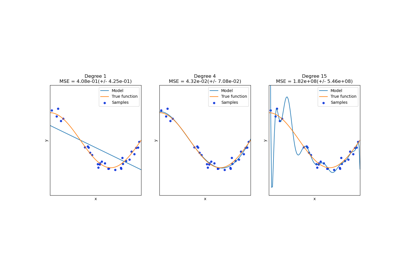
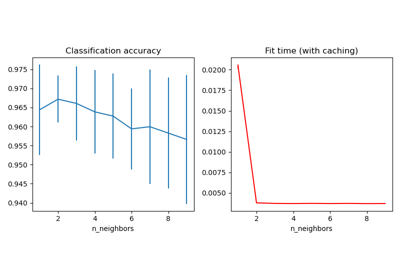
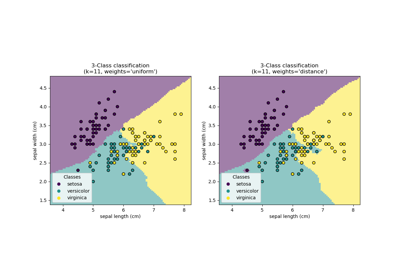
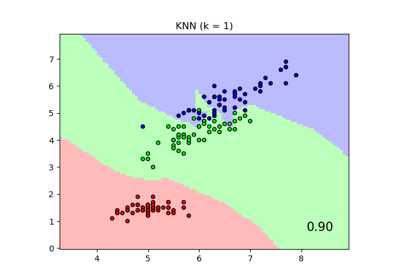
Pipeline#
- class sklearn.pipeline.Pipeline(steps, *, transform_input=None, memory=None, verbose=False)[source]#
一个数据转换器序列,可选择包含一个最终预测器。
Pipeline允许您按顺序应用一系列转换器来预处理数据,并且如果需要,以一个最终的 预测器 结束序列,用于预测建模。Pipeline 的中间步骤必须是转换器,也就是说,它们必须实现 `fit` 和 `transform` 方法。最终的 估计器 只需实现 `fit`。Pipeline 中的转换器可以使用 `memory` 参数进行缓存。
Pipeline 的目的是将多个步骤组合在一起,以便在设置不同参数的同时进行交叉验证。为此,它允许使用步骤名称和参数名称(通过 `__` 分隔)来设置各个步骤的参数,如下面的示例所示。通过将其参数名设置为另一个估计器,可以完全替换某个步骤的估计器;或者通过将其设置为 `passthrough` 或 `None` 来移除转换器。
关于 `Pipeline` 与
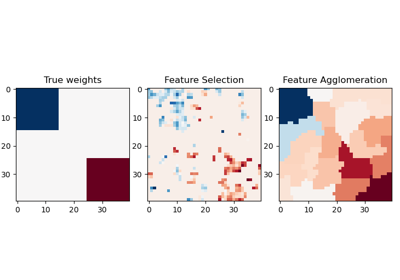
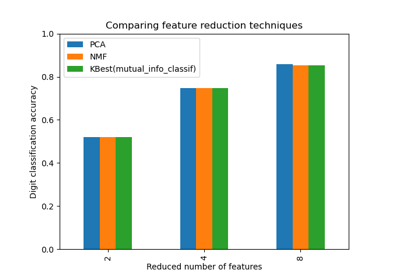
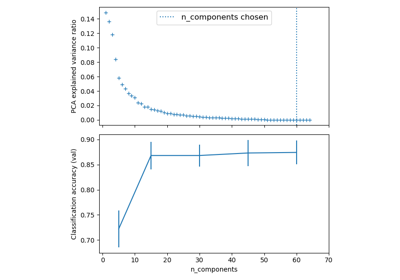
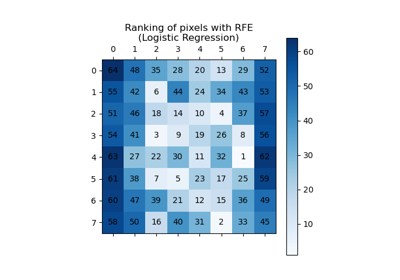
GridSearchCV结合使用的示例,请参阅使用 Pipeline 和 GridSearchCV 选择降维方法。示例管道化:链式连接 PCA 和逻辑回归 展示了如何使用 `__` 作为参数名称中的分隔符对 Pipeline 进行网格搜索。在用户指南中了解更多信息。
0.5 版本新增。
- 参数:
- steps元组列表
按顺序链式连接的 (步骤名称, 估计器) 元组列表。为了与 scikit-learn API 兼容,所有步骤都必须定义 `fit`。所有非最后一步也必须定义 `transform`。有关更多详细信息,请参阅组合估计器。
- transform_input字符串列表, 默认值=None
在将其传递给消费它的步骤之前,应由 pipeline 转换的 元数据 参数的名称。
这使得 `fit` 的某些输入参数(除了 `X`)可以被 pipeline 的步骤转换,直到需要它们的步骤。要求通过元数据路由定义。例如,这可以用于将验证集通过 pipeline 传递。
您只能在启用元数据路由时设置此项,您可以使用 `sklearn.set_config(enable_metadata_routing=True)` 来启用它。
1.6 版本新增。
- memory字符串或具有 joblib.Memory 接口的对象, 默认值=None
用于缓存 pipeline 中已拟合的转换器。最后一步永远不会被缓存,即使它是一个转换器。默认情况下,不执行缓存。如果给定一个字符串,它是缓存目录的路径。启用缓存会在拟合之前触发转换器的克隆。因此,不能直接检查给到 pipeline 的转换器实例。使用属性 `named_steps` 或 `steps` 来检查 pipeline 中的估计器。当拟合耗时时,缓存转换器是有利的。有关如何启用缓存的示例,请参阅缓存最近邻居。
- verbose布尔值, 默认值=False
如果为 True,则在每个步骤完成后会打印其拟合所用的时间。
- 属性:
named_stepsBunch按名称访问步骤。
classes_形状为 (n_classes,) 的 ndarray类别标签。
n_features_in_整数在第一个步骤 `fit` 方法期间看到的特征数量。
feature_names_in_形状为 (`n_features_in_`,) 的 ndarray在第一个步骤 `fit` 方法期间看到的特征名称。
另请参阅
make_pipeline简化 pipeline 构造的便利函数。
示例
>>> from sklearn.svm import SVC >>> from sklearn.preprocessing import StandardScaler >>> from sklearn.datasets import make_classification >>> from sklearn.model_selection import train_test_split >>> from sklearn.pipeline import Pipeline >>> X, y = make_classification(random_state=0) >>> X_train, X_test, y_train, y_test = train_test_split(X, y, ... random_state=0) >>> pipe = Pipeline([('scaler', StandardScaler()), ('svc', SVC())]) >>> # The pipeline can be used as any other estimator >>> # and avoids leaking the test set into the train set >>> pipe.fit(X_train, y_train).score(X_test, y_test) 0.88 >>> # An estimator's parameter can be set using '__' syntax >>> pipe.set_params(svc__C=10).fit(X_train, y_train).score(X_test, y_test) 0.76
- decision_function(X, **params)[source]#
转换数据,并使用最终估计器应用 `decision_function`。
调用 pipeline 中每个转换器的 `transform` 方法。转换后的数据最终传递给调用 `decision_function` 方法的最终估计器。仅当最终估计器实现 `decision_function` 时才有效。
- 参数:
- X可迭代对象
用于预测的数据。必须满足 pipeline 第一个步骤的输入要求。
- **params字符串到对象的字典
步骤请求和接受的参数。每个步骤都必须请求某些元数据,以便将这些参数转发给它们。
1.4 版本新增: 仅当 `enable_metadata_routing=True` 时可用。有关更多详细信息,请参阅元数据路由用户指南。
- 返回:
- y_score形状为 (n_samples, n_classes) 的 ndarray
在最终估计器上调用 `decision_function` 的结果。
- fit(X, y=None, **params)[source]#
拟合模型。
依次拟合所有转换器并按顺序转换数据。最后,使用最终估计器拟合转换后的数据。
- 参数:
- X可迭代对象
训练数据。必须满足 pipeline 第一个步骤的输入要求。
- y可迭代对象, 默认值=None
训练目标。必须满足 pipeline 所有步骤的标签要求。
- **params字符串到对象的字典
如果 `enable_metadata_routing=False` (默认):传递给每个步骤 `fit` 方法的参数,其中每个参数名称都带有前缀,因此步骤 `s` 的参数 `p` 具有键 `s__p`。
如果 `enable_metadata_routing=True`:步骤请求和接受的参数。每个步骤都必须请求某些元数据,以便将这些参数转发给它们。
1.4 版本变化: 如果已请求,并且通过
set_config设置了 `enable_metadata_routing=True`,参数现在也会传递给中间步骤的 `transform` 方法。有关更多详细信息,请参阅元数据路由用户指南。
- 返回:
- self对象
带有已拟合步骤的 Pipeline。
- fit_predict(X, y=None, **params)[source]#
转换数据,并使用最终估计器应用 `fit_predict`。
调用 pipeline 中每个转换器的 `fit_transform` 方法。转换后的数据最终传递给调用 `fit_predict` 方法的最终估计器。仅当最终估计器实现 `fit_predict` 时才有效。
- 参数:
- X可迭代对象
训练数据。必须满足 pipeline 第一个步骤的输入要求。
- y可迭代对象, 默认值=None
训练目标。必须满足 pipeline 所有步骤的标签要求。
- **params字符串到对象的字典
如果 `enable_metadata_routing=False` (默认):传递给 pipeline 中所有转换结束时调用的 `predict` 的参数。
如果 `enable_metadata_routing=True`:步骤请求和接受的参数。每个步骤都必须请求某些元数据,以便将这些参数转发给它们。
0.20 版本新增。
1.4 版本变化: 如果已请求,并且设置了 `enable_metadata_routing=True`,参数现在也会传递给中间步骤的 `transform` 方法。
有关更多详细信息,请参阅元数据路由用户指南。
请注意,虽然这可用于从某些模型中返回具有 `return_std` 或 `return_cov` 的不确定性,但 pipeline 中转换生成的不确定性不会传播到最终估计器。
- 返回:
- y_predndarray
在最终估计器上调用 `fit_predict` 的结果。
- fit_transform(X, y=None, **params)[source]#
拟合模型并使用最终估计器进行转换。
依次拟合所有转换器并按顺序转换数据。仅当最终估计器实现 `fit_transform` 或同时实现 `fit` 和 `transform` 时才有效。
- 参数:
- X可迭代对象
训练数据。必须满足 pipeline 第一个步骤的输入要求。
- y可迭代对象, 默认值=None
训练目标。必须满足 pipeline 所有步骤的标签要求。
- **params字符串到对象的字典
如果 `enable_metadata_routing=False` (默认):传递给每个步骤 `fit` 方法的参数,其中每个参数名称都带有前缀,因此步骤 `s` 的参数 `p` 具有键 `s__p`。
如果 `enable_metadata_routing=True`:步骤请求和接受的参数。每个步骤都必须请求某些元数据,以便将这些参数转发给它们。
1.4 版本变化: 如果已请求,并且设置了 `enable_metadata_routing=True`,参数现在也会传递给中间步骤的 `transform` 方法。
有关更多详细信息,请参阅元数据路由用户指南。
- 返回:
- Xt形状为 (n_samples, n_transformed_features) 的 ndarray
转换后的样本。
- get_feature_names_out(input_features=None)[source]#
获取转换后的输出特征名称。
使用 pipeline 转换输入特征。
- 参数:
- input_features类数组字符串或 None, 默认值=None
输入特征。
- 返回:
- feature_names_out字符串对象的 ndarray
转换后的特征名称。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查看用户指南,了解路由机制的工作原理。
- 返回:
- routingMetadataRouter
一个封装路由信息的
MetadataRouter对象。
- get_params(deep=True)[source]#
获取此估计器的参数。
返回构造函数中给定的参数以及 `Pipeline` 的 `steps` 中包含的估计器。
- 参数:
- deep布尔值, 默认值=True
如果为 True,将返回此估计器及其包含的作为估计器的子对象的参数。
- 返回:
- params字符串到任意值的映射
参数名称映射到其值。
- inverse_transform(X, **params)[source]#
以相反顺序为每个步骤应用 `inverse_transform`。
Pipeline 中的所有估计器都必须支持 `inverse_transform`。
- 参数:
- X形状为 (n_samples, n_transformed_features) 的类数组对象
数据样本,其中 `n_samples` 是样本数量,`n_features` 是特征数量。必须满足 pipeline 最后一步的 `inverse_transform` 方法的输入要求。
- **params字符串到对象的字典
步骤请求和接受的参数。每个步骤都必须请求某些元数据,以便将这些参数转发给它们。
1.4 版本新增: 仅当 `enable_metadata_routing=True` 时可用。有关更多详细信息,请参阅元数据路由用户指南。
- 返回:
- X_original形状为 (n_samples, n_features) 的 ndarray
逆变换后的数据,即原始特征空间中的数据。
- property named_steps#
按名称访问步骤。
只读属性,用于按给定名称访问任何步骤。键是步骤名称,值是步骤对象。
- predict(X, **params)[source]#
转换数据,并使用最终估计器应用 `predict`。
调用 pipeline 中每个转换器的 `transform` 方法。转换后的数据最终传递给调用 `predict` 方法的最终估计器。仅当最终估计器实现 `predict` 时才有效。
- 参数:
- X可迭代对象
用于预测的数据。必须满足 pipeline 第一个步骤的输入要求。
- **params字符串到对象的字典
如果 `enable_metadata_routing=False` (默认):传递给 pipeline 中所有转换结束时调用的 `predict` 的参数。
如果 `enable_metadata_routing=True`:步骤请求和接受的参数。每个步骤都必须请求某些元数据,以便将这些参数转发给它们。
0.20 版本新增。
1.4 版本变化: 如果已请求,并且通过
set_config设置了 `enable_metadata_routing=True`,参数现在也会传递给中间步骤的 `transform` 方法。有关更多详细信息,请参阅元数据路由用户指南。
请注意,虽然这可用于从某些模型中返回具有 `return_std` 或 `return_cov` 的不确定性,但 pipeline 中转换生成的不确定性不会传播到最终估计器。
- 返回:
- y_predndarray
在最终估计器上调用 `predict` 的结果。
- predict_log_proba(X, **params)[source]#
转换数据,并使用最终估计器应用 `predict_log_proba`。
调用 pipeline 中每个转换器的 `transform` 方法。转换后的数据最终传递给调用 `predict_log_proba` 方法的最终估计器。仅当最终估计器实现 `predict_log_proba` 时才有效。
- 参数:
- X可迭代对象
用于预测的数据。必须满足 pipeline 第一个步骤的输入要求。
- **params字符串到对象的字典
如果 `enable_metadata_routing=False` (默认):传递给 pipeline 中所有转换结束时调用的 `predict_log_proba` 的参数。
如果 `enable_metadata_routing=True`:步骤请求和接受的参数。每个步骤都必须请求某些元数据,以便将这些参数转发给它们。
0.20 版本新增。
1.4 版本变化: 如果已请求,并且设置了 `enable_metadata_routing=True`,参数现在也会传递给中间步骤的 `transform` 方法。
有关更多详细信息,请参阅元数据路由用户指南。
- 返回:
- y_log_proba形状为 (n_samples, n_classes) 的 ndarray
在最终估计器上调用 `predict_log_proba` 的结果。
- predict_proba(X, **params)[source]#
转换数据,并使用最终估计器应用 `predict_proba`。
调用 pipeline 中每个转换器的 `transform` 方法。转换后的数据最终传递给调用 `predict_proba` 方法的最终估计器。仅当最终估计器实现 `predict_proba` 时才有效。
- 参数:
- X可迭代对象
用于预测的数据。必须满足 pipeline 第一个步骤的输入要求。
- **params字符串到对象的字典
如果 `enable_metadata_routing=False` (默认):传递给 pipeline 中所有转换结束时调用的 `predict_proba` 的参数。
如果 `enable_metadata_routing=True`:步骤请求和接受的参数。每个步骤都必须请求某些元数据,以便将这些参数转发给它们。
0.20 版本新增。
1.4 版本变化: 如果已请求,并且设置了 `enable_metadata_routing=True`,参数现在也会传递给中间步骤的 `transform` 方法。
有关更多详细信息,请参阅元数据路由用户指南。
- 返回:
- y_proba形状为 (n_samples, n_classes) 的 ndarray
在最终估计器上调用 `predict_proba` 的结果。
- score(X, y=None, sample_weight=None, **params)[source]#
转换数据,并使用最终估计器应用 `score`。
调用 pipeline 中每个转换器的 `transform` 方法。转换后的数据最终传递给调用 `score` 方法的最终估计器。仅当最终估计器实现 `score` 时才有效。
- 参数:
- X可迭代对象
用于预测的数据。必须满足 pipeline 第一个步骤的输入要求。
- y可迭代对象, 默认值=None
用于评分的目标。必须满足 pipeline 所有步骤的标签要求。
- sample_weight类数组对象, 默认值=None
如果不是 None,此参数将作为 `sample_weight` 关键字参数传递给最终估计器的 `score` 方法。
- **params字符串到对象的字典
步骤请求和接受的参数。每个步骤都必须请求某些元数据,以便将这些参数转发给它们。
1.4 版本新增: 仅当 `enable_metadata_routing=True` 时可用。有关更多详细信息,请参阅元数据路由用户指南。
- 返回:
- score浮点数
在最终估计器上调用 `score` 的结果。
- score_samples(X)[source]#
转换数据,并使用最终估计器应用 `score_samples`。
调用 pipeline 中每个转换器的 `transform` 方法。转换后的数据最终传递给调用 `score_samples` 方法的最终估计器。仅当最终估计器实现 `score_samples` 时才有效。
- 参数:
- X可迭代对象
用于预测的数据。必须满足 pipeline 第一个步骤的输入要求。
- 返回:
- y_score形状为 (n_samples,) 的 ndarray
在最终估计器上调用 `score_samples` 的结果。
- set_output(*, transform=None)[source]#
设置调用 `transform` 和 `fit_transform` 时的输出容器。
调用 `set_output` 将设置 `steps` 中所有估计器的输出。
- 参数:
- transform{“default”, “pandas”, “polars”}, 默认值=None
配置 `transform` 和 `fit_transform` 的输出。
`"default"`: 转换器的默认输出格式
`"pandas"`: DataFrame 输出
`"polars"`: Polars 输出
`None`: 转换配置保持不变
1.4 版本新增: 增加了 `polars` 选项。
- 返回:
- self估计器实例
估计器实例。
- set_params(**kwargs)[source]#
设置此估计器的参数。
有效参数键可以通过 `get_params()` 列出。请注意,您可以直接设置 `steps` 中包含的估计器的参数。
- 参数:
- **kwargs字典
此估计器的参数或 `steps` 中包含的估计器的参数。步骤的参数可以使用其名称和通过 `__` 分隔的参数名称进行设置。
- 返回:
- self对象
Pipeline 类实例。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') Pipeline[source]#
请求传递给 `score` 方法的元数据。
请注意,此方法仅在 `enable_metadata_routing=True`(参阅
sklearn.set_config)时才相关。请参阅用户指南,了解路由机制的工作原理。每个参数的选项为
`True`: 请求元数据,如果提供了则传递给 `score`。如果未提供元数据,则忽略该请求。
`False`: 不请求元数据,并且元估计器不会将其传递给 `score`。
`None`: 不请求元数据,如果用户提供,元估计器将引发错误。
`str`: 元数据应以给定的别名而不是原始名称传递给元估计器。
默认值 (`sklearn.utils.metadata_routing.UNCHANGED`) 保留现有请求。这允许您更改某些参数的请求而不更改其他参数。
1.3 版本新增。
注意
此方法仅当此估计器用作元估计器的子估计器时才相关,例如在
Pipeline内部使用时。否则它没有效果。- 参数:
- sample_weight字符串, True, False, 或 None, 默认值=sklearn.utils.metadata_routing.UNCHANGED
`score` 方法中 `sample_weight` 参数的元数据路由。
- 返回:
- self对象
更新后的对象。
- transform(X, **params)[source]#
转换数据,并使用最终估计器应用 `transform`。
调用 pipeline 中每个转换器的 `transform` 方法。转换后的数据最终传递给调用 `transform` 方法的最终估计器。仅当最终估计器实现 `transform` 时才有效。
这也适用于最终估计器为 `None` 的情况,此时所有先前的转换都将被应用。
- 参数:
- X可迭代对象
要转换的数据。必须满足 pipeline 第一个步骤的输入要求。
- **params字符串到对象的字典
步骤请求和接受的参数。每个步骤都必须请求某些元数据,以便将这些参数转发给它们。
1.4 版本新增: 仅当 `enable_metadata_routing=True` 时可用。有关更多详细信息,请参阅元数据路由用户指南。
- 返回:
- Xt形状为 (n_samples, n_transformed_features) 的 ndarray
转换后的数据。