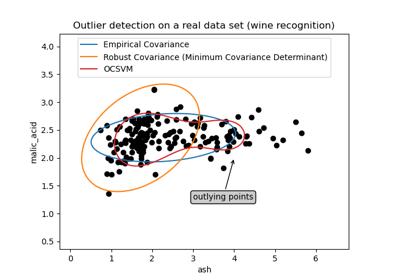
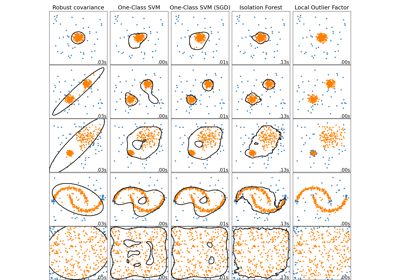
EllipticEnvelope#
- class sklearn.covariance.EllipticEnvelope(*, store_precision=True, assume_centered=False, support_fraction=None, contamination=0.1, random_state=None)[source]#
用于在高斯分布数据集中检测异常值的对象。
欲了解更多信息,请阅读用户指南。
- 参数:
- store_precision布尔值,默认值=True
指定是否存储估计的精度。
- assume_centered布尔值,默认值=False
如果为True,则计算鲁棒位置和协方差估计的支持集,并从中重新计算协方差估计,而不对数据进行中心化。这对于平均值显著等于零但不完全为零的数据集非常有用。如果为False,则直接使用FastMCD算法计算鲁棒位置和协方差,无需额外处理。
- support_fraction浮点数,默认值=None
原始MCD估计支持集中的点所占比例。如果为None,算法将使用support_fraction的最小值:
(n_samples + n_features + 1) / 2 * n_samples。范围为(0, 1)。- contamination浮点数,默认值=0.1
数据集的污染量,即数据集中异常值的比例。范围为(0, 0.5]。
- random_state整型、RandomState实例或None,默认值=None
确定用于打乱数据的伪随机数生成器。传入一个整数可以在多次函数调用中获得可重现的结果。请参阅术语表。
- 属性:
- location_形状为 (n_features,) 的ndarray
估计的鲁棒位置。
- covariance_形状为 (n_features, n_features) 的ndarray
估计的鲁棒协方差矩阵。
- precision_形状为 (n_features, n_features) 的ndarray
估计的伪逆矩阵。(仅当 store_precision 为 True 时存储)
- support_形状为 (n_samples,) 的ndarray
用于计算位置和形状的鲁棒估计的观测值的掩码。
- offset_浮点数
用于从原始分数定义决策函数的偏移量。我们有关系式:
decision_function = score_samples - offset_。该偏移量取决于污染参数,其定义方式使得我们在训练中能获得预期数量的异常值(决策函数小于0的样本)。在 0.20 版本中新增。
- raw_location_形状为 (n_features,) 的ndarray
修正和重新加权之前的原始鲁棒估计位置。
- raw_covariance_形状为 (n_features, n_features) 的ndarray
修正和重新加权之前的原始鲁棒估计协方差。
- raw_support_形状为 (n_samples,) 的ndarray
用于计算位置和形状的原始鲁棒估计的观测值掩码,在修正和重新加权之前。
- dist_形状为 (n_samples,) 的ndarray
训练集(在其上调用了
fit)观测值的马哈拉诺比斯距离。- n_features_in_整型
在fit期间看到的特征数量。
在 0.24 版本中新增。
- feature_names_in_形状为 (
n_features_in_,) 的ndarray 在fit期间看到的特征名称。仅当
X的特征名称全为字符串时定义。在 1.0 版本中新增。
另请参阅
EmpiricalCovariance最大似然协方差估计器。
GraphicalLasso使用L1惩罚估计器的稀疏逆协方差估计。
LedoitWolfLedoitWolf 估计器。
MinCovDet最小协方差行列式(鲁棒协方差估计器)。
OASOracle 近似收缩估计器。
ShrunkCovariance带收缩的协方差估计器。
注意
从协方差估计进行异常值检测在高维设置中可能会失效或表现不佳。特别是,始终要注意使用
n_samples > n_features ** 2。参考文献
[1]Rousseeuw, P.J., Van Driessen, K. “A fast algorithm for the minimum covariance determinant estimator” Technometrics 41(3), 212 (1999)
示例
>>> import numpy as np >>> from sklearn.covariance import EllipticEnvelope >>> true_cov = np.array([[.8, .3], ... [.3, .4]]) >>> X = np.random.RandomState(0).multivariate_normal(mean=[0, 0], ... cov=true_cov, ... size=500) >>> cov = EllipticEnvelope(random_state=0).fit(X) >>> # predict returns 1 for an inlier and -1 for an outlier >>> cov.predict([[0, 0], ... [3, 3]]) array([ 1, -1]) >>> cov.covariance_ array([[0.7411, 0.2535], [0.2535, 0.3053]]) >>> cov.location_ array([0.0813 , 0.0427])
- correct_covariance(data)[source]#
对原始最小协方差行列式估计应用校正。
使用Rousseeuw和Van Driessen在[RVD]中提出的经验校正因子进行校正。
- 参数:
- data形状为 (n_samples, n_features) 的类数组
数据矩阵,包含p个特征和n个样本。数据集必须是用于计算原始估计的数据集。
- 返回:
- covariance_corrected形状为 (n_features, n_features) 的ndarray
修正后的鲁棒协方差估计。
参考文献
[RVD]A Fast Algorithm for the Minimum Covariance Determinant Estimator, 1999, American Statistical Association and the American Society for Quality, TECHNOMETRICS
- decision_function(X)[source]#
计算给定观测值的决策函数。
- 参数:
- X形状为 (n_samples, n_features) 的类数组
数据矩阵。
- 返回:
- decision形状为 (n_samples,) 的ndarray
样本的决策函数。它等于偏移后的马哈拉诺比斯距离。作为异常值的阈值为0,这确保了与其他异常值检测算法的兼容性。
- error_norm(comp_cov, norm='frobenius', scaling=True, squared=True)[source]#
计算两个协方差估计器之间的均方误差。
- 参数:
- comp_cov形状为 (n_features, n_features) 的类数组
用于比较的协方差。
- norm{"frobenius", "spectral"},默认值="frobenius"
用于计算误差的范数类型。可用的误差类型: - ‘frobenius’(默认):sqrt(tr(A^t.A)) - ‘spectral’:sqrt(max(eigenvalues(A^t.A)),其中 A 是误差
(comp_cov - self.covariance_)。- scaling布尔值,默认值=True
如果为True(默认值),则将平方误差范数除以n_features。如果为False,则不重新缩放平方误差范数。
- squared布尔值,默认值=True
是否计算平方误差范数或误差范数。如果为True(默认值),则返回平方误差范数。如果为False,则返回误差范数。
- 返回:
- result浮点数
self和comp_cov协方差估计器之间的均方误差(以Frobenius范数表示)。
- fit(X, y=None)[source]#
拟合 EllipticEnvelope 模型。
- 参数:
- X形状为 (n_samples, n_features) 的类数组
训练数据。
- y忽略
未使用,按约定为API一致性而存在。
- 返回:
- self对象
返回实例本身。
- fit_predict(X, y=None, **kwargs)[source]#
对 X 执行拟合并返回 X 的标签。
异常值返回 -1,正常值返回 1。
- 参数:
- X形状为 (n_samples, n_features) 的{类数组, 稀疏矩阵}
输入样本。
- y忽略
未使用,按约定为API一致性而存在。
- **kwargs字典
传递给
fit的参数。在 1.4 版本中新增。
- 返回:
- y形状为 (n_samples,) 的ndarray
正常值为 1,异常值为 -1。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查阅用户指南,了解路由机制的工作原理。
- 返回:
- routingMetadataRequest
一个封装了路由信息的
MetadataRequest对象。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deep布尔值,默认值=True
如果为 True,将返回此估计器及其包含的作为估计器的子对象的参数。
- 返回:
- params字典
参数名称及其对应的值。
- mahalanobis(X)[source]#
计算给定观测值的平方马哈拉诺比斯距离。
- 参数:
- X形状为 (n_samples, n_features) 的类数组
我们计算其马哈拉诺比斯距离的观测值。观测值被假定来自与拟合数据相同的分布。
- 返回:
- dist形状为 (n_samples,) 的ndarray
观测值的平方马哈拉诺比斯距离。
- predict(X)[source]#
根据已拟合模型预测 X 的标签(1表示正常值,-1表示异常值)。
- 参数:
- X形状为 (n_samples, n_features) 的类数组
数据矩阵。
- 返回:
- is_inlier形状为 (n_samples,) 的ndarray
异常返回 -1,正常值返回 +1。
- reweight_covariance(data)[source]#
重新加权原始最小协方差行列式估计。
使用 Rousseeuw 的方法(相当于在计算位置和协方差估计之前从数据集中删除异常观测值)重新加权观测值,该方法在[RVDriessen]中描述。
- 参数:
- data形状为 (n_samples, n_features) 的类数组
数据矩阵,包含p个特征和n个样本。数据集必须是用于计算原始估计的数据集。
- 返回:
- location_reweighted形状为 (n_features,) 的ndarray
重新加权的鲁棒位置估计。
- covariance_reweighted形状为 (n_features, n_features) 的ndarray
重新加权的鲁棒协方差估计。
- support_reweighted形状为 (n_samples,) 且 dtype=bool 的ndarray
用于计算重新加权的鲁棒位置和协方差估计的观测值掩码。
参考文献
[RVDriessen]A Fast Algorithm for the Minimum Covariance Determinant Estimator, 1999, American Statistical Association and the American Society for Quality, TECHNOMETRICS
- score(X, y, sample_weight=None)[source]#
返回给定测试数据和标签上的平均准确度。
在多标签分类中,这是子集准确度,这是一个严格的指标,因为它要求每个样本的每个标签集都被正确预测。
- 参数:
- X形状为 (n_samples, n_features) 的类数组
测试样本。
- y形状为 (n_samples,) 或 (n_samples, n_outputs) 的类数组
X 的真实标签。
- sample_weight形状为 (n_samples,) 的类数组,默认值=None
样本权重。
- 返回:
- score浮点数
self.predict(X) 相对于 y 的平均准确度。