FeatureHasher#
- class sklearn.feature_extraction.FeatureHasher(n_features=1048576, *, input_type='dict', dtype=<class 'numpy.float64'>, alternate_sign=True)[source]#
实现了特征哈希,又称哈希技巧。
此类将符号特征名称(字符串)序列转换为scipy稀疏矩阵,使用哈希函数计算与名称对应的矩阵列。所用的哈希函数是Murmurhash3的带符号32位版本。
字节字符串类型的特征名称按原样使用。Unicode字符串首先转换为UTF-8,但不进行Unicode规范化。特征值必须是(有限)数字。
此类是DictVectorizer和CountVectorizer的低内存替代品,适用于大规模(在线)学习以及内存紧张的情况,例如在嵌入式设备上运行预测代码时。
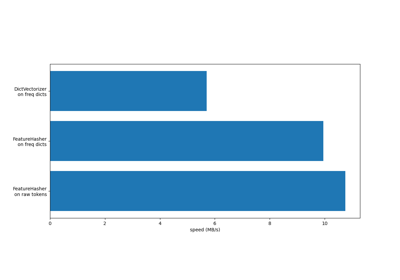
有关不同特征提取器的效率比较,请参见FeatureHasher与DictVectorizer比较。
更多信息请参见用户指南。
0.13 版本新增。
- 参数:
- n_features整型,默认值=2**20
输出矩阵中的特征(列)数量。少量特征可能导致哈希冲突,但大量特征将导致线性学习器中的系数维度更大。
- input_type字符串,默认值='dict'
从{'dict', 'pair', 'string'}中选择一个字符串。“dict”(默认值)表示接受字典形式的(feature_name, value);“pair”表示接受(feature_name, value)对;或“string”表示接受单个字符串。feature_name应为字符串,而value应为数字。在“string”的情况下,隐含值为1。feature_name被哈希以查找特征的相应列。输出中值的符号可能会翻转(但请参见下面的non_negative)。
- dtypenumpy数据类型,默认值=np.float64
特征值的类型。作为dtype参数传递给scipy稀疏矩阵构造函数。请勿将其设置为bool、np.boolean或任何无符号整数类型。
- alternate_sign布尔型,默认值=True
当为True时,会给特征添加一个交替符号,以便即使对于小的n_features,也能近似地保留哈希空间中的内积。此方法类似于稀疏随机投影。
0.19 版本有所更改:
alternate_sign替换了现已弃用的non_negative参数。
另请参见
DictVectorizer使用哈希表对字符串值特征进行向量化。
sklearn.preprocessing.OneHotEncoder处理标称/分类特征。
备注
此估计器是无状态的,不需要拟合。然而,我们建议调用
fit_transform而不是transform,因为参数验证只在fit中执行。示例
>>> from sklearn.feature_extraction import FeatureHasher >>> h = FeatureHasher(n_features=10) >>> D = [{'dog': 1, 'cat':2, 'elephant':4},{'dog': 2, 'run': 5}] >>> f = h.transform(D) >>> f.toarray() array([[ 0., 0., -4., -1., 0., 0., 0., 0., 0., 2.], [ 0., 0., 0., -2., -5., 0., 0., 0., 0., 0.]])
当
input_type="string"时,输入必须是字符串可迭代对象的嵌套可迭代对象。>>> h = FeatureHasher(n_features=8, input_type="string") >>> raw_X = [["dog", "cat", "snake"], ["snake", "dog"], ["cat", "bird"]] >>> f = h.transform(raw_X) >>> f.toarray() array([[ 0., 0., 0., -1., 0., -1., 0., 1.], [ 0., 0., 0., -1., 0., -1., 0., 0.], [ 0., -1., 0., 0., 0., 0., 0., 1.]])
- fit(X=None, y=None)[source]#
仅验证估计器的参数。
此方法允许:(i) 验证估计器的参数,以及 (ii) 与 scikit-learn 转换器 API 保持一致。
- 参数:
- X忽略
未使用,按约定在此处表示 API 一致性。
- y忽略
未使用,按约定在此处表示 API 一致性。
- 返回:
- self对象
FeatureHasher 类实例。
- fit_transform(X, y=None, **fit_params)[source]#
拟合数据,然后进行转换。
使用可选参数
fit_params将转换器拟合到X和y,并返回X的转换版本。- 参数:
- X形状为 (n_samples, n_features) 的类数组
输入样本。
- y形状为 (n_samples,) 或 (n_samples, n_outputs) 的类数组,默认值=None
目标值(无监督转换时为None)。
- **fit_params字典
额外的拟合参数。
- 返回:
- X_new形状为 (n_samples, n_features_new) 的ndarray数组
转换后的数组。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查看用户指南了解路由机制的工作原理。
- 返回:
- routingMetadataRequest
一个封装路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deep布尔型,默认值=True
如果为 True,将返回此估计器及其包含的作为估计器的子对象的参数。
- 返回:
- params字典
参数名称及其对应的值。
- set_output(*, transform=None)[source]#
设置输出容器。
有关如何使用此 API 的示例,请参见set_output API 简介。
- 参数:
- transform{"default", "pandas", "polars"},默认值=None
配置
transform和fit_transform的输出。"default": 转换器的默认输出格式"pandas": DataFrame 输出"polars": Polars 输出None: 转换配置未更改
1.4 版本新增:
"polars"选项已添加。
- 返回:
- self估计器实例
估计器实例。