注意
跳转到末尾 下载完整示例代码。或通过 JupyterLite 或 Binder 在浏览器中运行此示例
梯度提升回归#
此示例演示了梯度提升如何从弱预测模型的集成中生成预测模型。梯度提升可用于回归和分类问题。在这里,我们将训练一个模型来解决糖尿病回归任务。我们将使用最小二乘损失和 500 棵深度为 4 的回归树从 GradientBoostingRegressor 中获取结果。
注意:对于更大的数据集(n_samples >= 10000),请参考 HistGradientBoostingRegressor。请参阅 直方图梯度提升树中的特征 了解 HistGradientBoostingRegressor 的其他一些优点。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, ensemble
from sklearn.inspection import permutation_importance
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.utils.fixes import parse_version
加载数据#
首先我们需要加载数据。
diabetes = datasets.load_diabetes()
X, y = diabetes.data, diabetes.target
数据预处理#
接下来,我们将把数据集分为 90% 用于训练,其余用于测试。我们还将设置回归模型参数。您可以调整这些参数来观察结果的变化。
n_estimators :将执行的提升阶段数。稍后,我们将绘制偏差与提升迭代次数的关系图。
max_depth :限制树中的节点数量。最佳值取决于输入变量的交互作用。
min_samples_split :拆分内部节点所需的最小样本数。
learning_rate :每棵树的贡献将收缩多少。
loss :要优化的损失函数。在此示例中使用了最小二乘函数,但还有许多其他选项(请参阅 GradientBoostingRegressor )。
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.1, random_state=13
)
params = {
"n_estimators": 500,
"max_depth": 4,
"min_samples_split": 5,
"learning_rate": 0.01,
"loss": "squared_error",
}
拟合回归模型#
现在,我们将初始化梯度提升回归器并用我们的训练数据拟合它。我们还将查看测试数据上的均方误差。
reg = ensemble.GradientBoostingRegressor(**params)
reg.fit(X_train, y_train)
mse = mean_squared_error(y_test, reg.predict(X_test))
print("The mean squared error (MSE) on test set: {:.4f}".format(mse))
The mean squared error (MSE) on test set: 3010.2061
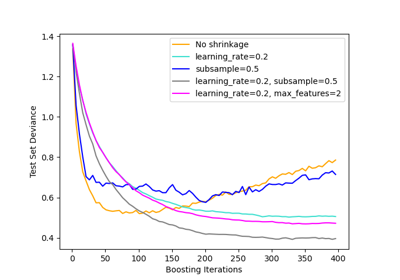
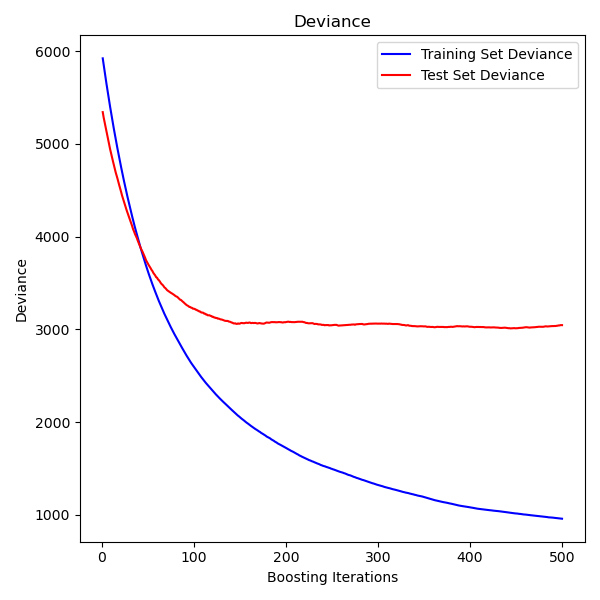
绘制训练偏差#
最后,我们将可视化结果。为此,我们首先计算测试集偏差,然后将其与提升迭代次数绘制成图。
test_score = np.zeros((params["n_estimators"],), dtype=np.float64)
for i, y_pred in enumerate(reg.staged_predict(X_test)):
test_score[i] = mean_squared_error(y_test, y_pred)
fig = plt.figure(figsize=(6, 6))
plt.subplot(1, 1, 1)
plt.title("Deviance")
plt.plot(
np.arange(params["n_estimators"]) + 1,
reg.train_score_,
"b-",
label="Training Set Deviance",
)
plt.plot(
np.arange(params["n_estimators"]) + 1, test_score, "r-", label="Test Set Deviance"
)
plt.legend(loc="upper right")
plt.xlabel("Boosting Iterations")
plt.ylabel("Deviance")
fig.tight_layout()
plt.show()
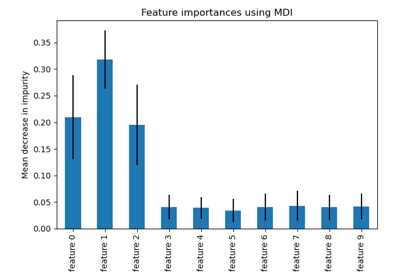
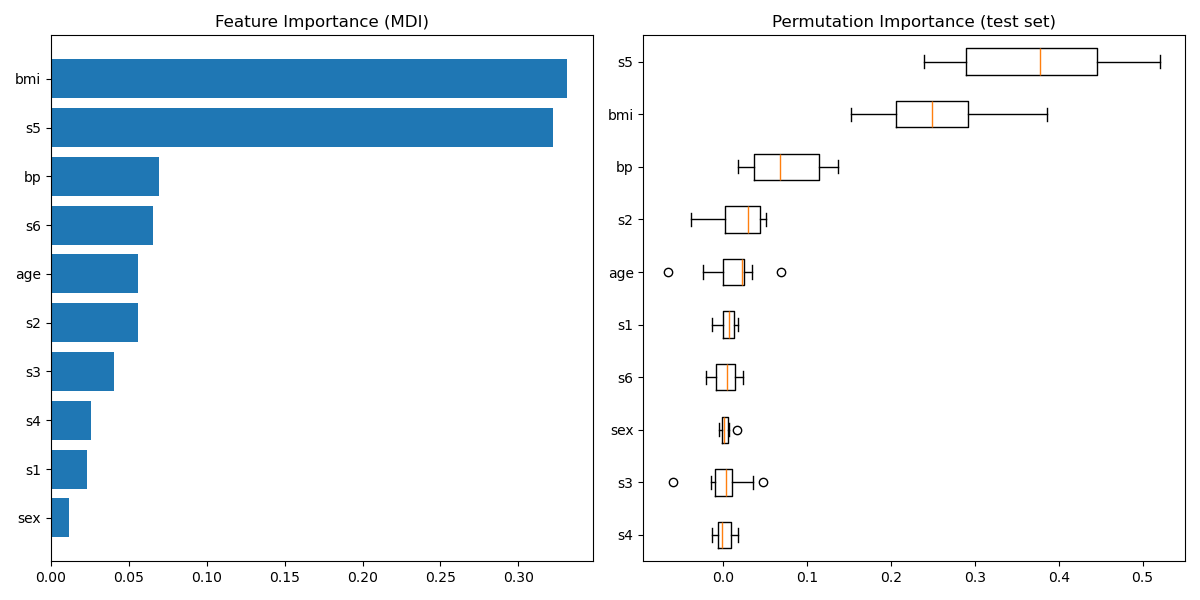
绘制特征重要性#
警告
注意,基于杂质的特征重要性对于 高基数 特征(许多唯一值)可能具有误导性。作为替代方案,reg 的置换重要性可以在保留的测试集上计算。有关更多详细信息,请参阅置换特征重要性。
对于此示例,基于杂质的方法和置换方法识别出相同的 2 个强预测特征,但顺序不同。第三个最具预测性的特征“bp”对于这两种方法也是相同的。其余特征的预测性较低,置换图的误差条显示它们与 0 重叠。
feature_importance = reg.feature_importances_
sorted_idx = np.argsort(feature_importance)
pos = np.arange(sorted_idx.shape[0]) + 0.5
fig = plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.barh(pos, feature_importance[sorted_idx], align="center")
plt.yticks(pos, np.array(diabetes.feature_names)[sorted_idx])
plt.title("Feature Importance (MDI)")
result = permutation_importance(
reg, X_test, y_test, n_repeats=10, random_state=42, n_jobs=2
)
sorted_idx = result.importances_mean.argsort()
plt.subplot(1, 2, 2)
# `labels` argument in boxplot is deprecated in matplotlib 3.9 and has been
# renamed to `tick_labels`. The following code handles this, but as a
# scikit-learn user you probably can write simpler code by using `labels=...`
# (matplotlib < 3.9) or `tick_labels=...` (matplotlib >= 3.9).
tick_labels_parameter_name = (
"tick_labels"
if parse_version(matplotlib.__version__) >= parse_version("3.9")
else "labels"
)
tick_labels_dict = {
tick_labels_parameter_name: np.array(diabetes.feature_names)[sorted_idx]
}
plt.boxplot(result.importances[sorted_idx].T, vert=False, **tick_labels_dict)
plt.title("Permutation Importance (test set)")
fig.tight_layout()
plt.show()
脚本总运行时间: (0 分钟 1.309 秒)
相关示例