部分导航
__sklearn_is_fitted__
FrozenEstimator
set_output
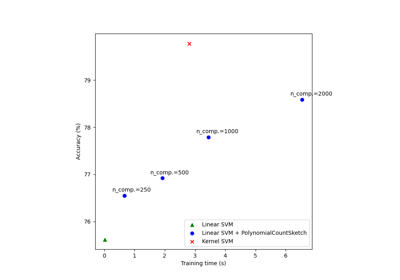
有关 sklearn.kernel_approximation 模块的示例。
sklearn.kernel_approximation
使用多项式核近似进行可扩展学习