AffinityPropagation#
- class sklearn.cluster.AffinityPropagation(*, damping=0.5, max_iter=200, convergence_iter=15, copy=True, preference=None, affinity='euclidean', verbose=False, random_state=None)[source]#
执行亲和传播(Affinity Propagation)数据聚类。
欲了解更多信息,请参阅用户指南。
- 参数:
- damping浮点数, 默认值=0.5
阻尼因子,范围为
[0.5, 1.0),表示当前值相对于传入值(权重为 1 - 阻尼)的保持程度。这样做是为了避免在更新这些值(消息)时出现数值振荡。- max_iter整型, 默认值=200
最大迭代次数。
- convergence_iter整型, 默认值=15
估计聚类数量无变化的迭代次数,达到此次数即停止收敛。
- copy布尔型, 默认值=True
复制输入数据。
- preference类数组,形状为 (n_samples,) 或浮点数, 默认值=None
每个点的偏好值——偏好值越大的点越有可能被选为代表。代表(即聚类)的数量受输入偏好值的影响。如果未将偏好值作为参数传入,它们将被设置为输入相似度的中位数。
- affinity{‘euclidean’, ‘precomputed’}, 默认值='euclidean'
要使用的亲和度类型。目前支持‘precomputed’和
euclidean。‘euclidean’使用点之间的负平方欧氏距离。- verbose布尔型, 默认值=False
是否启用详细输出。
- random_state整型, RandomState 实例或 None, 默认值=None
伪随机数生成器,用于控制起始状态。使用整数可在函数调用之间获得可重现的结果。请参阅术语表。
0.23 版本新增: 此参数以前硬编码为 0。
- 属性:
- cluster_centers_indices_ndarray,形状为 (n_clusters,)
聚类中心的索引。
- cluster_centers_ndarray,形状为 (n_clusters, n_features)
聚类中心(如果 affinity !=
precomputed)。- labels_ndarray,形状为 (n_samples,)
每个点的标签。
- affinity_matrix_ndarray,形状为 (n_samples, n_samples)
存储在
fit中使用的亲和度矩阵。- n_iter_整型
收敛所需的迭代次数。
- n_features_in_整型
在fit期间看到的特征数量。
0.24 版本新增。
- feature_names_in_ndarray,形状为 (
n_features_in_,) 在fit期间看到的特征名称。仅当
X的特征名称全部为字符串时才定义。1.0 版本新增。
另请参阅
AgglomerativeClustering递归地合并使给定链接距离增加最小的聚类对。
FeatureAgglomeration与 AgglomerativeClustering 类似,但递归地合并特征而不是样本。
KMeansK-Means 聚类。
MiniBatchKMeansMini-Batch K-Means 聚类。
MeanShift使用平坦核的均值漂移聚类。
SpectralClustering将聚类应用于归一化拉普拉斯算子的投影。
备注
亲和传播的算法复杂度与点数的平方成正比。
当算法不收敛时,如果存在任何代表/聚类,它仍将返回
cluster_center_indices和标签数组,但它们可能是退化的,应谨慎使用。当
fit不收敛时,cluster_centers_仍然会填充,但可能退化。在这种情况下,请谨慎操作。如果fit不收敛且未能生成任何cluster_centers_,则predict会将每个样本标记为-1。当所有训练样本具有相同的相似性和相同的偏好时,聚类中心和标签的分配取决于偏好。如果偏好小于相似性,
fit将产生一个单一的聚类中心,并为每个样本分配标签0。否则,每个训练样本都将成为其自身的聚类中心,并被分配一个唯一的标签。参考文献
Brendan J. Frey 和 Delbert Dueck,“通过数据点间消息传递进行聚类”,《科学》2007 年 2 月
示例
>>> from sklearn.cluster import AffinityPropagation >>> import numpy as np >>> X = np.array([[1, 2], [1, 4], [1, 0], ... [4, 2], [4, 4], [4, 0]]) >>> clustering = AffinityPropagation(random_state=5).fit(X) >>> clustering AffinityPropagation(random_state=5) >>> clustering.labels_ array([0, 0, 0, 1, 1, 1]) >>> clustering.predict([[0, 0], [4, 4]]) array([0, 1]) >>> clustering.cluster_centers_ array([[1, 2], [4, 2]])
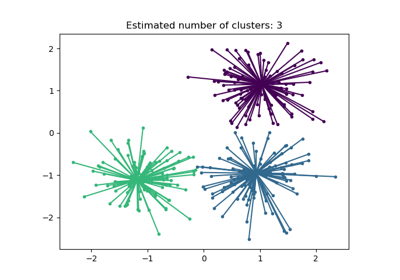
有关示例用法,请参阅亲和传播聚类算法演示。
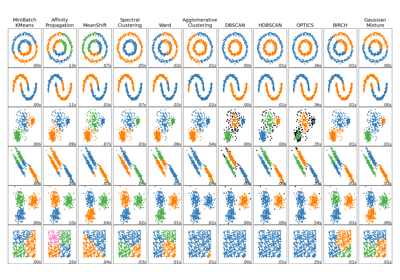
有关亲和传播与其他聚类算法的比较,请参阅玩具数据集上不同聚类算法的比较
- fit(X, y=None)[source]#
从特征或亲和度矩阵拟合聚类。
- 参数:
- X{类数组, 稀疏矩阵},形状为 (n_samples, n_features),或类数组,形状为 (n_samples, n_samples)
要聚类的训练实例,如果
affinity='precomputed',则为实例间的相似度/亲和度。如果提供了稀疏特征矩阵,它将被转换为稀疏的csr_matrix。- y忽略
未使用,根据约定在此处保留以保持 API 一致性。
- 返回:
- self
返回实例本身。
- fit_predict(X, y=None)[source]#
从特征/亲和度矩阵拟合聚类;返回聚类标签。
- 参数:
- X{类数组, 稀疏矩阵},形状为 (n_samples, n_features),或类数组,形状为 (n_samples, n_samples)
要聚类的训练实例,如果
affinity='precomputed',则为实例间的相似度/亲和度。如果提供了稀疏特征矩阵,它将被转换为稀疏的csr_matrix。- y忽略
未使用,根据约定在此处保留以保持 API 一致性。
- 返回:
- labelsndarray,形状为 (n_samples,)
聚类标签。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查看用户指南以了解路由机制的工作原理。
- 返回:
- routingMetadataRequest
一个封装了路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deep布尔型, 默认值=True
如果为 True,将返回此估计器及其包含的作为估计器的子对象的参数。
- 返回:
- params字典
参数名称及其对应的值。