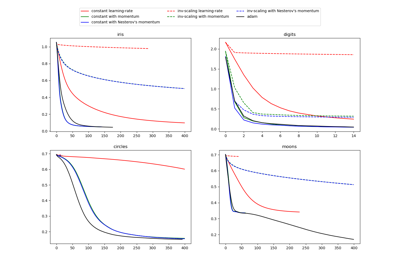
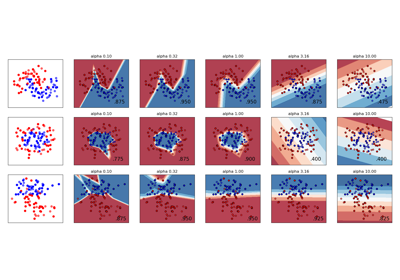
神经网络# 有关 sklearn.neural_network 模块的示例。 比较MLPClassifier的随机学习策略 比较MLPClassifier的随机学习策略 用于数字分类的受限玻尔兹曼机特征 用于数字分类的受限玻尔兹曼机特征 多层感知器中的正则化变化 多层感知器中的正则化变化 MNIST上的MLP权重可视化 MNIST上的MLP权重可视化