注
转到末尾 下载完整示例代码。或通过 JupyterLite 或 Binder 在浏览器中运行此示例
分类器校准的比较#
良好校准的分类器是指其 predict_proba 输出可以直接解释为置信水平的概率分类器。例如,一个良好校准的(二元)分类器应该对样本进行分类,使得对于那些给出接近 0.8 的 predict_proba 值的样本,大约 80% 实际属于正类别。
在本示例中,我们将比较四种不同模型的校准情况:逻辑回归、高斯朴素贝叶斯、随机森林分类器 和 线性支持向量机。
作者:scikit-learn 开发者 SPDX-License-Identifier: BSD-3-Clause
#
# Dataset
# -------
#
# We will use a synthetic binary classification dataset with 100,000 samples
# and 20 features. Of the 20 features, only 2 are informative, 2 are
# redundant (random combinations of the informative features) and the
# remaining 16 are uninformative (random numbers).
#
# Of the 100,000 samples, 100 will be used for model fitting and the remaining
# for testing. Note that this split is quite unusual: the goal is to obtain
# stable calibration curve estimates for models that are potentially prone to
# overfitting. In practice, one should rather use cross-validation with more
# balanced splits but this would make the code of this example more complicated
# to follow.
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
X, y = make_classification(
n_samples=100_000, n_features=20, n_informative=2, n_redundant=2, random_state=42
)
train_samples = 100 # Samples used for training the models
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
shuffle=False,
test_size=100_000 - train_samples,
)
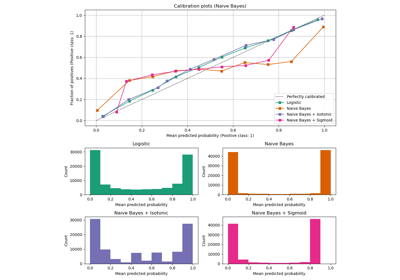
校准曲线#
下面,我们使用少量训练数据集训练这四种模型,然后使用测试数据集的预测概率绘制校准曲线(也称为可靠性图)。校准曲线是通过对预测概率进行分箱,然后绘制每个分箱中平均预测概率与观测频率(“正例比例”)的关系图来创建的。在校准曲线下方,我们绘制了一个直方图,显示了预测概率的分布,更具体地说,是每个预测概率分箱中的样本数量。
import numpy as np
from sklearn.svm import LinearSVC
class NaivelyCalibratedLinearSVC(LinearSVC):
"""LinearSVC with `predict_proba` method that naively scales
`decision_function` output."""
def fit(self, X, y):
super().fit(X, y)
df = self.decision_function(X)
self.df_min_ = df.min()
self.df_max_ = df.max()
def predict_proba(self, X):
"""Min-max scale output of `decision_function` to [0,1]."""
df = self.decision_function(X)
calibrated_df = (df - self.df_min_) / (self.df_max_ - self.df_min_)
proba_pos_class = np.clip(calibrated_df, 0, 1)
proba_neg_class = 1 - proba_pos_class
proba = np.c_[proba_neg_class, proba_pos_class]
return proba
from sklearn.calibration import CalibrationDisplay
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegressionCV
from sklearn.naive_bayes import GaussianNB
# Define the classifiers to be compared in the study.
#
# Note that we use a variant of the logistic regression model that can
# automatically tune its regularization parameter.
#
# For a fair comparison, we should run a hyper-parameter search for all the
# classifiers but we don't do it here for the sake of keeping the example code
# concise and fast to execute.
lr = LogisticRegressionCV(
Cs=np.logspace(-6, 6, 101), cv=10, scoring="neg_log_loss", max_iter=1_000
)
gnb = GaussianNB()
svc = NaivelyCalibratedLinearSVC(C=1.0)
rfc = RandomForestClassifier(random_state=42)
clf_list = [
(lr, "Logistic Regression"),
(gnb, "Naive Bayes"),
(svc, "SVC"),
(rfc, "Random forest"),
]
import matplotlib.pyplot as plt
from matplotlib.gridspec import GridSpec
fig = plt.figure(figsize=(10, 10))
gs = GridSpec(4, 2)
colors = plt.get_cmap("Dark2")
ax_calibration_curve = fig.add_subplot(gs[:2, :2])
calibration_displays = {}
markers = ["^", "v", "s", "o"]
for i, (clf, name) in enumerate(clf_list):
clf.fit(X_train, y_train)
display = CalibrationDisplay.from_estimator(
clf,
X_test,
y_test,
n_bins=10,
name=name,
ax=ax_calibration_curve,
color=colors(i),
marker=markers[i],
)
calibration_displays[name] = display
ax_calibration_curve.grid()
ax_calibration_curve.set_title("Calibration plots")
# Add histogram
grid_positions = [(2, 0), (2, 1), (3, 0), (3, 1)]
for i, (_, name) in enumerate(clf_list):
row, col = grid_positions[i]
ax = fig.add_subplot(gs[row, col])
ax.hist(
calibration_displays[name].y_prob,
range=(0, 1),
bins=10,
label=name,
color=colors(i),
)
ax.set(title=name, xlabel="Mean predicted probability", ylabel="Count")
plt.tight_layout()
plt.show()
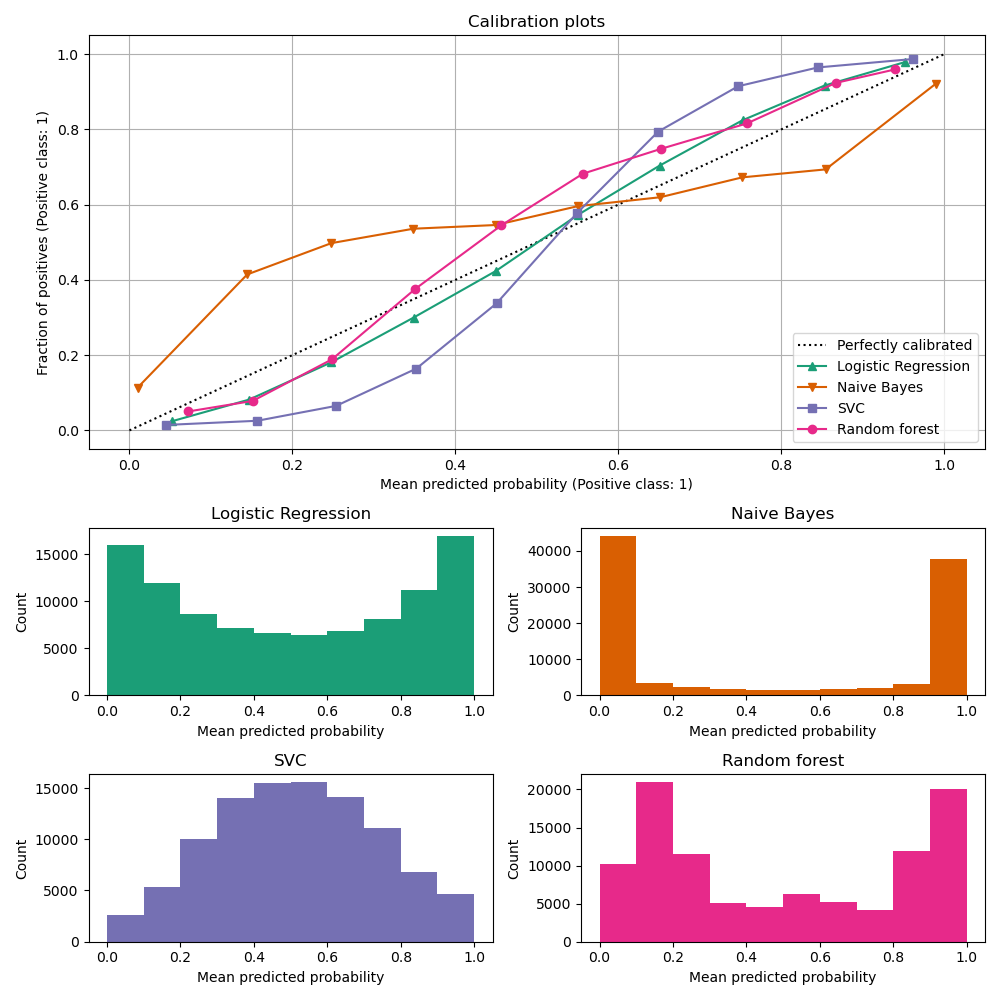
结果分析#
尽管训练集规模很小,LogisticRegressionCV 仍能返回相当良好校准的预测:它的可靠性曲线在四种模型中最接近对角线。
逻辑回归通过最小化对数损失进行训练,对数损失是一种严格的适当评分规则:在无限训练数据的极限情况下,预测真实条件概率的模型将使严格的适当评分规则最小化。因此,该(假设的)模型将是完美校准的。然而,单独使用适当评分规则作为训练目标不足以保证模型良好校准:即使训练集非常大,如果逻辑回归正则化过强,或者输入特征的选择和预处理导致模型错误指定(例如,如果数据集的真实决策边界是输入特征的高度非线性函数),它仍然可能校准不佳。
在本示例中,训练集有意保持非常小。在这种设置下,优化对数损失仍可能因过拟合而导致模型校准不佳。为了缓解这种情况,LogisticRegressionCV 类被配置为通过内部交叉验证调整正则化参数 C,以最小化对数损失,从而在此小型训练集设置中为该模型找到最佳折衷方案。
由于训练集大小有限且缺乏良好指定的保证,我们观察到逻辑回归模型的校准曲线接近但并非完美位于对角线上。该模型的校准曲线形状可解释为略微“信心不足”:与真实正样本比例相比,预测概率略微过于接近 0.5。
其他方法输出的概率校准效果均不佳
在这个特定数据集上,
GaussianNB倾向于将概率推向 0 或 1(参见直方图)(过度自信)。这主要是因为朴素贝叶斯方程仅在特征条件独立假设成立时才提供正确的概率估计 [2]。然而,特征可能是相关的,在这个数据集中就是这种情况,它包含两个作为信息特征的随机线性组合生成的特征。这些相关特征实际上被“计算了两次”,导致预测概率趋向于 0 和 1 [3]。但请注意,更改用于生成数据集的种子可能会导致朴素贝叶斯估计器产生截然不同的结果。LinearSVC并非自然的概率分类器。为了将其预测解释为概率,我们简单地将 decision_function 的输出通过上述定义的NaivelyCalibratedLinearSVC封装类中的最小-最大缩放(min-max scaling)转换到 [0, 1] 区间。该估计器在此数据上显示出典型的 S 形校准曲线:大于 0.5 的预测对应于具有更大实际正类别比例的样本(高于对角线),而小于 0.5 的预测则对应于更低的正类别比例(低于对角线)。这种“信心不足”的预测是最大间隔方法的典型特征 [1]。RandomForestClassifier的预测直方图在大约 0.2 和 0.9 概率处显示峰值,而接近 0 或 1 的概率非常罕见。对此的解释由 [1] 给出:“诸如 bagging 和随机森林等从一组基本模型中平均预测的方法,在预测接近 0 和 1 时可能会遇到困难,因为底层基本模型的方差会将应该接近零或一的预测值推离这些值。由于预测值被限制在 [0, 1] 区间内,方差引起的误差在接近零和一处倾向于单侧。例如,如果模型应该预测某个案例的 p = 0,那么 bagging 唯一能实现这一点的方法是所有 bagged 树都预测零。如果我们向 bagging 所平均的树中添加噪声,这种噪声将导致某些树对该案例预测大于 0 的值,从而使 bagging 集成的平均预测偏离 0。我们在随机森林中观察到这种效应最强,因为通过随机森林训练的基础树由于特征子集化而具有相对较高的方差。”这种效应可能使随机森林“信心不足”。尽管存在这种可能的偏差,但请注意,树本身是通过最小化基尼(Gini)或熵(Entropy)标准来拟合的,这两种标准都会导致最小化适当评分规则的分裂:分别是 Brier 分数或对数损失。有关更多详细信息,请参阅用户指南。这可以解释为什么该模型在此特定示例数据集上显示出足够好的校准曲线。事实上,随机森林模型的“信心不足”程度并不比逻辑回归模型显著。
随意使用不同的随机种子和其他数据集生成参数重新运行此示例,以查看校准图可能有多么不同。一般来说,逻辑回归和随机森林往往是校准最佳的分类器,而 SVC 通常会显示典型的“信心不足”的校准不良。朴素贝叶斯模型也经常校准不佳,但其校准曲线的总体形状会因数据集而异。
最后,请注意,对于某些数据集种子,即使如上所述调整了正则化参数,所有模型也可能校准不佳。当训练集大小过小或模型严重错误指定时,这种情况必然会发生。
参考文献#
脚本总运行时间: (0 分 2.941 秒)
相关示例