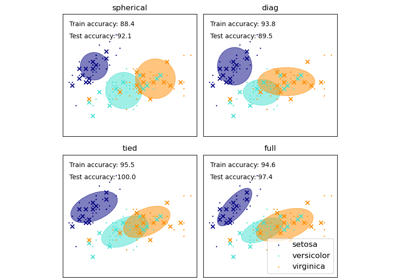
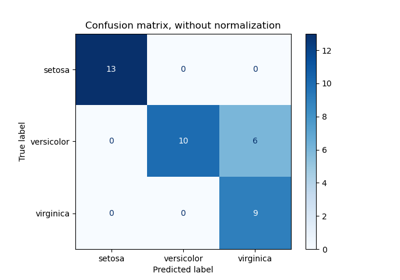
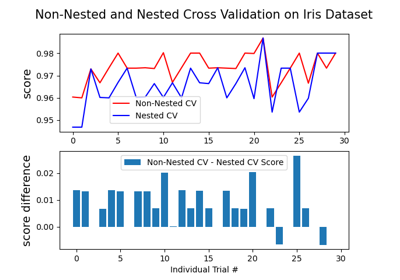
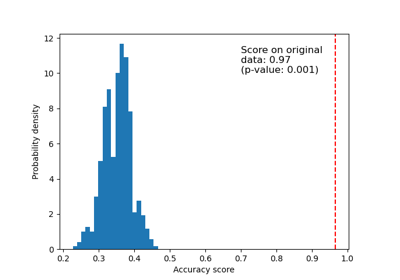
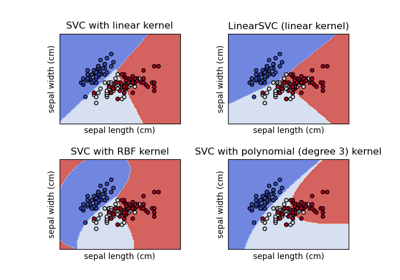
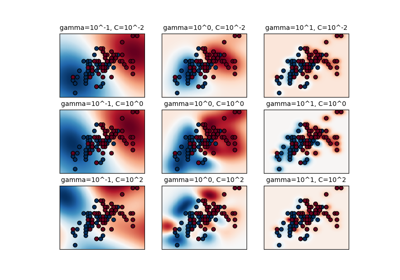
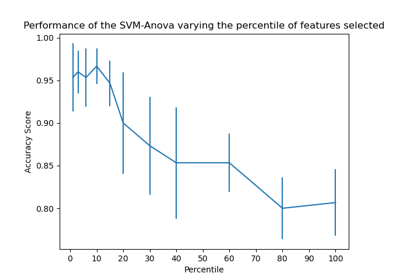
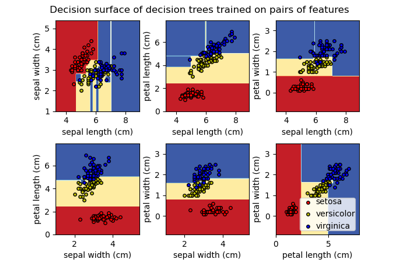
load_iris#
- sklearn.datasets.load_iris(*, return_X_y=False, as_frame=False)[source]#
加载并返回鸢尾花数据集(分类)。
The iris dataset is a classic and very easy multi-class classification dataset.
类别数
3
每类的样本数
50
样本总数
150
维度
4
特征值范围
real, positive
Read more in the User Guide.
Changed in version 0.20: Fixed two wrong data points according to Fisher’s paper. The new version is the same as in R, but not as in the UCI Machine Learning Repository.
- 参数:
- return_X_ybool, default=False
如果为 True,则返回
(data, target)而不是 Bunch 对象。有关data和target对象的更多信息,请参阅下文。版本 0.18 新增。
- as_framebool, default=False
如果为 True,则数据是包含具有相应 dtypes(数字)的列的 pandas DataFrame。目标是 pandas DataFrame 或 Series,具体取决于目标列数。如果
return_X_y为 True,则 (data,target) 将是如下所述的 pandas DataFrames 或 Series。0.23 版本新增。
- 返回:
- data
Bunch Dictionary-like object, with the following attributes.
- data{ndarray, dataframe} of shape (150, 4)
数据矩阵。如果
as_frame=True,data将是一个 pandas DataFrame。- target: {ndarray, Series} of shape (150,)
分类目标。如果
as_frame=True,target将是一个 pandas Series。- feature_names: list
数据集列的名称。
- target_names: ndarray of shape (3, )
The names of target classes.
- frame: DataFrame of shape (150, 5)
仅当
as_frame=True时存在。包含data和target的 DataFrame。0.23 版本新增。
- DESCR: str
The full description of the dataset.
- filename: str
The path to the location of the data.
0.20 版本新增。
- (data, target)tuple if
return_X_yis True 包含两个 ndarray 的元组。第一个包含一个形状为 (n_samples, n_features) 的二维数组,其中每一行代表一个样本,每一列代表特征。第二个 ndarray 的形状为 (n_samples,),包含目标样本。
版本 0.18 新增。
- data
示例
Let’s say you are interested in the samples 10, 25, and 50, and want to know their class name.
>>> from sklearn.datasets import load_iris >>> data = load_iris() >>> samples = [10, 25, 50] >>> data.target[samples] array([0, 0, 1]) >>> data.target_names[data.target[samples]] array(['setosa', 'setosa', 'versicolor'], dtype='<U10')
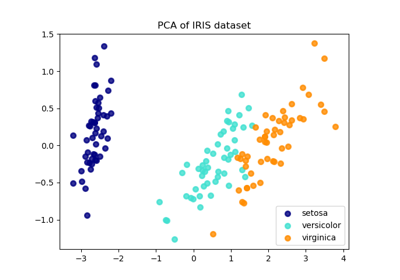
See Principal Component Analysis (PCA) on Iris Dataset for a more detailed example of how to work with the iris dataset.