注意
跳转至末尾 下载完整示例代码,或通过 JupyterLite 或 Binder 在浏览器中运行此示例
介绍 `set_output` API#
此示例将演示 `set_output` API,以配置转换器输出 pandas DataFrames。`set_output` 可以通过调用 `set_output` 方法按估计器配置,或通过设置 `set_config(transform_output="pandas")` 进行全局配置。详情请参阅 SLEP018。
首先,我们加载鸢尾花数据集作为 DataFrame,以演示 `set_output` API。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
X, y = load_iris(as_frame=True, return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)
X_train.head()
要配置估计器(例如 preprocessing.StandardScaler)返回 DataFrames,请调用 `set_output`。此功能需要安装 pandas。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler().set_output(transform="pandas")
scaler.fit(X_train)
X_test_scaled = scaler.transform(X_test)
X_test_scaled.head()
可以在 `fit` 之后调用 `set_output`,以在事后配置 `transform`。
scaler2 = StandardScaler()
scaler2.fit(X_train)
X_test_np = scaler2.transform(X_test)
print(f"Default output type: {type(X_test_np).__name__}")
scaler2.set_output(transform="pandas")
X_test_df = scaler2.transform(X_test)
print(f"Configured pandas output type: {type(X_test_df).__name__}")
Default output type: ndarray
Configured pandas output type: DataFrame
在 pipeline.Pipeline 中,`set_output` 配置所有步骤输出 DataFrames。
from sklearn.feature_selection import SelectPercentile
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
clf = make_pipeline(
StandardScaler(), SelectPercentile(percentile=75), LogisticRegression()
)
clf.set_output(transform="pandas")
clf.fit(X_train, y_train)
流水线中的每个转换器都配置为返回 DataFrames。这意味着最终的逻辑回归步骤包含输入的特征名称。
clf[-1].feature_names_in_
array(['sepal length (cm)', 'petal length (cm)', 'petal width (cm)'],
dtype=object)
注意
如果使用 `set_params` 方法,转换器将被替换为一个新转换器,其输出格式为默认值。
clf.set_params(standardscaler=StandardScaler())
clf.fit(X_train, y_train)
clf[-1].feature_names_in_
array(['x0', 'x2', 'x3'], dtype=object)
为保持预期行为,请预先在新转换器上使用 `set_output`
scaler = StandardScaler().set_output(transform="pandas")
clf.set_params(standardscaler=scaler)
clf.fit(X_train, y_train)
clf[-1].feature_names_in_
array(['sepal length (cm)', 'petal length (cm)', 'petal width (cm)'],
dtype=object)
接下来,我们加载泰坦尼克号数据集,以演示 `set_output` 与 compose.ColumnTransformer 和异构数据的结合使用。
from sklearn.datasets import fetch_openml
X, y = fetch_openml("titanic", version=1, as_frame=True, return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y)
`set_output` API 可以通过使用 set_config 并将 `transform_output` 设置为 `"pandas"` 来全局配置。
from sklearn import set_config
from sklearn.compose import ColumnTransformer
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder, StandardScaler
set_config(transform_output="pandas")
num_pipe = make_pipeline(SimpleImputer(), StandardScaler())
num_cols = ["age", "fare"]
ct = ColumnTransformer(
(
("numerical", num_pipe, num_cols),
(
"categorical",
OneHotEncoder(
sparse_output=False, drop="if_binary", handle_unknown="ignore"
),
["embarked", "sex", "pclass"],
),
),
verbose_feature_names_out=False,
)
clf = make_pipeline(ct, SelectPercentile(percentile=50), LogisticRegression())
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
0.801829268292683
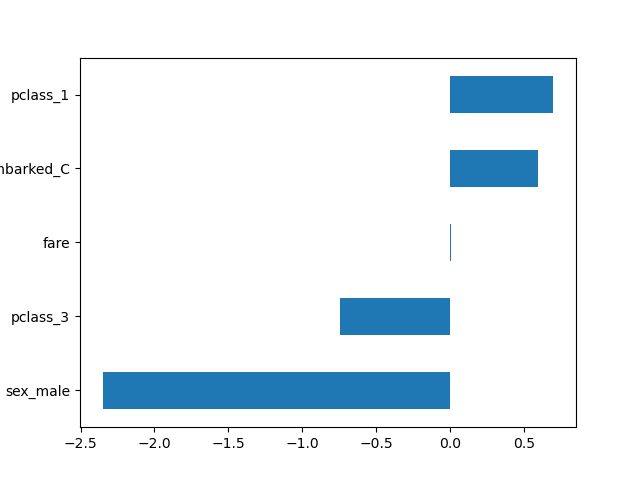
通过全局配置,所有转换器都输出 DataFrames。这使我们能够轻松地绘制带有相应特征名称的逻辑回归系数。
import pandas as pd
log_reg = clf[-1]
coef = pd.Series(log_reg.coef_.ravel(), index=log_reg.feature_names_in_)
_ = coef.sort_values().plot.barh()
为了演示下面的 config_context 功能,我们首先将 `transform_output` 重置为其默认值。
set_config(transform_output="default")
当使用 config_context 配置输出类型时,`transform` 或 `fit_transform` 被调用时的配置才是有效的。仅在构造或拟合转换器时进行设置没有效果。
from sklearn import config_context
scaler = StandardScaler()
scaler.fit(X_train[num_cols])
with config_context(transform_output="pandas"):
# the output of transform will be a Pandas DataFrame
X_test_scaled = scaler.transform(X_test[num_cols])
X_test_scaled.head()
在上下文管理器之外,输出将是一个 NumPy 数组
X_test_scaled = scaler.transform(X_test[num_cols])
X_test_scaled[:5]
array([[ 0.62830616, -0.06320955],
[-0.05798371, -0.51570367],
[ 1.31459603, 0.56662405],
[-0.6756446 , -0.51227857],
[-0.74427358, -0.49694966]])
脚本总运行时间: (0 minutes 0.142 seconds)
相关示例