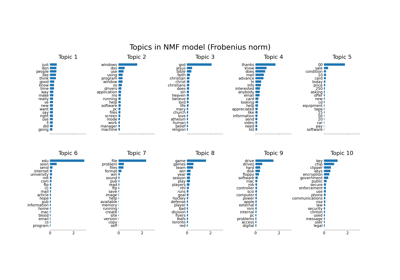
TfidfVectorizer#
- class sklearn.feature_extraction.text.TfidfVectorizer(*, input='content', encoding='utf-8', decode_error='strict', strip_accents=None, lowercase=True, preprocessor=None, tokenizer=None, analyzer='word', stop_words=None, token_pattern='(?u)\\b\\w\\w+\\b', ngram_range=(1, 1), max_df=1.0, min_df=1, max_features=None, vocabulary=None, binary=False, dtype=<class 'numpy.float64'>, norm='l2', use_idf=True, smooth_idf=True, sublinear_tf=False)[source]#
将原始文档集合转换为 TF-IDF 特征矩阵。
等同于先执行
CountVectorizer,再执行TfidfTransformer。在用户指南中了解更多信息。
- 参数:
- input{‘filename’, ‘file’, ‘content’}, default=’content’
如果为
'filename',则传递给 fit 的序列参数预计是一个文件名列表,需要读取这些文件以获取要分析的原始内容。如果为
'file',则序列项必须具有一个 ‘read’ 方法(类似文件对象),该方法用于获取内存中的字节。如果为
'content',则输入预计是类型为字符串或字节的项序列。
- encodingstr, default=’utf-8’
如果给定要分析的字节或文件,则使用此编码进行解码。
- decode_error{‘strict’, ‘ignore’, ‘replace’}, default=’strict’
如果给定要分析的字节序列包含给定
encoding中没有的字符,则应如何处理。默认情况下,它是 ‘strict’,表示将引发 UnicodeDecodeError。其他值为 ‘ignore’ 和 ‘replace’。- strip_accents{‘ascii’, ‘unicode’} or callable, default=None
在预处理步骤中去除重音并执行其他字符规范化。'ascii' 是一种快速方法,仅适用于具有直接 ASCII 映射的字符。'unicode' 是一种稍慢的方法,适用于任何字符。None(默认值)表示不执行字符规范化。
‘ascii’ 和 ‘unicode’ 都使用来自
unicodedata.normalize的 NFKD 规范化。- lowercasebool, default=True
在标记化之前将所有字符转换为小写。
- preprocessorcallable, default=None
覆盖预处理(字符串转换)阶段,同时保留分词和 n-grams 生成步骤。仅当
analyzer不可调用时适用。- tokenizercallable, default=None
覆盖字符串标记化步骤,同时保留预处理和 n-gram 生成步骤。仅当
analyzer == 'word'时适用。- analyzer{‘word’, ‘char’, ‘char_wb’} or callable, default=’word’
特征是应由词语 n-grams 还是字符 n-grams 构成。选项 'char_wb' 仅从词边界内的文本创建字符 n-grams;词边缘的 n-grams 用空格填充。
如果传递可调用对象,则用于从原始、未处理的输入中提取特征序列。
版本 0.21 中的更改:自 v0.21 起,如果
input是'filename'或'file',则数据首先从文件中读取,然后传递给给定的可调用分析器。- stop_words{‘english’}, list, default=None
如果是一个字符串,它会被传递给 _check_stop_list 并返回适当的停用词列表。'english' 是目前唯一支持的字符串值。'english' 存在一些已知问题,您应该考虑替代方案(请参阅使用停用词)。
如果是一个列表,则假定该列表包含停用词,所有这些停用词都将从生成的标记中删除。仅当
analyzer == 'word'时适用。如果为 None,则不使用停用词。在这种情况下,将
max_df设置为更高的值(例如在 (0.7, 1.0) 范围内)可以根据词项在语料库中的文档频率自动检测和过滤停用词。- token_patternstr, default=r”(?u)\b\w\w+\b”
表示“标记”构成内容的正则表达式,仅当
analyzer == 'word'时使用。默认的正则表达式选择由 2 个或更多字母数字字符组成的标记(标点符号被完全忽略,并始终被视为标记分隔符)。如果 token_pattern 中有一个捕获组,则捕获组内容而不是整个匹配项将成为标记。最多允许一个捕获组。
- ngram_rangetuple (min_n, max_n), default=(1, 1)
提取不同 n-grams 的 n 值范围的下限和上限。所有满足 min_n <= n <= max_n 的 n 值都将被使用。例如,
ngram_range为(1, 1)意味着只使用 unigrams,(1, 2)意味着使用 unigrams 和 bigrams,而(2, 2)意味着只使用 bigrams。仅当analyzer不可调用时适用。- max_dffloat or int, default=1.0
在构建词汇表时,忽略文档频率严格高于给定阈值(特定于语料库的停用词)的词项。如果浮点值在 [0.0, 1.0] 范围内,则该参数表示文档的比例,如果是整数,则表示绝对计数。如果 vocabulary 不为 None,则忽略此参数。
- min_dffloat or int, default=1
在构建词汇表时,忽略文档频率严格低于给定阈值的词项。这个值在文献中也称为截止值 (cut-off)。如果浮点值在 [0.0, 1.0] 范围内,则该参数表示文档的比例,如果是整数,则表示绝对计数。如果 vocabulary 不为 None,则忽略此参数。
- max_featuresint, default=None
如果不是 None,则构建一个只考虑按语料库中词频排序的前
max_features个词项的词汇表。否则,使用所有特征。如果 vocabulary 不为 None,则忽略此参数。
- vocabularyMapping or iterable, default=None
可以是 Mapping(例如 dict),其中键是词项,值是特征矩阵中的索引,也可以是包含词项的可迭代对象。如果未给出,则根据输入文档确定词汇表。
- binarybool, default=False
如果为 True,则所有非零词项计数都设置为 1。这并不意味着输出将只有 0/1 值,只是 tf-idf 中的 tf 词项是二元的。(将
binary设置为 True,use_idf设置为 False,norm设置为 None 以获得 0/1 输出)。- dtypedtype, default=float64
fit_transform() 或 transform() 返回的矩阵类型。
- norm{‘l1’, ‘l2’} or None, default=’l2’
每行输出将具有单位范数,可以是
'l2': 向量元素的平方和为 1。当应用 l2 范数后,两个向量之间的余弦相似度就是它们的点积。
'l1': 向量元素的绝对值之和为 1。请参阅
normalize。None: 不进行规范化。
- use_idfbool, default=True
启用逆文档频率重新加权。如果为 False,则 idf(t) = 1。
- smooth_idfbool, default=True
通过向文档频率加一来平滑 idf 权重,就好像看到了一个包含集合中每个词项恰好一次的额外文档。防止零除。
- sublinear_tfbool, default=False
应用次线性 tf 缩放,即用 1 + log(tf) 替换 tf。
- 属性:
- vocabulary_dict
词项到特征索引的映射。
- fixed_vocabulary_bool
如果用户提供了固定的词项到索引映射的词汇表,则为 True。
idf_shape 为 (n_features,) 的数组逆文档频率向量,仅当
use_idf=True时定义。
另请参阅
CountVectorizer将文本转换为 n-gram 计数的稀疏矩阵。
TfidfTransformer从提供的计数矩阵执行 TF-IDF 转换。
示例
>>> from sklearn.feature_extraction.text import TfidfVectorizer >>> corpus = [ ... 'This is the first document.', ... 'This document is the second document.', ... 'And this is the third one.', ... 'Is this the first document?', ... ] >>> vectorizer = TfidfVectorizer() >>> X = vectorizer.fit_transform(corpus) >>> vectorizer.get_feature_names_out() array(['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this'], ...) >>> print(X.shape) (4, 9)
- build_analyzer()[source]#
返回一个可调用对象来处理输入数据。
此可调用对象处理预处理、标记化和 n-gram 生成。
- 返回:
- analyzer: callable
用于处理预处理、标记化和 n-gram 生成的函数。
- decode(doc)[source]#
将输入解码为 unicode 符号字符串。
解码策略取决于 vectorizer 参数。
- 参数:
- docbytes or str
要解码的字符串。
- 返回:
- doc: str
unicode 符号字符串。
- fit(raw_documents, y=None)[source]#
从训练集学习词汇表和 idf。
- 参数:
- raw_documentsiterable
生成 str、unicode 或文件对象的可迭代对象。
- yNone
计算 tfidf 不需要此参数。
- 返回:
- selfobject
拟合后的向量化器。
- fit_transform(raw_documents, y=None)[source]#
学习词汇表和 idf,返回文档-词项矩阵。
这等同于先 fit 后 transform,但实现效率更高。
- 参数:
- raw_documentsiterable
生成 str、unicode 或文件对象的可迭代对象。
- yNone
此参数被忽略。
- 返回:
- Xshape 为 (n_samples, n_features) 的稀疏矩阵
tf-idf 加权的文档-词项矩阵。
- get_feature_names_out(input_features=None)[source]#
获取转换的输出特征名称。
- 参数:
- input_featuresarray-like of str or None, default=None
Not used, present here for API consistency by convention.
- 返回:
- feature_names_outstr 对象的 ndarray
转换后的特征名称。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查阅 用户指南,了解路由机制如何工作。
- 返回:
- routingMetadataRequest
封装路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,将返回此估计器以及包含的子对象(如果它们是估计器)的参数。
- 返回:
- paramsdict
参数名称映射到其值。
- inverse_transform(X)[source]#
返回 X 中非零项的每文档词项。
- 参数:
- Xshape 为 (n_samples, n_features) 的 {array-like, sparse matrix}
文档-词项矩阵。
- 返回:
- X_originalshape 为 (n_samples,) 的数组列表
词项数组列表。