注意
转到末尾以下载完整的示例代码,或通过 JupyterLite 或 Binder 在浏览器中运行此示例。
多项式逻辑回归与一对多逻辑回归的决策边界#
本示例比较了在具有三个类别的二维数据集上,多项式逻辑回归和一对多逻辑回归的决策边界。
我们对这两种方法的决策边界进行了比较,这相当于调用 predict 方法。此外,我们绘制了当某个类别的概率估计为 0.5 时对应的超平面线。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
数据集生成#
我们使用 make_blobs 函数生成了一个合成数据集。该数据集包含来自三个不同类别的 1,000 个样本,中心分别为 [-5, 0]、[0, 1.5] 和 [5, -1]。生成后,我们应用线性变换以引入特征之间的一些相关性,使问题更具挑战性。这得到了一个具有三个重叠类别的二维数据集,适合演示多项式逻辑回归和一对多逻辑回归之间的差异。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_blobs
centers = [[-5, 0], [0, 1.5], [5, -1]]
X, y = make_blobs(n_samples=1_000, centers=centers, random_state=40)
transformation = [[0.4, 0.2], [-0.4, 1.2]]
X = np.dot(X, transformation)
fig, ax = plt.subplots(figsize=(6, 4))
scatter = ax.scatter(X[:, 0], X[:, 1], c=y, edgecolor="black")
ax.set(title="Synthetic Dataset", xlabel="Feature 1", ylabel="Feature 2")
_ = ax.legend(*scatter.legend_elements(), title="Classes")
分类器训练#
我们训练了两种不同的逻辑回归分类器:多项式(multinomial)和一对多(one-vs-rest)。多项式分类器同时处理所有类别,而一对多方法则为每个类别训练一个二元分类器,以区分该类别与所有其他类别。
from sklearn.linear_model import LogisticRegression
from sklearn.multiclass import OneVsRestClassifier
logistic_regression_multinomial = LogisticRegression().fit(X, y)
logistic_regression_ovr = OneVsRestClassifier(LogisticRegression()).fit(X, y)
accuracy_multinomial = logistic_regression_multinomial.score(X, y)
accuracy_ovr = logistic_regression_ovr.score(X, y)
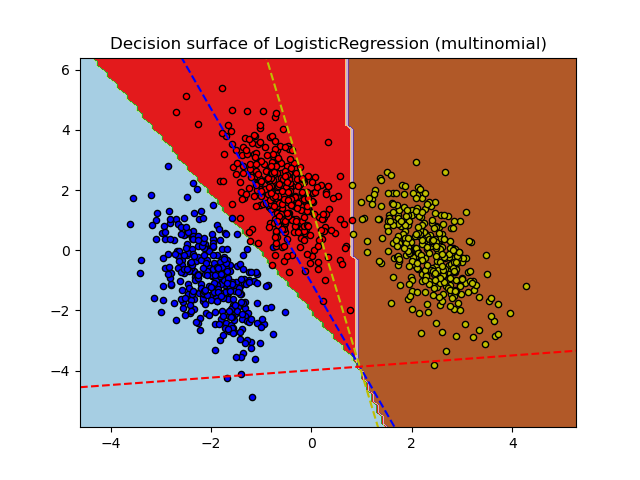
决策边界可视化#
让我们可视化两种模型通过分类器的 predict 方法提供的决策边界。
from sklearn.inspection import DecisionBoundaryDisplay
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5), sharex=True, sharey=True)
for model, title, ax in [
(
logistic_regression_multinomial,
f"Multinomial Logistic Regression\n(Accuracy: {accuracy_multinomial:.3f})",
ax1,
),
(
logistic_regression_ovr,
f"One-vs-Rest Logistic Regression\n(Accuracy: {accuracy_ovr:.3f})",
ax2,
),
]:
DecisionBoundaryDisplay.from_estimator(
model,
X,
ax=ax,
response_method="predict",
alpha=0.8,
)
scatter = ax.scatter(X[:, 0], X[:, 1], c=y, edgecolor="k")
legend = ax.legend(*scatter.legend_elements(), title="Classes")
ax.add_artist(legend)
ax.set_title(title)
我们看到决策边界是不同的。这种差异源于它们的方法:
多项式逻辑回归在优化过程中同时考虑所有类别。
一对多逻辑回归独立地为每个类别拟合一个分类器,以区分该类别与所有其他类别。
这些不同的策略可能导致不同的决策边界,尤其是在复杂的多类别问题中。
超平面可视化#
我们还可视化了当某个类别的概率估计为 0.5 时对应的超平面线。
def plot_hyperplanes(classifier, X, ax):
xmin, xmax = X[:, 0].min(), X[:, 0].max()
ymin, ymax = X[:, 1].min(), X[:, 1].max()
ax.set(xlim=(xmin, xmax), ylim=(ymin, ymax))
if isinstance(classifier, OneVsRestClassifier):
coef = np.concatenate([est.coef_ for est in classifier.estimators_])
intercept = np.concatenate([est.intercept_ for est in classifier.estimators_])
else:
coef = classifier.coef_
intercept = classifier.intercept_
for i in range(coef.shape[0]):
w = coef[i]
a = -w[0] / w[1]
xx = np.linspace(xmin, xmax)
yy = a * xx - (intercept[i]) / w[1]
ax.plot(xx, yy, "--", linewidth=3, label=f"Class {i}")
return ax.get_legend_handles_labels()
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5), sharex=True, sharey=True)
for model, title, ax in [
(
logistic_regression_multinomial,
"Multinomial Logistic Regression Hyperplanes",
ax1,
),
(logistic_regression_ovr, "One-vs-Rest Logistic Regression Hyperplanes", ax2),
]:
hyperplane_handles, hyperplane_labels = plot_hyperplanes(model, X, ax)
scatter = ax.scatter(X[:, 0], X[:, 1], c=y, edgecolor="k")
scatter_handles, scatter_labels = scatter.legend_elements()
all_handles = hyperplane_handles + scatter_handles
all_labels = hyperplane_labels + scatter_labels
ax.legend(all_handles, all_labels, title="Classes")
ax.set_title(title)
plt.show()
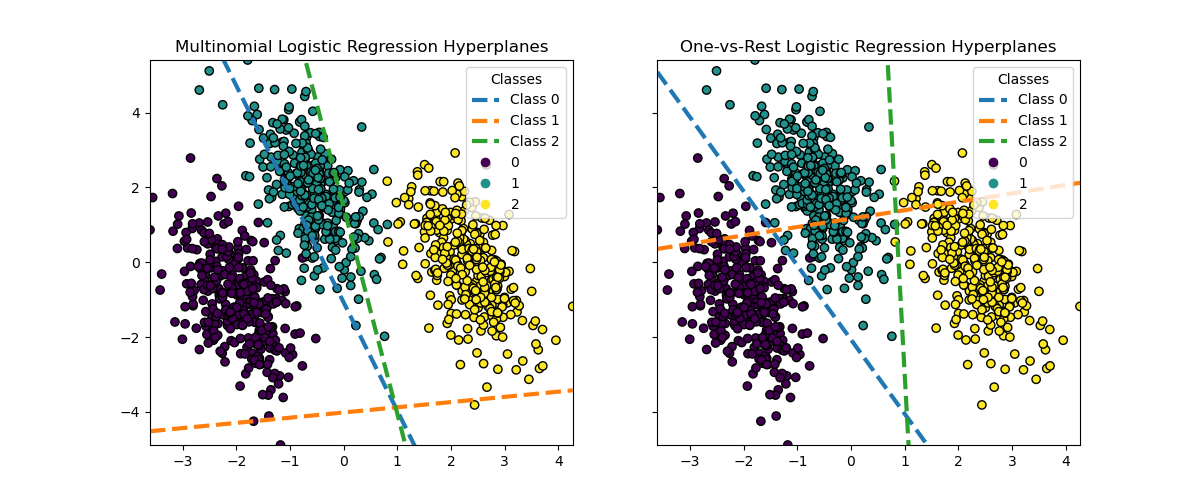
尽管类别 0 和类别 2 的超平面在两种方法之间非常相似,但我们观察到类别 1 的超平面明显不同。这种差异源于一对多逻辑回归和多项式逻辑回归的根本方法:
对于一对多逻辑回归:
每个超平面是独立确定的,通过将一个类别与所有其他类别进行对比。
对于类别 1,超平面表示最佳地将类别 1 与组合类别 0 和 2 分开的决策边界。
这种二元方法可以导致更简单的决策边界,但可能无法同时捕捉所有类别之间的复杂关系。
条件类别概率无法进行有意义的解释。
对于多项式逻辑回归:
所有超平面同时确定,一次性考虑所有类别之间的关系。
模型最小化的损失是适当的评分规则,这意味着模型经过优化以估计条件类别概率,因此这些概率是有意义的。
每个超平面表示一个决策边界,在该边界处,基于整体概率分布,一个类别的概率变得高于其他类别。
这种方法可以捕捉类别之间更细微的关系,可能在多类别问题中带来更准确的分类。
超平面上的差异,尤其是对于类别 1,突出了这些方法如何在整体准确性相似的情况下产生不同的决策边界。
在实践中,建议使用多项式逻辑回归,因为它最小化了一个公式完善的损失函数,从而获得更好校准的类别概率,进而得到更具可解释性的结果。当涉及决策边界时,应该制定一个效用函数,将类别概率转换为当前问题的有意义量。一对多允许不同的决策边界,但不能像效用函数那样对类别之间的权衡进行细粒度控制。
脚本总运行时间: (0 分 0.624 秒)
相关示例