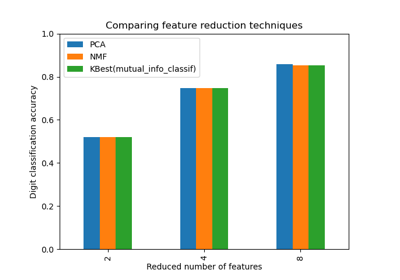
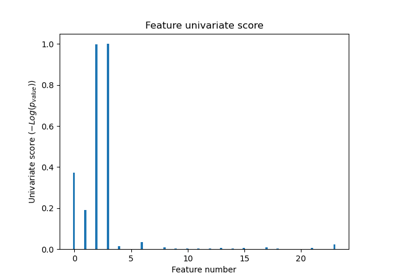
SelectKBest#
- class sklearn.feature_selection.SelectKBest(score_func=<function f_classif>, *, k=10)[source]#
根据 k 个最高分数选择特征。
在用户指南中阅读更多内容。
- 参数:
- score_funccallable, default=f_classif
Function taking two arrays X and y, and returning a pair of arrays (scores, pvalues) or a single array with scores. Default is f_classif (see below “See Also”). The default function only works with classification tasks.
版本 0.18 新增。
- kint or “all”, default=10
Number of top features to select. The “all” option bypasses selection, for use in a parameter search.
- 属性:
- scores_array-like of shape (n_features,)
特征得分。
- pvalues_array-like of shape (n_features,)
p-values of feature scores, None if
score_funcreturned only scores.- n_features_in_int
在 拟合 期间看到的特征数。
0.24 版本新增。
- feature_names_in_shape 为 (
n_features_in_,) 的 ndarray 在 fit 期间看到的特征名称。仅当
X具有全部为字符串的特征名称时才定义。1.0 版本新增。
另请参阅
f_classif分类任务中标签/特征之间的 ANOVA F 值。
mutual_info_classif离散目标的互信息。
chi2分类任务中非负特征的卡方统计量。
f_regression回归任务中标签/特征之间的 F 值。
mutual_info_regression连续目标的互信息。
SelectPercentile根据最高得分的百分位数选择特征。
SelectFpr根据假阳性率测试选择特征。
SelectFdr根据估计的假发现率选择特征。
SelectFwe根据家族错误率选择特征。
GenericUnivariateSelectUnivariate feature selector with configurable mode.
注意事项
Ties between features with equal scores will be broken in an unspecified way.
This filter supports unsupervised feature selection that only requests
Xfor computing the scores.示例
>>> from sklearn.datasets import load_digits >>> from sklearn.feature_selection import SelectKBest, chi2 >>> X, y = load_digits(return_X_y=True) >>> X.shape (1797, 64) >>> X_new = SelectKBest(chi2, k=20).fit_transform(X, y) >>> X_new.shape (1797, 20)
- fit(X, y=None)[source]#
在 (X, y) 上运行得分函数并获取适当的特征。
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
训练输入样本。
- yarray-like of shape (n_samples,) or None
目标值(分类中的类别标签,回归中的实数)。如果选择器是无监督的,则
y可以设置为None。
- 返回:
- selfobject
返回实例本身。
- fit_transform(X, y=None, **fit_params)[source]#
拟合数据,然后对其进行转换。
使用可选参数
fit_params将转换器拟合到X和y,并返回X的转换版本。- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
输入样本。
- y形状为 (n_samples,) 或 (n_samples, n_outputs) 的类数组对象,默认=None
目标值(对于无监督转换,为 None)。
- **fit_paramsdict
额外的拟合参数。仅当估计器在其
fit方法中接受额外的参数时才传递。
- 返回:
- X_newndarray array of shape (n_samples, n_features_new)
转换后的数组。
- get_feature_names_out(input_features=None)[source]#
根据所选特征屏蔽特征名称。
- 参数:
- input_featuresarray-like of str or None, default=None
输入特征。
如果
input_features为None,则使用feature_names_in_作为输入特征名称。如果feature_names_in_未定义,则生成以下输入特征名称:["x0", "x1", ..., "x(n_features_in_ - 1)"]。如果
input_features是 array-like,则如果定义了feature_names_in_,input_features必须与feature_names_in_匹配。
- 返回:
- feature_names_outstr 对象的 ndarray
转换后的特征名称。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查阅 用户指南,了解路由机制如何工作。
- 返回:
- routingMetadataRequest
封装路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,将返回此估计器以及包含的子对象(如果它们是估计器)的参数。
- 返回:
- paramsdict
参数名称映射到其值。
- get_support(indices=False)[source]#
获取所选特征的掩码或整数索引。
- 参数:
- indicesbool, default=False
如果为 True,返回值将是一个整数数组,而不是布尔掩码。
- 返回:
- supportarray
从特征向量中选择保留特征的索引。如果
indices为 False,则这是一个形状为 [# input features] 的布尔数组,其中元素为 True 当且仅当其对应的特征被选中保留。如果indices为 True,则这是一个形状为 [# output features] 的整数数组,其值是输入特征向量中的索引。
- inverse_transform(X)[source]#
反转转换操作。
- 参数:
- Xarray of shape [n_samples, n_selected_features]
输入样本。
- 返回:
- X_originalarray of shape [n_samples, n_original_features]
Xwith columns of zeros inserted where features would have been removed bytransform.
- set_output(*, transform=None)[source]#
设置输出容器。
有关如何使用 API 的示例,请参阅引入 set_output API。
- 参数:
- transform{“default”, “pandas”, “polars”}, default=None
配置
transform和fit_transform的输出。"default": 转换器的默认输出格式"pandas": DataFrame 输出"polars": Polars 输出None: 转换配置保持不变
1.4 版本新增: 添加了
"polars"选项。
- 返回:
- selfestimator instance
估计器实例。