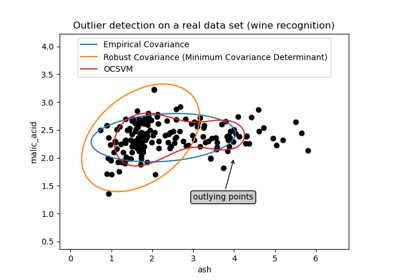
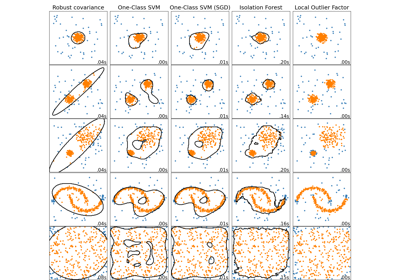
EllipticEnvelope#
- class sklearn.covariance.EllipticEnvelope(*, store_precision=True, assume_centered=False, support_fraction=None, contamination=0.1, random_state=None)[source]#
用于检测高斯分布数据集中异常值的对象。
Read more in the User Guide.
- 参数:
- store_precisionbool, default=True
指定是否存储估计的精度矩阵。
- assume_centeredbool, default=False
If True, the support of robust location and covariance estimates is computed, and a covariance estimate is recomputed from it, without centering the data. Useful to work with data whose mean is significantly equal to zero but is not exactly zero. If False, the robust location and covariance are directly computed with the FastMCD algorithm without additional treatment.
- support_fractionfloat, default=None
The proportion of points to be included in the support of the raw MCD estimate. If None, the minimum value of support_fraction will be used within the algorithm:
(n_samples + n_features + 1) / 2 * n_samples. Range is (0, 1).- contaminationfloat, default=0.1
The amount of contamination of the data set, i.e. the proportion of outliers in the data set. Range is (0, 0.5].
- random_stateint, RandomState instance or None, default=None
Determines the pseudo random number generator for shuffling the data. Pass an int for reproducible results across multiple function calls. See Glossary.
- 属性:
- location_ndarray of shape (n_features,)
Estimated robust location.
- covariance_ndarray of shape (n_features, n_features)
Estimated robust covariance matrix.
- precision_ndarray of shape (n_features, n_features)
估计的伪逆矩阵。(仅当 store_precision 为 True 时存储)
- support_ndarray of shape (n_samples,)
A mask of the observations that have been used to compute the robust estimates of location and shape.
- offset_float
Offset used to define the decision function from the raw scores. We have the relation:
decision_function = score_samples - offset_. The offset depends on the contamination parameter and is defined in such a way we obtain the expected number of outliers (samples with decision function < 0) in training.0.20 版本新增。
- raw_location_ndarray of shape (n_features,)
The raw robust estimated location before correction and re-weighting.
- raw_covariance_ndarray of shape (n_features, n_features)
The raw robust estimated covariance before correction and re-weighting.
- raw_support_ndarray of shape (n_samples,)
A mask of the observations that have been used to compute the raw robust estimates of location and shape, before correction and re-weighting.
- dist_ndarray of shape (n_samples,)
Mahalanobis distances of the training set (on which
fitis called) observations.- n_features_in_int
在 拟合 期间看到的特征数。
0.24 版本新增。
- feature_names_in_shape 为 (
n_features_in_,) 的 ndarray 在 fit 期间看到的特征名称。仅当
X具有全部为字符串的特征名称时才定义。1.0 版本新增。
另请参阅
EmpiricalCovariance最大似然协方差估算器。
GraphicalLasso使用 l1 惩罚估算器进行稀疏逆协方差估计。
LedoitWolfLedoitWolf 估算器。
MinCovDet最小协方差行列式(协方差的稳健估计器)。
OASOracle 近似收缩估算器。
ShrunkCovariance具有收缩的协方差估算器。
注意事项
Outlier detection from covariance estimation may break or not perform well in high-dimensional settings. In particular, one will always take care to work with
n_samples > n_features ** 2.References
[1]Rousseeuw, P.J., Van Driessen, K. “A fast algorithm for the minimum covariance determinant estimator” Technometrics 41(3), 212 (1999)
示例
>>> import numpy as np >>> from sklearn.covariance import EllipticEnvelope >>> true_cov = np.array([[.8, .3], ... [.3, .4]]) >>> X = np.random.RandomState(0).multivariate_normal(mean=[0, 0], ... cov=true_cov, ... size=500) >>> cov = EllipticEnvelope(random_state=0).fit(X) >>> # predict returns 1 for an inlier and -1 for an outlier >>> cov.predict([[0, 0], ... [3, 3]]) array([ 1, -1]) >>> cov.covariance_ array([[0.8102, 0.2736], [0.2736, 0.3330]]) >>> cov.location_ array([0.0769 , 0.0397])
- correct_covariance(data)[source]#
Apply a correction to raw Minimum Covariance Determinant estimates.
Correction using the asymptotic correction factor derived by [Croux1999].
- 参数:
- dataarray-like of shape (n_samples, n_features)
The data matrix, with p features and n samples. The data set must be the one which was used to compute the raw estimates.
- 返回:
- covariance_correctedndarray of shape (n_features, n_features)
Corrected robust covariance estimate.
References
[Croux1999]Influence Function and Efficiency of the Minimum Covariance Determinant Scatter Matrix Estimator, 1999, Journal of Multivariate Analysis, Volume 71, Issue 2, Pages 161-190
- decision_function(X)[source]#
Compute the decision function of the given observations.
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
The data matrix.
- 返回:
- decisionndarray of shape (n_samples,)
Decision function of the samples. It is equal to the shifted Mahalanobis distances. The threshold for being an outlier is 0, which ensures a compatibility with other outlier detection algorithms.
- error_norm(comp_cov, norm='frobenius', scaling=True, squared=True)[source]#
计算两个协方差估计器之间的均方误差。
- 参数:
- comp_covarray-like of shape (n_features, n_features)
用于比较的协方差。
- norm{“frobenius”, “spectral”}, default=”frobenius”
用于计算误差的范数类型。可用的误差类型:- 'frobenius'(默认值):sqrt(tr(A^t.A)) - 'spectral':sqrt(max(eigenvalues(A^t.A)),其中 A 是误差
(comp_cov - self.covariance_)。- scalingbool, default=True
如果为 True(默认值),则将平方误差范数除以 n_features。如果为 False,则不重新缩放平方误差范数。
- squaredbool, default=True
是否计算平方误差范数或误差范数。如果为 True(默认值),则返回平方误差范数。如果为 False,则返回误差范数。
- 返回:
- resultfloat
self和comp_cov协方差估计器之间的均方误差(根据 Frobenius 范数)。
- fit(X, y=None)[source]#
Fit the EllipticEnvelope model.
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
训练数据。
- y被忽略
未使用,按照惯例为保持 API 一致性而存在。
- 返回:
- selfobject
返回实例本身。
- fit_predict(X, y=None, **kwargs)[source]#
Perform fit on X and returns labels for X.
Returns -1 for outliers and 1 for inliers.
- 参数:
- Xshape 为 (n_samples, n_features) 的 {array-like, sparse matrix}
输入样本。
- y被忽略
未使用,按照惯例为保持 API 一致性而存在。
- **kwargsdict
要传递给
fit的参数。1.4 版本新增。
- 返回:
- yndarray of shape (n_samples,)
1 for inliers, -1 for outliers.
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查阅 用户指南,了解路由机制如何工作。
- 返回:
- routingMetadataRequest
封装路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,将返回此估计器以及包含的子对象(如果它们是估计器)的参数。
- 返回:
- paramsdict
参数名称映射到其值。
- get_precision()[source]#
获取精度矩阵。
- 返回:
- precision_array-like of shape (n_features, n_features)
与当前协方差对象关联的精度矩阵。
- mahalanobis(X)[source]#
计算给定观测值的平方马哈拉诺比斯距离。
有关离群值如何影响马哈拉诺比斯距离的详细示例,请参阅稳健协方差估计和马哈拉诺比斯距离相关性。
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
观测值,我们计算其马哈拉诺比斯距离。假定观测值来自与用于拟合的数据相同的分布。
- 返回:
- distndarray of shape (n_samples,)
观测值的平方马哈拉诺比斯距离。
- predict(X)[source]#
Predict labels (1 inlier, -1 outlier) of X according to fitted model.
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
The data matrix.
- 返回:
- is_inlierndarray of shape (n_samples,)
Returns -1 for anomalies/outliers and +1 for inliers.
- reweight_covariance(data)[source]#
Re-weight raw Minimum Covariance Determinant estimates.
Re-weight observations using Rousseeuw’s method (equivalent to deleting outlying observations from the data set before computing location and covariance estimates) described in [RVDriessen].
Corrects the re-weighted covariance to be consistent at the normal distribution, following [Croux1999].
- 参数:
- dataarray-like of shape (n_samples, n_features)
The data matrix, with p features and n samples. The data set must be the one which was used to compute the raw estimates.
- 返回:
- location_reweightedndarray of shape (n_features,)
Re-weighted robust location estimate.
- covariance_reweightedndarray of shape (n_features, n_features)
Re-weighted robust covariance estimate.
- support_reweightedndarray of shape (n_samples,), dtype=bool
A mask of the observations that have been used to compute the re-weighted robust location and covariance estimates.
References
[RVDriessen]A Fast Algorithm for the Minimum Covariance Determinant Estimator, 1999, American Statistical Association and the American Society for Quality, TECHNOMETRICS
[Croux1999]Influence Function and Efficiency of the Minimum Covariance Determinant Scatter Matrix Estimator, 1999, Journal of Multivariate Analysis, Volume 71, Issue 2, Pages 161-190
- score(X, y, sample_weight=None)[source]#
Return the mean accuracy on the given test data and labels.
在多标签分类中,这是子集准确率 (subset accuracy),这是一个严格的指标,因为它要求每个样本的每个标签集都被正确预测。
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
测试样本。
- yshape 为 (n_samples,) 或 (n_samples, n_outputs) 的 array-like
True labels for X.
- sample_weightshape 为 (n_samples,) 的 array-like, default=None
样本权重。
- 返回:
- scorefloat
Mean accuracy of self.predict(X) w.r.t. y.