注意
前往末尾以下载完整示例代码,或通过 JupyterLite 或 Binder 在浏览器中运行此示例
scikit-learn 0.22 的发布亮点#
我们很高兴地宣布 scikit-learn 0.22 发布,它带来了许多错误修复和新功能!下面我们详细介绍此版本的一些主要功能。有关所有更改的详尽列表,请参阅发行说明。
要安装最新版本(使用 pip)
pip install --upgrade scikit-learn
或使用 conda
conda install -c conda-forge scikit-learn
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
新绘图 API#
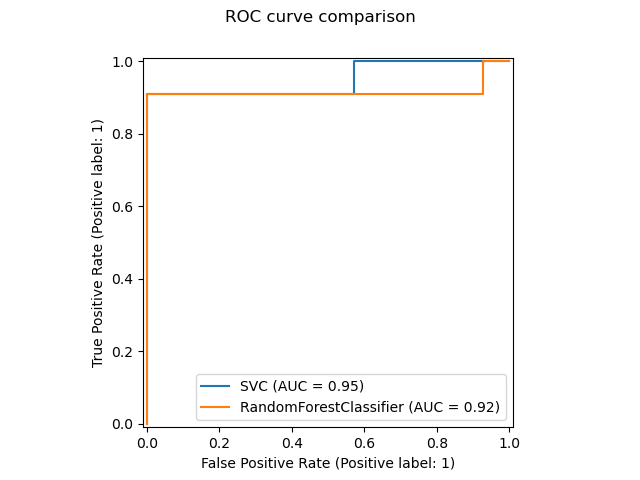
一个新的绘图 API 可用于创建可视化。这个新的 API 允许快速调整绘图的视觉效果,而无需任何重新计算。也可以在同一张图中添加不同的图。以下示例演示了 plot_roc_curve,但也支持其他绘图工具,如 plot_partial_dependence、plot_precision_recall_curve 和 plot_confusion_matrix。在用户指南中阅读有关此新 API 的更多信息。
import matplotlib
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
# from sklearn.metrics import plot_roc_curve
from sklearn.metrics import RocCurveDisplay
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.utils.fixes import parse_version
X, y = make_classification(random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
svc = SVC(random_state=42)
svc.fit(X_train, y_train)
rfc = RandomForestClassifier(random_state=42)
rfc.fit(X_train, y_train)
# plot_roc_curve has been removed in version 1.2. From 1.2, use RocCurveDisplay instead.
# svc_disp = plot_roc_curve(svc, X_test, y_test)
# rfc_disp = plot_roc_curve(rfc, X_test, y_test, ax=svc_disp.ax_)
svc_disp = RocCurveDisplay.from_estimator(svc, X_test, y_test)
rfc_disp = RocCurveDisplay.from_estimator(rfc, X_test, y_test, ax=svc_disp.ax_)
rfc_disp.figure_.suptitle("ROC curve comparison")
plt.show()
堆叠分类器和回归器#
StackingClassifier 和 StackingRegressor 允许您拥有一系列估计器,并带有一个最终的分类器或回归器。堆叠泛化包括堆叠单个估计器的输出,并使用分类器计算最终预测。堆叠允许通过将每个独立估计器的输出作为最终估计器的输入来利用它们的优势。基本估计器在完整的 X 上进行拟合,而最终估计器则使用 cross_val_predict 通过基本估计器的交叉验证预测进行训练。
在用户指南中阅读更多信息。
from sklearn.datasets import load_iris
from sklearn.ensemble import StackingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
X, y = load_iris(return_X_y=True)
estimators = [
("rf", RandomForestClassifier(n_estimators=10, random_state=42)),
("svr", make_pipeline(StandardScaler(), LinearSVC(dual="auto", random_state=42))),
]
clf = StackingClassifier(estimators=estimators, final_estimator=LogisticRegression())
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
clf.fit(X_train, y_train).score(X_test, y_test)
0.9473684210526315
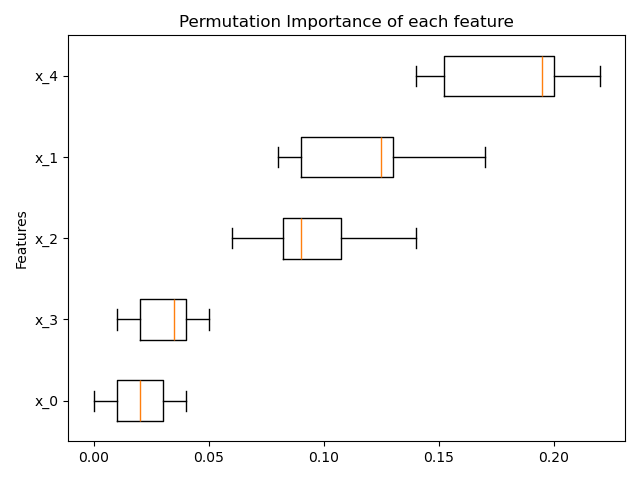
基于置换的特征重要性#
可以使用 inspection.permutation_importance 来估计任何已拟合估计器的每个特征的重要性。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
from sklearn.inspection import permutation_importance
X, y = make_classification(random_state=0, n_features=5, n_informative=3)
feature_names = np.array([f"x_{i}" for i in range(X.shape[1])])
rf = RandomForestClassifier(random_state=0).fit(X, y)
result = permutation_importance(rf, X, y, n_repeats=10, random_state=0, n_jobs=2)
fig, ax = plt.subplots()
sorted_idx = result.importances_mean.argsort()
# `labels` argument in boxplot is deprecated in matplotlib 3.9 and has been
# renamed to `tick_labels`. The following code handles this, but as a
# scikit-learn user you probably can write simpler code by using `labels=...`
# (matplotlib < 3.9) or `tick_labels=...` (matplotlib >= 3.9).
tick_labels_parameter_name = (
"tick_labels"
if parse_version(matplotlib.__version__) >= parse_version("3.9")
else "labels"
)
tick_labels_dict = {tick_labels_parameter_name: feature_names[sorted_idx]}
ax.boxplot(result.importances[sorted_idx].T, vert=False, **tick_labels_dict)
ax.set_title("Permutation Importance of each feature")
ax.set_ylabel("Features")
fig.tight_layout()
plt.show()
梯度提升对缺失值的原生支持#
ensemble.HistGradientBoostingClassifier 和 ensemble.HistGradientBoostingRegressor 现在原生支持缺失值 (NaNs)。这意味着在训练或预测时无需进行数据填充。
from sklearn.ensemble import HistGradientBoostingClassifier
X = np.array([0, 1, 2, np.nan]).reshape(-1, 1)
y = [0, 0, 1, 1]
gbdt = HistGradientBoostingClassifier(min_samples_leaf=1).fit(X, y)
print(gbdt.predict(X))
[0 0 1 1]
预计算的稀疏最近邻图#
大多数基于最近邻图的估计器现在接受预计算的稀疏图作为输入,以便在多次估计器拟合中重用相同的图。要在 Pipeline 中使用此功能,可以使用 memory 参数,以及两个新转换器中的一个:neighbors.KNeighborsTransformer 和 neighbors.RadiusNeighborsTransformer。预计算也可以由自定义估计器执行,以使用替代实现,例如近似最近邻方法。有关更多详细信息,请参阅用户指南。
from tempfile import TemporaryDirectory
from sklearn.manifold import Isomap
from sklearn.neighbors import KNeighborsTransformer
from sklearn.pipeline import make_pipeline
X, y = make_classification(random_state=0)
with TemporaryDirectory(prefix="sklearn_cache_") as tmpdir:
estimator = make_pipeline(
KNeighborsTransformer(n_neighbors=10, mode="distance"),
Isomap(n_neighbors=10, metric="precomputed"),
memory=tmpdir,
)
estimator.fit(X)
# We can decrease the number of neighbors and the graph will not be
# recomputed.
estimator.set_params(isomap__n_neighbors=5)
estimator.fit(X)
基于 KNN 的填充#
我们现在支持使用 k-最近邻来填充缺失值。
每个样本的缺失值都使用训练集中找到的 n_neighbors 个最近邻的平均值进行填充。如果两个样本都没有缺失的特征值相近,则认为它们是“近”的。默认情况下,使用支持缺失值的欧几里得距离度量 nan_euclidean_distances 来查找最近邻。
在用户指南中阅读更多信息。
from sklearn.impute import KNNImputer
X = [[1, 2, np.nan], [3, 4, 3], [np.nan, 6, 5], [8, 8, 7]]
imputer = KNNImputer(n_neighbors=2)
print(imputer.fit_transform(X))
[[1. 2. 4. ]
[3. 4. 3. ]
[5.5 6. 5. ]
[8. 8. 7. ]]
树剪枝#
现在可以在树构建完成后对大多数基于树的估计器进行剪枝。剪枝基于最小成本复杂度。有关详细信息,请参阅用户指南。
X, y = make_classification(random_state=0)
rf = RandomForestClassifier(random_state=0, ccp_alpha=0).fit(X, y)
print(
"Average number of nodes without pruning {:.1f}".format(
np.mean([e.tree_.node_count for e in rf.estimators_])
)
)
rf = RandomForestClassifier(random_state=0, ccp_alpha=0.05).fit(X, y)
print(
"Average number of nodes with pruning {:.1f}".format(
np.mean([e.tree_.node_count for e in rf.estimators_])
)
)
Average number of nodes without pruning 22.3
Average number of nodes with pruning 6.4
从 OpenML 检索数据帧#
datasets.fetch_openml 现在可以返回 pandas 数据帧,从而正确处理异构数据集。
from sklearn.datasets import fetch_openml
titanic = fetch_openml("titanic", version=1, as_frame=True, parser="pandas")
print(titanic.data.head()[["pclass", "embarked"]])
pclass embarked
0 1 S
1 1 S
2 1 S
3 1 S
4 1 S
检查估计器的 scikit-learn 兼容性#
开发者可以使用 check_estimator 检查其 scikit-learn 兼容估计器的兼容性。例如,check_estimator(LinearSVC()) 通过检查。
我们现在提供一个 pytest 特定装饰器,它允许 pytest 独立运行所有检查并报告失败的检查。
- ..注意:
此条目在 0.24 版本中略有更新,不再支持传递类:请传递实例。
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.utils.estimator_checks import parametrize_with_checks
@parametrize_with_checks([LogisticRegression(), DecisionTreeRegressor()])
def test_sklearn_compatible_estimator(estimator, check):
check(estimator)
ROC AUC 现在支持多类分类#
根据模型,roc_auc_score 函数也可用于多类分类。目前支持两种平均策略:一对一算法计算成对 ROC AUC 分数的平均值,而一对多算法计算每个类相对于所有其他类的 ROC AUC 分数的平均值。在这两种情况下,多类 ROC AUC 分数均根据样本属于特定类别的模型概率估计计算得出。OvO 和 OvR 算法支持均匀加权(average='macro')和按流行度加权(average='weighted')。
在用户指南中阅读更多信息。
from sklearn.datasets import make_classification
from sklearn.metrics import roc_auc_score
from sklearn.svm import SVC
X, y = make_classification(n_classes=4, n_informative=16)
clf = SVC(decision_function_shape="ovo", probability=True).fit(X, y)
print(roc_auc_score(y, clf.predict_proba(X), multi_class="ovo"))
0.989824369296833
脚本总运行时间: (0 分钟 1.450 秒)
相关示例