注意
跳转至底部以下载完整示例代码,或通过 JupyterLite 或 Binder 在浏览器中运行此示例
scikit-learn 1.2 发布亮点#
我们很高兴宣布 scikit-learn 1.2 发布了!增加了许多错误修复和改进,以及一些新的关键功能。下面我们详细介绍本次发布的一些主要功能。有关所有更改的详尽列表,请参阅发布说明。
安装最新版本(使用 pip)
pip install --upgrade scikit-learn
或使用 conda
conda install -c conda-forge scikit-learn
使用 set_output API 支持 Pandas 输出#
scikit-learn 的转换器现在通过 set_output API 支持 Pandas 输出。要了解更多关于 set_output API 的信息,请参见示例:引入 set_output API 和这个 视频:scikit-learn 转换器的 Pandas DataFrame 输出(一些示例)。
import numpy as np
from sklearn.compose import ColumnTransformer
from sklearn.datasets import load_iris
from sklearn.preprocessing import KBinsDiscretizer, StandardScaler
X, y = load_iris(as_frame=True, return_X_y=True)
sepal_cols = ["sepal length (cm)", "sepal width (cm)"]
petal_cols = ["petal length (cm)", "petal width (cm)"]
preprocessor = ColumnTransformer(
[
("scaler", StandardScaler(), sepal_cols),
(
"kbin",
KBinsDiscretizer(encode="ordinal", quantile_method="averaged_inverted_cdf"),
petal_cols,
),
],
verbose_feature_names_out=False,
).set_output(transform="pandas")
X_out = preprocessor.fit_transform(X)
X_out.sample(n=5, random_state=0)
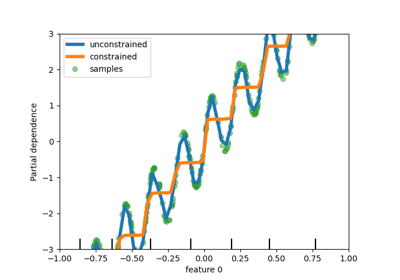
基于直方图的梯度提升树中的交互约束#
HistGradientBoostingRegressor 和 HistGradientBoostingClassifier 现在支持通过 interaction_cst 参数设置交互约束。详细信息请参见用户指南。在下面的示例中,特征不允许相互作用。
from sklearn.datasets import load_diabetes
from sklearn.ensemble import HistGradientBoostingRegressor
X, y = load_diabetes(return_X_y=True, as_frame=True)
hist_no_interact = HistGradientBoostingRegressor(
interaction_cst=[[i] for i in range(X.shape[1])], random_state=0
)
hist_no_interact.fit(X, y)
新增和增强的显示功能#
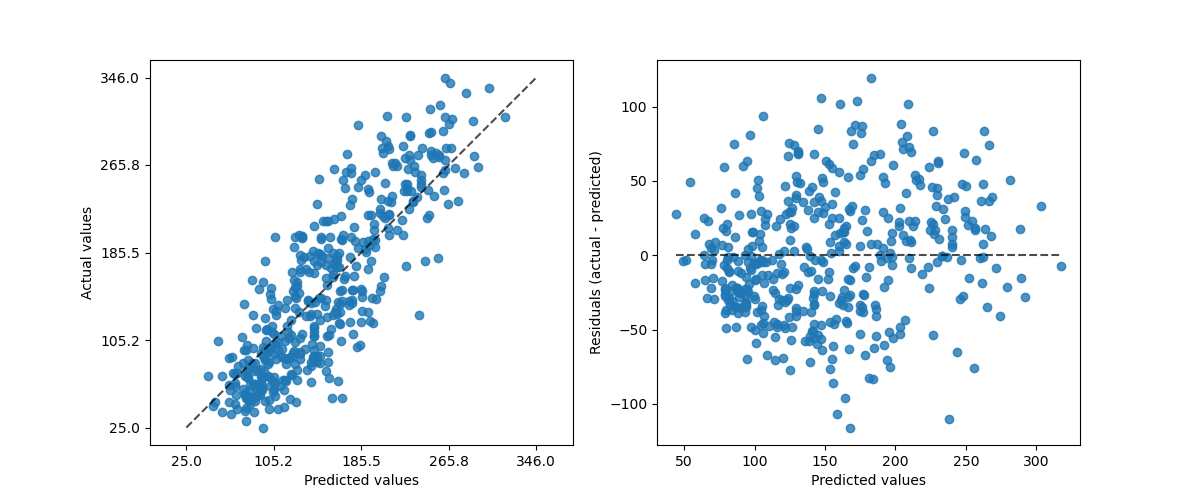
PredictionErrorDisplay 提供了一种定性分析回归模型的方法。
import matplotlib.pyplot as plt
from sklearn.metrics import PredictionErrorDisplay
fig, axs = plt.subplots(nrows=1, ncols=2, figsize=(12, 5))
_ = PredictionErrorDisplay.from_estimator(
hist_no_interact, X, y, kind="actual_vs_predicted", ax=axs[0]
)
_ = PredictionErrorDisplay.from_estimator(
hist_no_interact, X, y, kind="residual_vs_predicted", ax=axs[1]
)
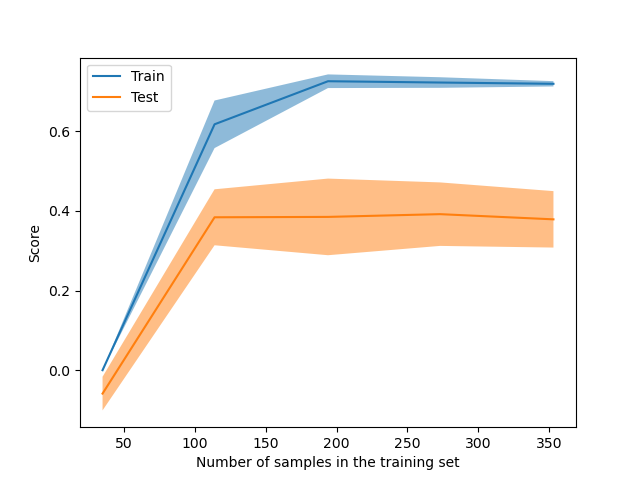
LearningCurveDisplay 现已可用,用于绘制 learning_curve 的结果。
from sklearn.model_selection import LearningCurveDisplay
_ = LearningCurveDisplay.from_estimator(
hist_no_interact, X, y, cv=5, n_jobs=2, train_sizes=np.linspace(0.1, 1, 5)
)
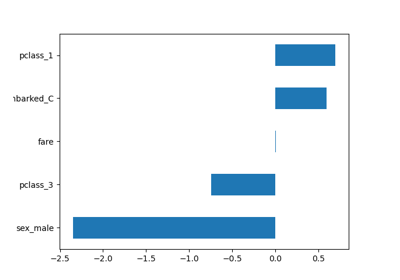
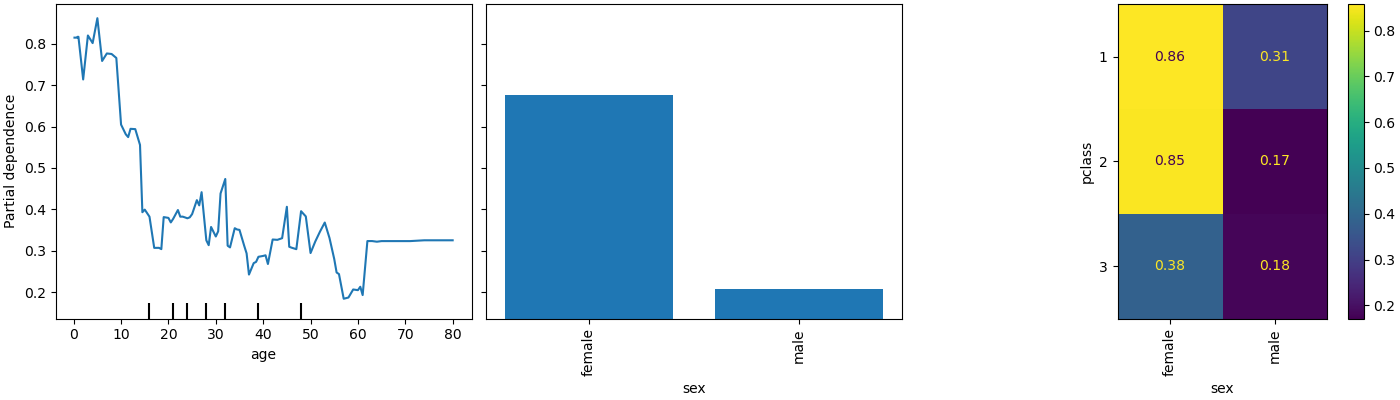
PartialDependenceDisplay 暴露了一个新参数 categorical_features,用于使用条形图和热力图显示类别特征的部分依赖关系。
from sklearn.datasets import fetch_openml
X, y = fetch_openml(
"titanic", version=1, as_frame=True, return_X_y=True, parser="pandas"
)
X = X.select_dtypes(["number", "category"]).drop(columns=["body"])
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import OrdinalEncoder
categorical_features = ["pclass", "sex", "embarked"]
model = make_pipeline(
ColumnTransformer(
transformers=[("cat", OrdinalEncoder(), categorical_features)],
remainder="passthrough",
),
HistGradientBoostingRegressor(random_state=0),
).fit(X, y)
from sklearn.inspection import PartialDependenceDisplay
fig, ax = plt.subplots(figsize=(14, 4), constrained_layout=True)
_ = PartialDependenceDisplay.from_estimator(
model,
X,
features=["age", "sex", ("pclass", "sex")],
categorical_features=categorical_features,
ax=ax,
)
fetch_openml 中更快的解析器#
fetch_openml 现在支持一种新的 "pandas" 解析器,该解析器在内存和 CPU 效率方面更优。在 v1.4 中,默认值将更改为 parser="auto",这将自动对密集数据使用 "pandas" 解析器,对稀疏数据使用 "liac-arff"。
X, y = fetch_openml(
"titanic", version=1, as_frame=True, return_X_y=True, parser="pandas"
)
X.head()
LinearDiscriminantAnalysis 中对 Array API 的实验性支持#
LinearDiscriminantAnalysis 中增加了对 Array API 规范的实验性支持。该估计器现在可以在任何符合 Array API 规范的库上运行,例如 CuPy(一个 GPU 加速的数组库)。详细信息请参见用户指南。
许多估计器的效率得到提升#
在 1.1 版本中,许多依赖于成对距离计算的估计器(主要是与聚类、流形学习和邻居搜索算法相关的估计器)对于 float64 密集输入的情况,效率得到了极大提升。效率的提升尤其体现在内存占用减少和在多核机器上更好的可伸缩性。在 1.2 版本中,这些估计器在 float32 和 float64 数据集上对密集和稀疏输入的所有组合(欧几里得距离和平方欧几里得距离度量的稀疏-密集和密集-稀疏组合除外)的效率得到了进一步提升。受影响估计器的详细列表可在更新日志中找到。
脚本总运行时间: (0 分 5.183 秒)
相关示例