 算法的角度来探讨 cluster.HDBSCAN。我们将在特定数据集上比较这两种算法。最后,我们将评估 HDBSCAN 对某些超参数的敏感性。
我们首先定义几个实用函数以方便使用。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import DBSCAN, HDBSCAN
from sklearn.datasets import make_blobs
def plot(X, labels, probabilities=None, parameters=None, ground_truth=False, ax=None):
if ax is None:
_, ax = plt.subplots(figsize=(10, 4))
labels = labels if labels is not None else np.ones(X.shape[0])
probabilities = probabilities if probabilities is not None else np.ones(X.shape[0])
# Black removed and is used for noise instead.
unique_labels = set(labels)
colors = [plt.cm.Spectral(each) for each in np.linspace(0, 1, len(unique_labels))]
# The probability of a point belonging to its labeled cluster determines
# the size of its marker
proba_map = {idx: probabilities[idx] for idx in range(len(labels))}
for k, col in zip(unique_labels, colors):
if k == -1:
# Black used for noise.
col = [0, 0, 0, 1]
class_index = (labels == k).nonzero()[0]
for ci in class_index:
ax.plot(
X[ci, 0],
X[ci, 1],
"x" if k == -1 else "o",
markerfacecolor=tuple(col),
markeredgecolor="k",
markersize=4 if k == -1 else 1 + 5 * proba_map[ci],
)
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
preamble = "True" if ground_truth else "Estimated"
title = f"{preamble} number of clusters: {n_clusters_}"
if parameters is not None:
parameters_str = ", ".join(f"{k}={v}" for k, v in parameters.items())
title += f" | {parameters_str}"
ax.set_title(title)
plt.tight_layout()
生成样本数据#
HDBSCAN 相较于 DBSCAN 的最大优势之一是其开箱即用的鲁棒性。它在异构数据混合物上表现尤为出色。与 DBSCAN 一样,它可以对任意形状和分布进行建模,但与 DBSCAN 不同的是,它不需要指定任意且敏感的 eps 超参数。
例如,下面我们从三个二维各向同性高斯分布的混合物中生成一个数据集。
centers = [[1, 1], [-1, -1], [1.5, -1.5]]
X, labels_true = make_blobs(
n_samples=750, centers=centers, cluster_std=[0.4, 0.1, 0.75], random_state=0
)
plot(X, labels=labels_true, ground_truth=True)
尺度不变性#
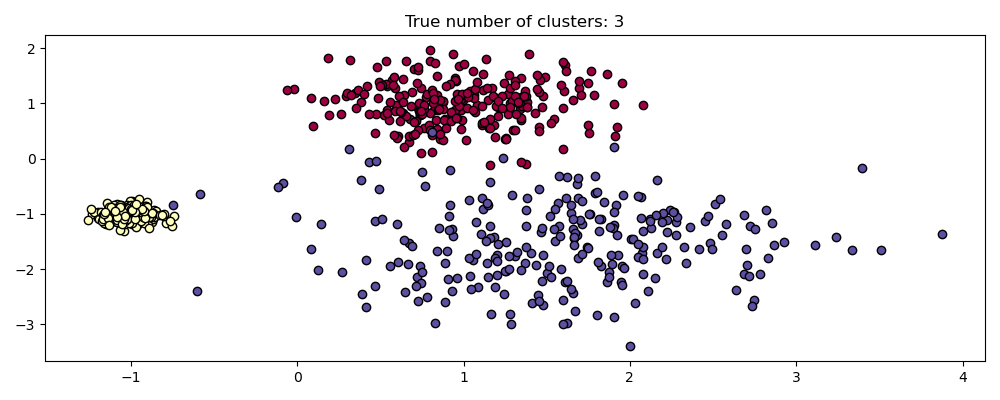
值得记住的是,虽然 DBSCAN 为 eps 参数提供了一个默认值,但它几乎没有一个合适的默认值,必须针对所使用的特定数据集进行调整。
作为一个简单的演示,考虑对一个数据集调整的 eps 值进行聚类,以及使用相同值但应用于数据集重新缩放版本获得的聚类。
fig, axes = plt.subplots(3, 1, figsize=(10, 12))
dbs = DBSCAN(eps=0.3)
for idx, scale in enumerate([1, 0.5, 3]):
dbs.fit(X * scale)
plot(X * scale, dbs.labels_, parameters={"scale": scale, "eps": 0.3}, ax=axes[idx])
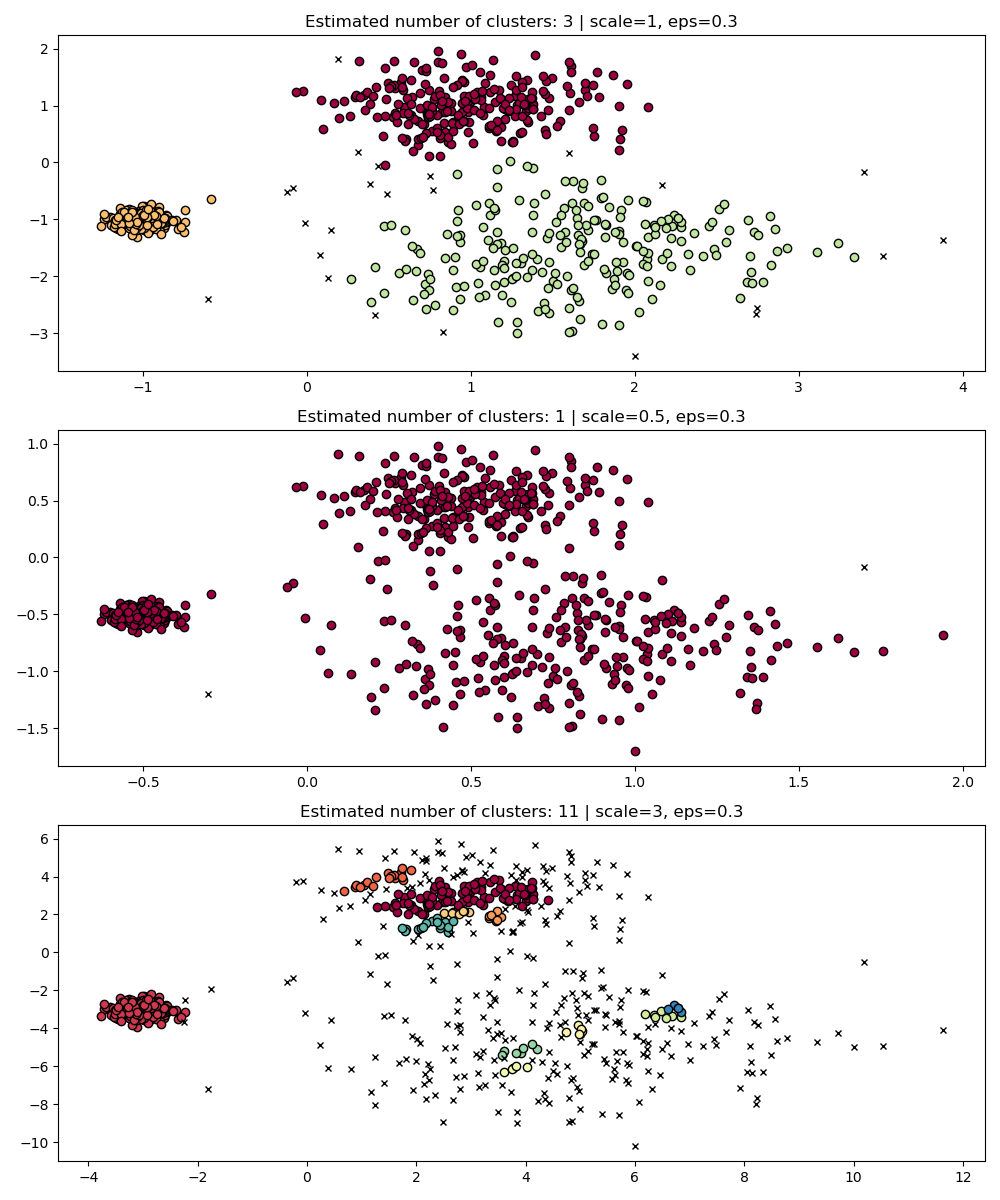
事实上,为了保持相同的结果,我们必须按相同的因子缩放 eps。
fig, axis = plt.subplots(1, 1, figsize=(12, 5))
dbs = DBSCAN(eps=0.9).fit(3 * X)
plot(3 * X, dbs.labels_, parameters={"scale": 3, "eps": 0.9}, ax=axis)
虽然数据标准化(例如,使用 sklearn.preprocessing.StandardScaler)有助于缓解这个问题,但必须非常小心地选择 eps 的适当值。
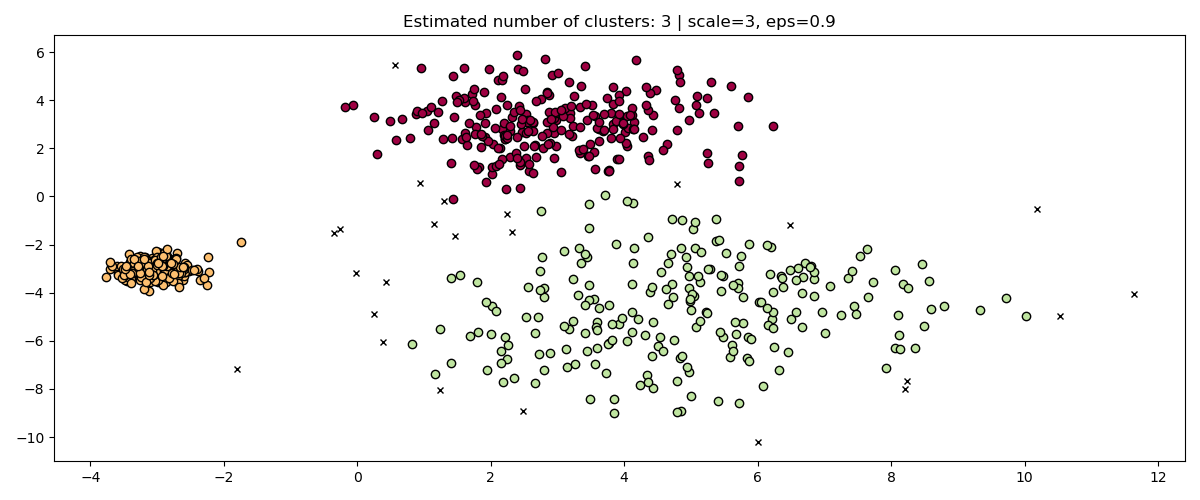
HDBSCAN 在这个意义上更加鲁棒:HDBSCAN 可以被视为对所有可能的 eps 值进行聚类,并从所有可能的聚类中提取最佳聚类(参见 用户指南)。一个直接的优势是 HDBSCAN 具有尺度不变性。
fig, axes = plt.subplots(3, 1, figsize=(10, 12))
hdb = HDBSCAN(copy=True)
for idx, scale in enumerate([1, 0.5, 3]):
hdb.fit(X * scale)
plot(
X * scale,
hdb.labels_,
hdb.probabilities_,
ax=axes[idx],
parameters={"scale": scale},
)
多尺度聚类#
然而,HDBSCAN 不仅仅是尺度不变的——它能够进行多尺度聚类,这解释了具有不同密度变化的聚类。传统的 DBSCAN 假设任何潜在的聚类在密度上都是均匀的。HDBSCAN 则不受此类约束。为了演示这一点,我们考虑以下数据集
centers = [[-0.85, -0.85], [-0.85, 0.85], [3, 3], [3, -3]]
X, labels_true = make_blobs(
n_samples=750, centers=centers, cluster_std=[0.2, 0.35, 1.35, 1.35], random_state=0
)
plot(X, labels=labels_true, ground_truth=True)
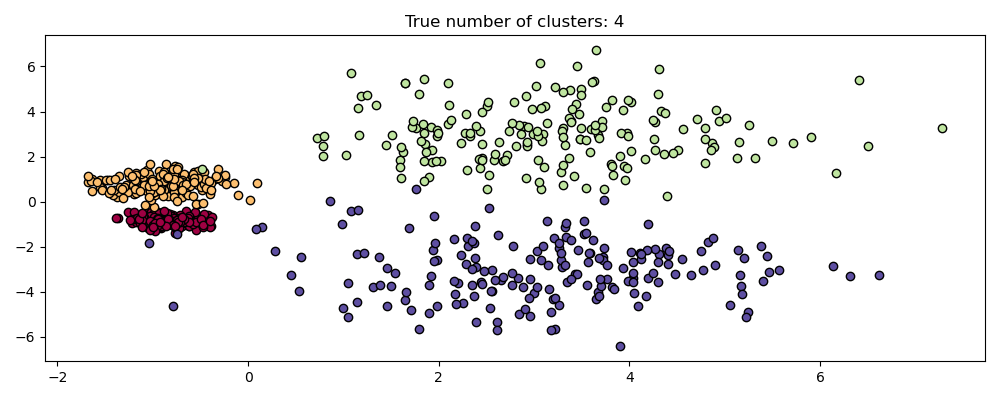
由于密度和空间分离的不同,这个数据集对 DBSCAN 来说更困难
如果
eps太大,我们就有可能错误地将两个密集聚类聚为一类,因为它们的互可达性会扩展聚类。如果
eps太小,我们就有可能将稀疏聚类分解成许多错误的聚类。
更不用说这需要手动调整 eps 的选择,直到找到一个我们满意的折衷方案。
fig, axes = plt.subplots(2, 1, figsize=(10, 8))
params = {"eps": 0.7}
dbs = DBSCAN(**params).fit(X)
plot(X, dbs.labels_, parameters=params, ax=axes[0])
params = {"eps": 0.3}
dbs = DBSCAN(**params).fit(X)
plot(X, dbs.labels_, parameters=params, ax=axes[1])
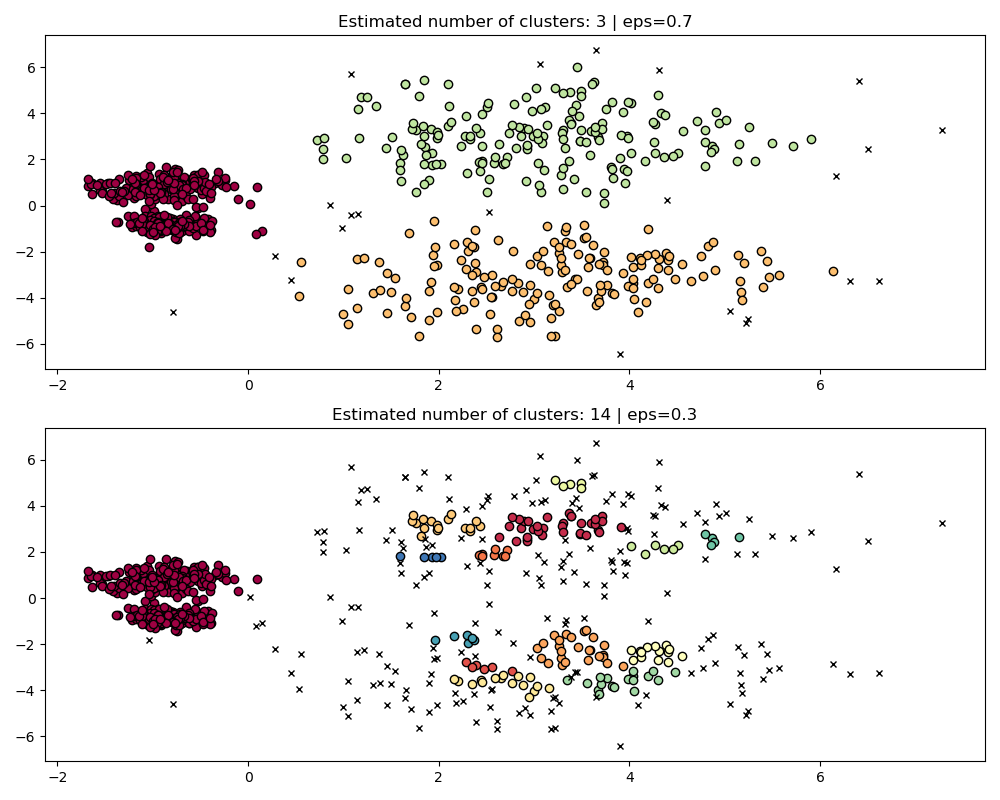
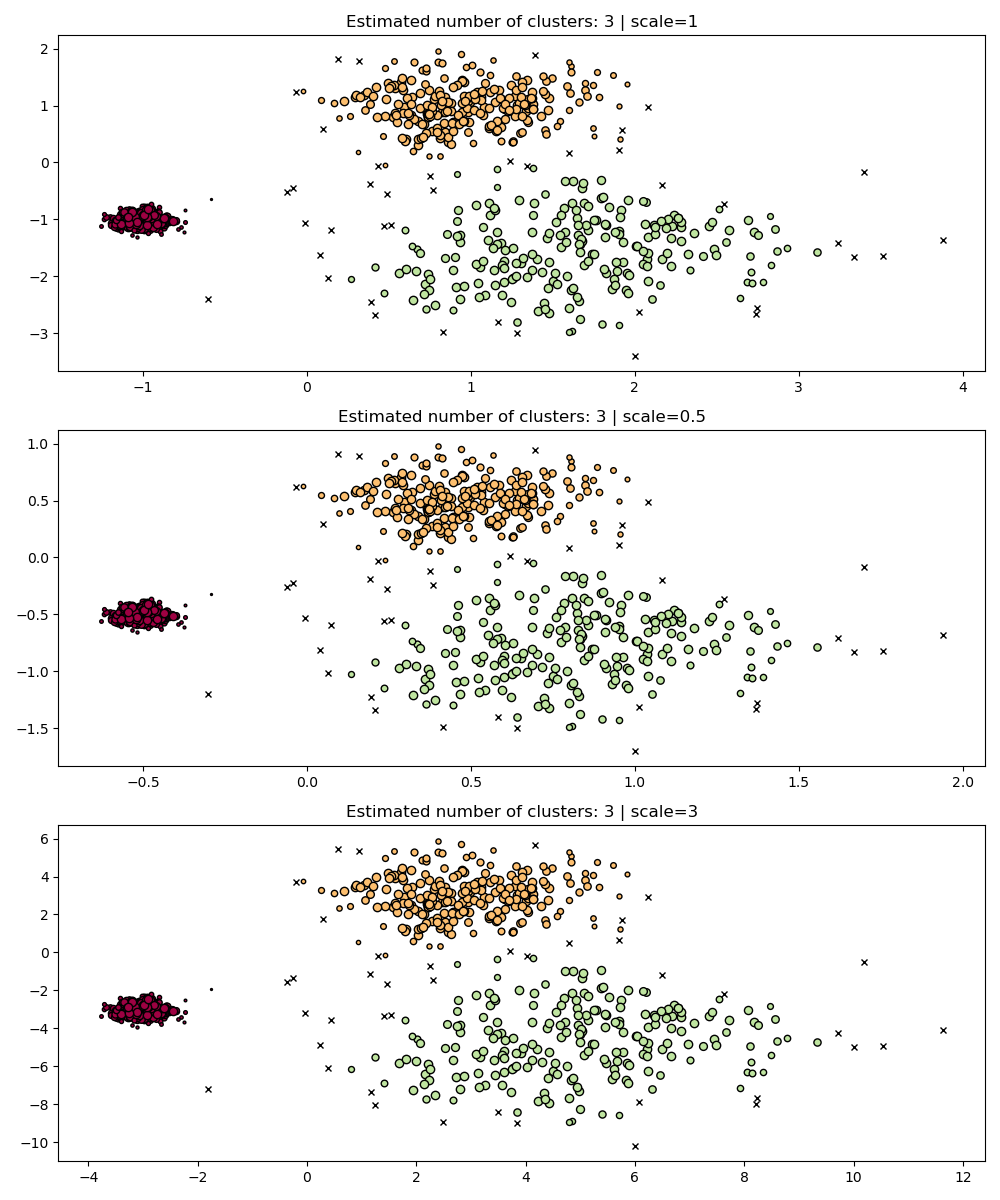
为了正确地聚类这两个密集聚类,我们需要一个较小的 epsilon 值,然而在 eps=0.3 时,我们已经将稀疏聚类分解了,随着我们减小 epsilon,情况只会变得更加严重。事实上,DBSCAN 似乎无法同时分离两个密集聚类,同时防止稀疏聚类分解。让我们与 HDBSCAN 进行比较。
hdb = HDBSCAN(copy=True).fit(X)
plot(X, hdb.labels_, hdb.probabilities_)
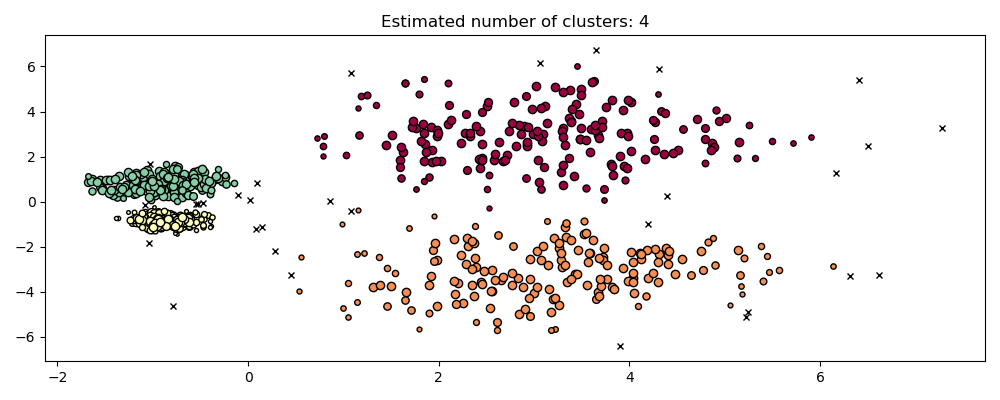
HDBSCAN 能够适应数据集的多尺度结构,而无需进行参数调整。虽然任何足够有趣的数据集都需要调整,但这个案例表明 HDBSCAN 可以在没有用户干预的情况下产生定性上更好的聚类类别,而这是 DBSCAN 无法实现的。
超参数鲁棒性#
最终,在任何实际应用中,调整都是重要的一步,所以让我们来看看 HDBSCAN 的一些最重要的超参数。虽然 HDBSCAN 没有 DBSCAN 的 eps 参数,但它仍然有一些超参数,例如 min_cluster_size 和 min_samples,它们调整其关于密度的结果。然而,我们将看到 HDBSCAN 相对于各种现实世界示例具有相对鲁棒性,这得益于这些参数,它们的明确含义有助于调整它们。
min_cluster_size#
min_cluster_size 是一个组中被视为聚类的最小样本数。
小于此大小的聚类将被留作噪声。默认值为 5。通常根据需要将此参数调整为更大的值。较小的值可能会导致更少的点被标记为噪声。然而,太小的值会导致错误的子聚类被选中并优先考虑。较大的值往往对噪声数据集更鲁棒,例如具有显着重叠的高方差聚类。
PARAM = ({"min_cluster_size": 5}, {"min_cluster_size": 3}, {"min_cluster_size": 25})
fig, axes = plt.subplots(3, 1, figsize=(10, 12))
for i, param in enumerate(PARAM):
hdb = HDBSCAN(copy=True, **param).fit(X)
labels = hdb.labels_
plot(X, labels, hdb.probabilities_, param, ax=axes[i])
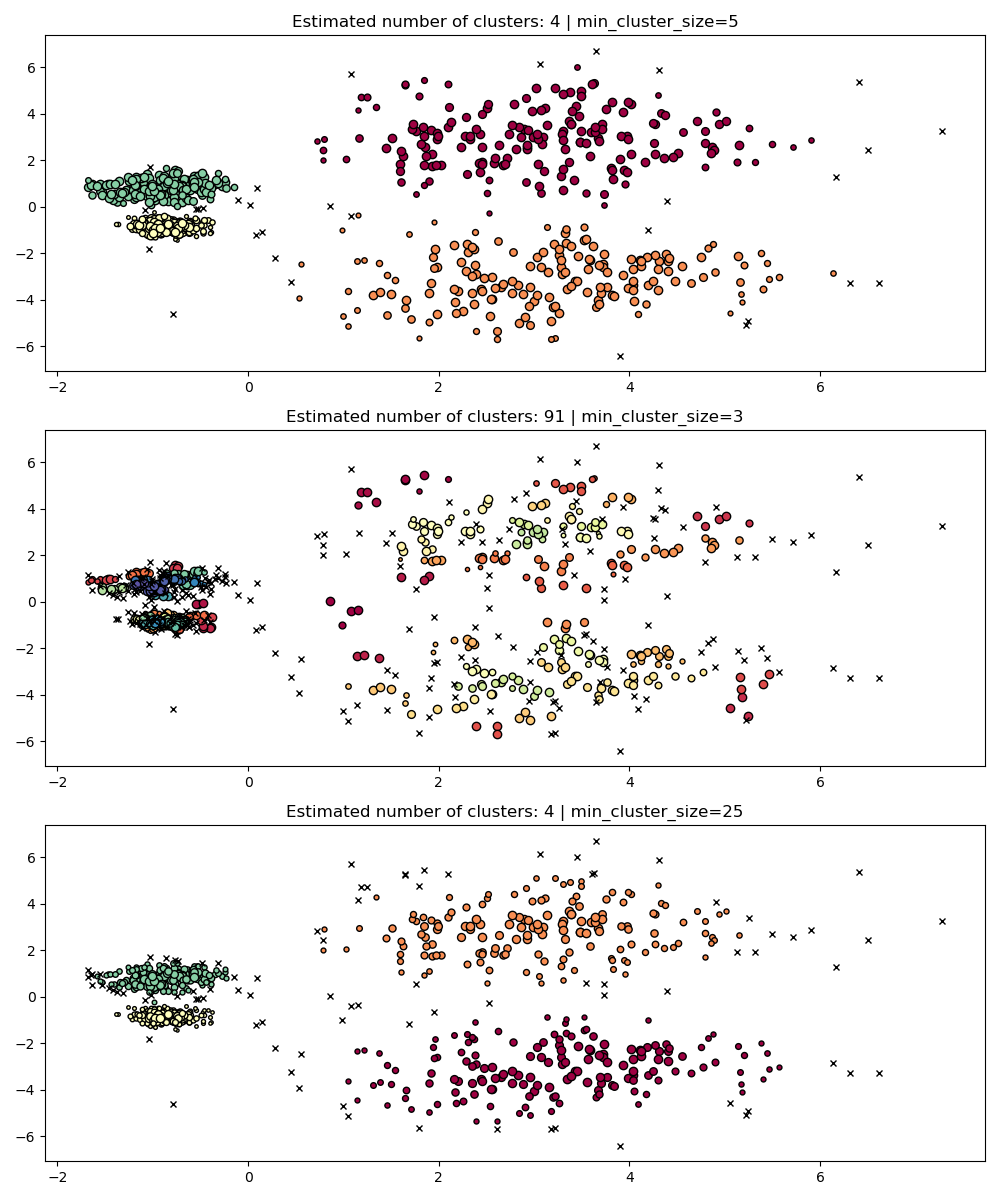
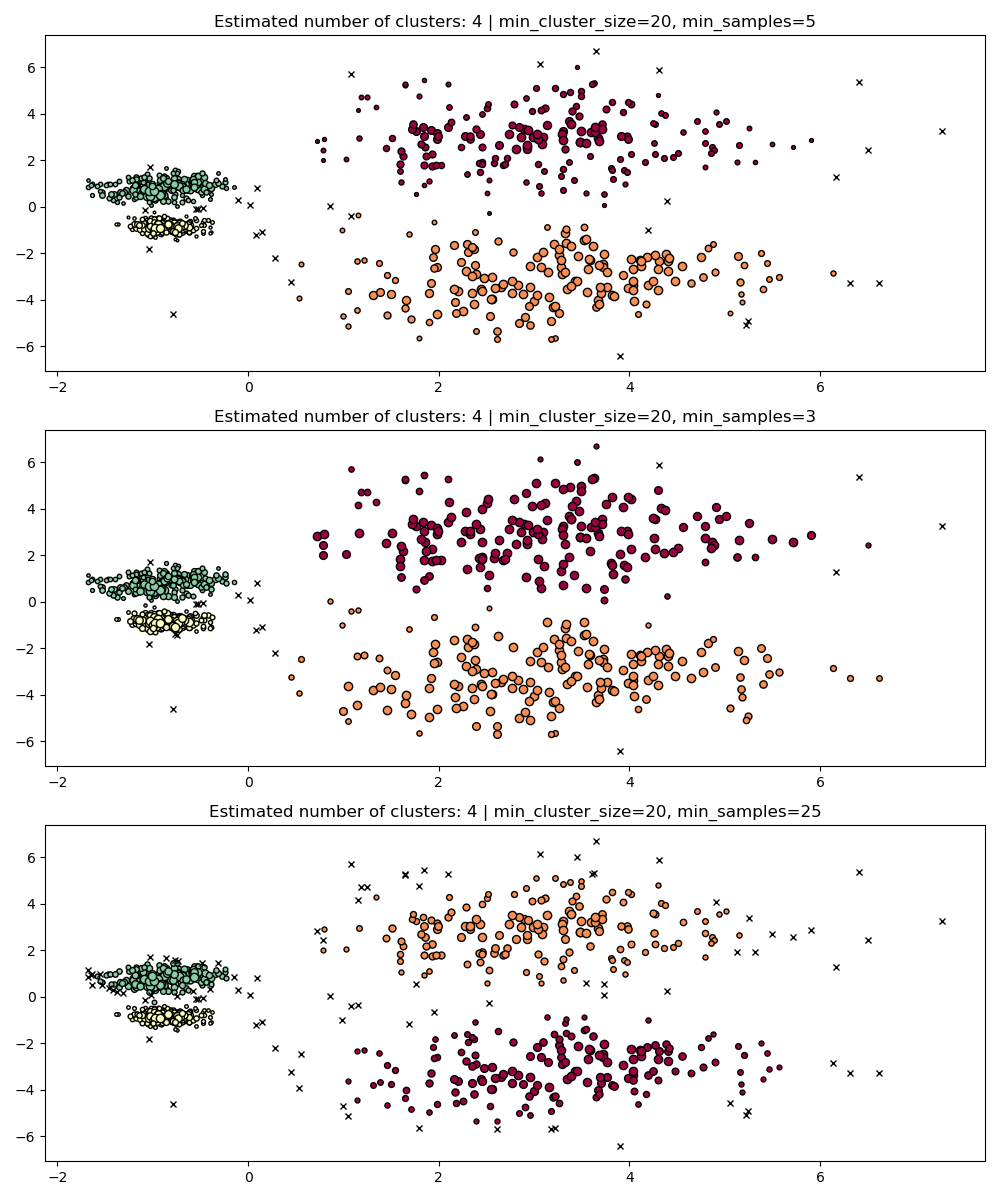
min_samples#
min_samples 是一个邻域中一个点被视为核心点的样本数,包括该点本身。min_samples 默认为 min_cluster_size。与 min_cluster_size 类似,较大的 min_samples 值会增加模型的抗噪鲁棒性,但可能会忽略或丢弃潜在有效但小的聚类。min_samples 最好在找到 min_cluster_size 的合适值后进行调整。
PARAM = (
{"min_cluster_size": 20, "min_samples": 5},
{"min_cluster_size": 20, "min_samples": 3},
{"min_cluster_size": 20, "min_samples": 25},
)
fig, axes = plt.subplots(3, 1, figsize=(10, 12))
for i, param in enumerate(PARAM):
hdb = HDBSCAN(copy=True, **param).fit(X)
labels = hdb.labels_
plot(X, labels, hdb.probabilities_, param, ax=axes[i])
dbscan_clustering#
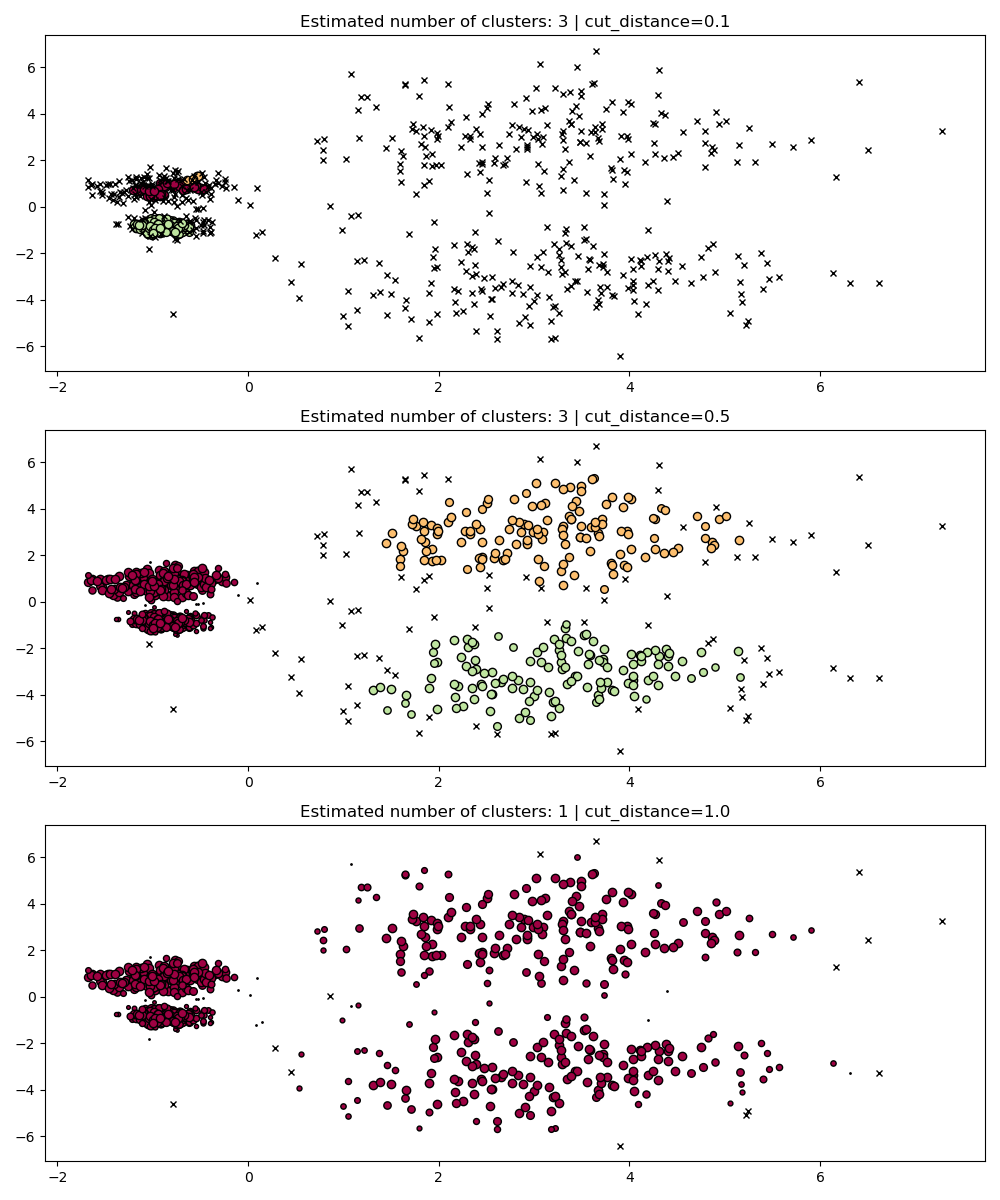
在 fit 期间,HDBSCAN 构建了一个单链接树,该树编码了所有点在 DBSCAN 的 eps 参数的所有值上的聚类。因此,我们可以高效地绘制和评估这些聚类,而无需完全重新计算诸如核心距离、互可达性以及最小生成树之类的中间值。我们所需要做的就是指定我们想要聚类的 cut_distance(等同于 eps)。
PARAM = (
{"cut_distance": 0.1},
{"cut_distance": 0.5},
{"cut_distance": 1.0},
)
hdb = HDBSCAN(copy=True)
hdb.fit(X)
fig, axes = plt.subplots(len(PARAM), 1, figsize=(10, 12))
for i, param in enumerate(PARAM):
labels = hdb.dbscan_clustering(**param)
plot(X, labels, hdb.probabilities_, param, ax=axes[i])
脚本总运行时间: (0 分钟 11.854 秒)
相关示例