注意
转到末尾以下载完整示例代码或通过 JupyterLite 或 Binder 在浏览器中运行此示例。
带交叉验证的递归特征消除#
一个递归特征消除 (RFE) 示例,通过交叉验证自动调整选择的特征数量。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
数据生成#
我们使用 3 个信息量大的特征构建了一个分类任务。引入 2 个额外的冗余(即相关)特征导致所选特征根据交叉验证折叠而变化。其余特征是非信息性的,因为它们是随机抽取的。
from sklearn.datasets import make_classification
n_features = 15
feat_names = [f"feature_{i}" for i in range(15)]
X, y = make_classification(
n_samples=500,
n_features=n_features,
n_informative=3,
n_redundant=2,
n_repeated=0,
n_classes=8,
n_clusters_per_class=1,
class_sep=0.8,
random_state=0,
)
模型训练和选择#
我们创建 RFE 对象并计算交叉验证分数。评分策略“准确性”优化了正确分类样本的比例。
from sklearn.feature_selection import RFECV
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import StratifiedKFold
min_features_to_select = 1 # Minimum number of features to consider
clf = LogisticRegression()
cv = StratifiedKFold(5)
rfecv = RFECV(
estimator=clf,
step=1,
cv=cv,
scoring="accuracy",
min_features_to_select=min_features_to_select,
n_jobs=2,
)
rfecv.fit(X, y)
print(f"Optimal number of features: {rfecv.n_features_}")
Optimal number of features: 3
在本例中,具有 3 个特征的模型(对应于真实的生成模型)被发现是最优的。
特征数量与交叉验证分数的关系图#
import matplotlib.pyplot as plt
import pandas as pd
data = {
key: value
for key, value in rfecv.cv_results_.items()
if key in ["n_features", "mean_test_score", "std_test_score"]
}
cv_results = pd.DataFrame(data)
plt.figure()
plt.xlabel("Number of features selected")
plt.ylabel("Mean test accuracy")
plt.errorbar(
x=cv_results["n_features"],
y=cv_results["mean_test_score"],
yerr=cv_results["std_test_score"],
)
plt.title("Recursive Feature Elimination \nwith correlated features")
plt.show()
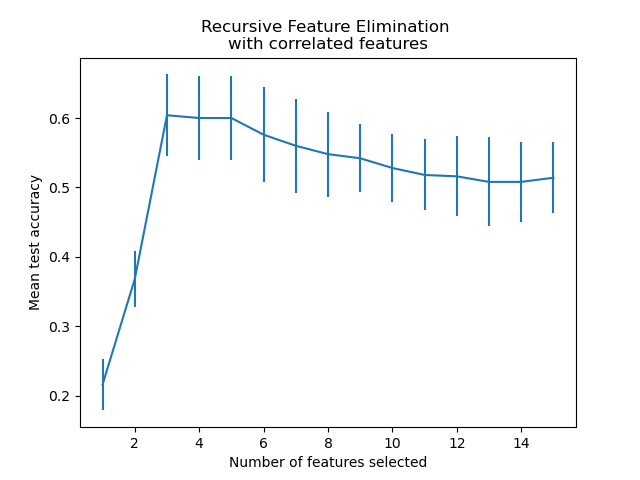
从上图中可以进一步注意到,对于 3 到 5 个所选特征,分数存在一个相等的平台期(相似的平均值和重叠的误差线)。这是引入相关特征的结果。事实上,RFE 选择的最优模型可能位于此范围内,具体取决于交叉验证技术。当所选特征超过 5 个时,测试准确性会下降,这是因为保留非信息性特征会导致过拟合,因此不利于模型的统计性能。
import numpy as np
for i in range(cv.n_splits):
mask = rfecv.cv_results_[f"split{i}_support"][
rfecv.n_features_ - 1
] # mask of features selected by the RFE
features_selected = np.ma.compressed(np.ma.masked_array(feat_names, mask=1 - mask))
print(f"Features selected in fold {i}: {features_selected}")
Features selected in fold 0: ['feature_3' 'feature_4' 'feature_8']
Features selected in fold 1: ['feature_3' 'feature_4' 'feature_8']
Features selected in fold 2: ['feature_3' 'feature_4' 'feature_8']
Features selected in fold 3: ['feature_3' 'feature_4' 'feature_8']
Features selected in fold 4: ['feature_3' 'feature_4' 'feature_8']
在五个折叠中,所选特征是一致的。这是个好消息,这意味着选择在各个折叠中是稳定的,并且它证实了这些特征是最具信息性的特征。
脚本总运行时间: (0 分钟 0.661 秒)
相关示例