部分导航
__sklearn_is_fitted__
FrozenEstimator
set_output
示例展示了分类器预测概率的校准。
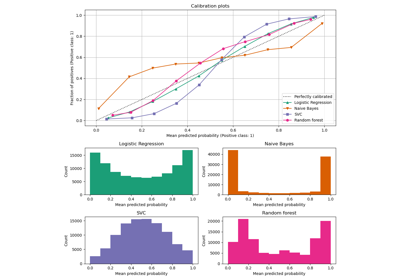
分类器校准比较
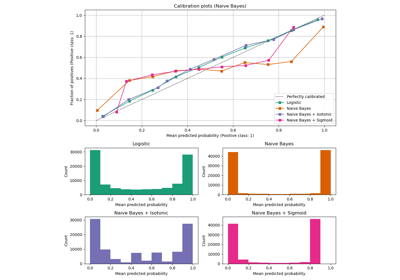
概率校准曲线
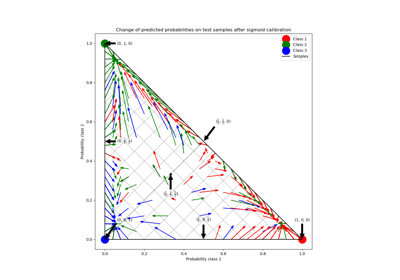
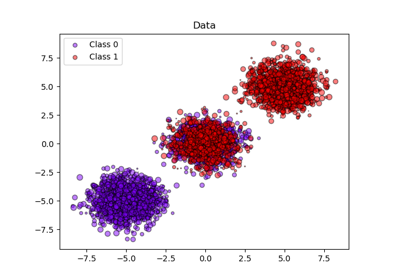
3分类问题的概率校准
分类器的概率校准