注意
跳到末尾以下载完整示例代码,或通过 JupyterLite 或 Binder 在浏览器中运行此示例。
保险理赔的 Tweedie 回归#
本示例演示了在法国机动车第三方责任险理赔数据集上使用泊松、Gamma 和 Tweedie 回归,其灵感来源于一篇 R 教程[1]。
在此数据集中,每个样本对应一份保险保单,即保险公司与个人(投保人)之间的合同。可用特征包括驾驶员年龄、车龄、车辆功率等。
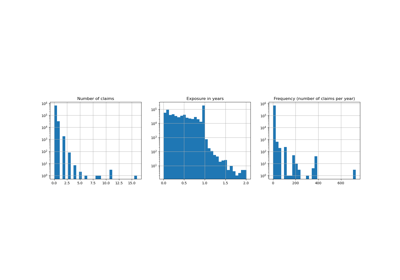
几个定义:理赔是投保人向保险公司提出的,要求赔偿保险承保损失的请求。理赔金额是保险公司必须支付的金额。风险暴露是特定保单的保险覆盖期限,以年为单位。
我们的目标是预测每单位风险暴露的总理赔金额的期望值(即均值),该值也称为纯保费。
实现此目标有多种可能性,其中两种是:
使用泊松分布建模理赔数量,并使用 Gamma 分布建模每次理赔的平均金额(也称为赔付金额),然后将两者的预测相乘以获得总理赔金额。
直接建模每风险暴露的总理赔金额,通常使用 Tweedie 幂参数 \(p \in (1, 2)\) 的 Tweedie 分布。
在本示例中,我们将演示这两种方法。首先,我们定义一些辅助函数来加载数据和可视化结果。
from functools import partial
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.datasets import fetch_openml
from sklearn.metrics import (
mean_absolute_error,
mean_squared_error,
mean_tweedie_deviance,
)
def load_mtpl2(n_samples=None):
"""Fetch the French Motor Third-Party Liability Claims dataset.
Parameters
----------
n_samples: int, default=None
number of samples to select (for faster run time). Full dataset has
678013 samples.
"""
# freMTPL2freq dataset from https://www.openml.org/d/41214
df_freq = fetch_openml(data_id=41214, as_frame=True).data
df_freq["IDpol"] = df_freq["IDpol"].astype(int)
df_freq.set_index("IDpol", inplace=True)
# freMTPL2sev dataset from https://www.openml.org/d/41215
df_sev = fetch_openml(data_id=41215, as_frame=True).data
# sum ClaimAmount over identical IDs
df_sev = df_sev.groupby("IDpol").sum()
df = df_freq.join(df_sev, how="left")
df["ClaimAmount"] = df["ClaimAmount"].fillna(0)
# unquote string fields
for column_name in df.columns[[t is object for t in df.dtypes.values]]:
df[column_name] = df[column_name].str.strip("'")
return df.iloc[:n_samples]
def plot_obs_pred(
df,
feature,
weight,
observed,
predicted,
y_label=None,
title=None,
ax=None,
fill_legend=False,
):
"""Plot observed and predicted - aggregated per feature level.
Parameters
----------
df : DataFrame
input data
feature: str
a column name of df for the feature to be plotted
weight : str
column name of df with the values of weights or exposure
observed : str
a column name of df with the observed target
predicted : DataFrame
a dataframe, with the same index as df, with the predicted target
fill_legend : bool, default=False
whether to show fill_between legend
"""
# aggregate observed and predicted variables by feature level
df_ = df.loc[:, [feature, weight]].copy()
df_["observed"] = df[observed] * df[weight]
df_["predicted"] = predicted * df[weight]
df_ = (
df_.groupby([feature])[[weight, "observed", "predicted"]]
.sum()
.assign(observed=lambda x: x["observed"] / x[weight])
.assign(predicted=lambda x: x["predicted"] / x[weight])
)
ax = df_.loc[:, ["observed", "predicted"]].plot(style=".", ax=ax)
y_max = df_.loc[:, ["observed", "predicted"]].values.max() * 0.8
p2 = ax.fill_between(
df_.index,
0,
y_max * df_[weight] / df_[weight].values.max(),
color="g",
alpha=0.1,
)
if fill_legend:
ax.legend([p2], ["{} distribution".format(feature)])
ax.set(
ylabel=y_label if y_label is not None else None,
title=title if title is not None else "Train: Observed vs Predicted",
)
def score_estimator(
estimator,
X_train,
X_test,
df_train,
df_test,
target,
weights,
tweedie_powers=None,
):
"""Evaluate an estimator on train and test sets with different metrics"""
metrics = [
("D² explained", None), # Use default scorer if it exists
("mean abs. error", mean_absolute_error),
("mean squared error", mean_squared_error),
]
if tweedie_powers:
metrics += [
(
"mean Tweedie dev p={:.4f}".format(power),
partial(mean_tweedie_deviance, power=power),
)
for power in tweedie_powers
]
res = []
for subset_label, X, df in [
("train", X_train, df_train),
("test", X_test, df_test),
]:
y, _weights = df[target], df[weights]
for score_label, metric in metrics:
if isinstance(estimator, tuple) and len(estimator) == 2:
# Score the model consisting of the product of frequency and
# severity models.
est_freq, est_sev = estimator
y_pred = est_freq.predict(X) * est_sev.predict(X)
else:
y_pred = estimator.predict(X)
if metric is None:
if not hasattr(estimator, "score"):
continue
score = estimator.score(X, y, sample_weight=_weights)
else:
score = metric(y, y_pred, sample_weight=_weights)
res.append({"subset": subset_label, "metric": score_label, "score": score})
res = (
pd.DataFrame(res)
.set_index(["metric", "subset"])
.score.unstack(-1)
.round(4)
.loc[:, ["train", "test"]]
)
return res
加载数据集、基本特征提取和目标定义#
我们通过连接包含理赔数量 (ClaimNb) 的 freMTPL2freq 表和包含相同保单 ID (IDpol) 理赔金额 (ClaimAmount) 的 freMTPL2sev 表来构建 freMTPL2 数据集。
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import (
FunctionTransformer,
KBinsDiscretizer,
OneHotEncoder,
StandardScaler,
)
df = load_mtpl2()
# Correct for unreasonable observations (that might be data error)
# and a few exceptionally large claim amounts
df["ClaimNb"] = df["ClaimNb"].clip(upper=4)
df["Exposure"] = df["Exposure"].clip(upper=1)
df["ClaimAmount"] = df["ClaimAmount"].clip(upper=200000)
# If the claim amount is 0, then we do not count it as a claim. The loss function
# used by the severity model needs strictly positive claim amounts. This way
# frequency and severity are more consistent with each other.
df.loc[(df["ClaimAmount"] == 0) & (df["ClaimNb"] >= 1), "ClaimNb"] = 0
log_scale_transformer = make_pipeline(
FunctionTransformer(func=np.log), StandardScaler()
)
column_trans = ColumnTransformer(
[
(
"binned_numeric",
KBinsDiscretizer(
n_bins=10, quantile_method="averaged_inverted_cdf", random_state=0
),
["VehAge", "DrivAge"],
),
(
"onehot_categorical",
OneHotEncoder(),
["VehBrand", "VehPower", "VehGas", "Region", "Area"],
),
("passthrough_numeric", "passthrough", ["BonusMalus"]),
("log_scaled_numeric", log_scale_transformer, ["Density"]),
],
remainder="drop",
)
X = column_trans.fit_transform(df)
# Insurances companies are interested in modeling the Pure Premium, that is
# the expected total claim amount per unit of exposure for each policyholder
# in their portfolio:
df["PurePremium"] = df["ClaimAmount"] / df["Exposure"]
# This can be indirectly approximated by a 2-step modeling: the product of the
# Frequency times the average claim amount per claim:
df["Frequency"] = df["ClaimNb"] / df["Exposure"]
df["AvgClaimAmount"] = df["ClaimAmount"] / np.fmax(df["ClaimNb"], 1)
with pd.option_context("display.max_columns", 15):
print(df[df.ClaimAmount > 0].head())
ClaimNb Exposure Area VehPower VehAge DrivAge BonusMalus VehBrand \
IDpol
139 1 0.75 F 7 1 61 50 B12
190 1 0.14 B 12 5 50 60 B12
414 1 0.14 E 4 0 36 85 B12
424 2 0.62 F 10 0 51 100 B12
463 1 0.31 A 5 0 45 50 B12
VehGas Density Region ClaimAmount PurePremium Frequency \
IDpol
139 'Regular' 27000 R11 303.00 404.000000 1.333333
190 'Diesel' 56 R25 1981.84 14156.000000 7.142857
414 'Regular' 4792 R11 1456.55 10403.928571 7.142857
424 'Regular' 27000 R11 10834.00 17474.193548 3.225806
463 'Regular' 12 R73 3986.67 12860.225806 3.225806
AvgClaimAmount
IDpol
139 303.00
190 1981.84
414 1456.55
424 5417.00
463 3986.67
频率模型 – 泊松分布#
理赔数量 (ClaimNb) 是一个正整数(包括0)。因此,此目标可以用泊松分布建模。它被假定为在给定时间间隔(Exposure,以年为单位)内以恒定速率发生的离散事件数量。在这里,我们建模频率 y = ClaimNb / Exposure,它仍然是一个(缩放的)泊松分布,并使用 Exposure 作为 sample_weight。
from sklearn.linear_model import PoissonRegressor
from sklearn.model_selection import train_test_split
df_train, df_test, X_train, X_test = train_test_split(df, X, random_state=0)
请记住,尽管此数据集中的数据点数量看似庞大,但理赔金额非零的评估点数量却相当少
len(df_test)
169504
len(df_test[df_test["ClaimAmount"] > 0])
6237
因此,我们预计在训练测试集随机重采样后,我们的评估结果会有显著的变异性。
模型的参数通过牛顿解算器最小化训练集上的泊松离差来估计。部分特征是共线的(例如,因为我们没有在 OneHotEncoder 中丢弃任何类别级别),我们使用弱 L2 惩罚以避免数值问题。
glm_freq = PoissonRegressor(alpha=1e-4, solver="newton-cholesky")
glm_freq.fit(X_train, df_train["Frequency"], sample_weight=df_train["Exposure"])
scores = score_estimator(
glm_freq,
X_train,
X_test,
df_train,
df_test,
target="Frequency",
weights="Exposure",
)
print("Evaluation of PoissonRegressor on target Frequency")
print(scores)
Evaluation of PoissonRegressor on target Frequency
subset train test
metric
D² explained 0.0448 0.0427
mean abs. error 0.1379 0.1378
mean squared error 0.2441 0.2246
请注意,测试集上的分数出奇地优于训练集。这可能是此随机训练-测试分割的特例。适当的交叉验证可以帮助我们评估这些结果的采样变异性。
我们可以通过驾驶员年龄 (DrivAge)、车龄 (VehAge) 和保险奖惩 (BonusMalus) 聚合,可视化比较观测值和预测值。
fig, ax = plt.subplots(ncols=2, nrows=2, figsize=(16, 8))
fig.subplots_adjust(hspace=0.3, wspace=0.2)
plot_obs_pred(
df=df_train,
feature="DrivAge",
weight="Exposure",
observed="Frequency",
predicted=glm_freq.predict(X_train),
y_label="Claim Frequency",
title="train data",
ax=ax[0, 0],
)
plot_obs_pred(
df=df_test,
feature="DrivAge",
weight="Exposure",
observed="Frequency",
predicted=glm_freq.predict(X_test),
y_label="Claim Frequency",
title="test data",
ax=ax[0, 1],
fill_legend=True,
)
plot_obs_pred(
df=df_test,
feature="VehAge",
weight="Exposure",
observed="Frequency",
predicted=glm_freq.predict(X_test),
y_label="Claim Frequency",
title="test data",
ax=ax[1, 0],
fill_legend=True,
)
plot_obs_pred(
df=df_test,
feature="BonusMalus",
weight="Exposure",
observed="Frequency",
predicted=glm_freq.predict(X_test),
y_label="Claim Frequency",
title="test data",
ax=ax[1, 1],
fill_legend=True,
)
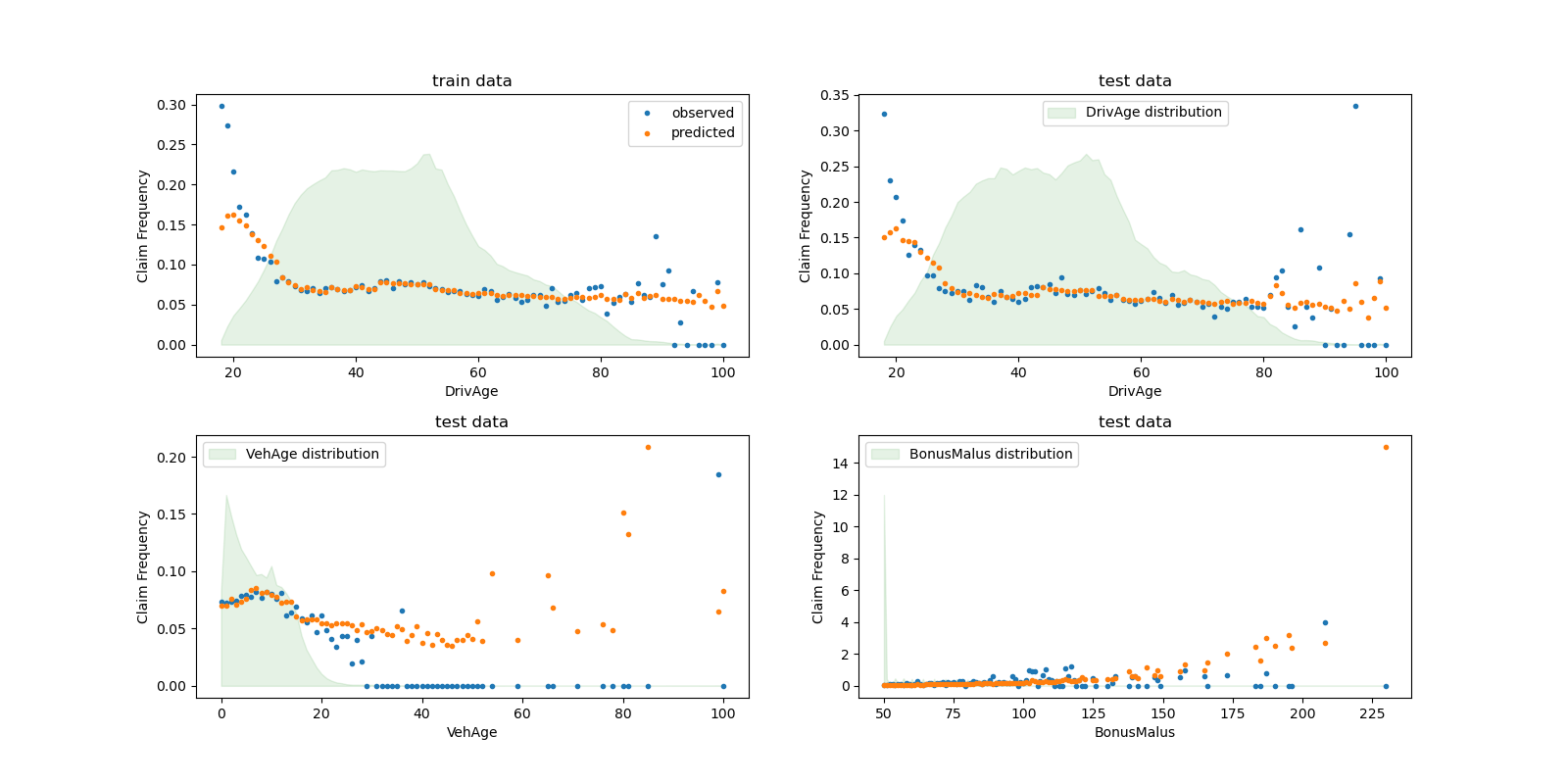
根据观测数据,30岁以下驾驶员的事故频率较高,并且与 BonusMalus 变量呈正相关。我们的模型能够基本正确地建模这种行为。
赔付金额模型 - Gamma 分布#
平均理赔金额或赔付金额 (AvgClaimAmount) 经验上表明近似遵循 Gamma 分布。我们使用与频率模型相同的特征拟合了一个 GLM 模型来预测赔付金额。
注意
我们过滤掉
ClaimAmount == 0的情况,因为 Gamma 分布的支持域是 \((0, \infty)\),而不是 \([0, \infty)\)。我们使用
ClaimNb作为sample_weight,以考虑到包含多个理赔的保单。
from sklearn.linear_model import GammaRegressor
mask_train = df_train["ClaimAmount"] > 0
mask_test = df_test["ClaimAmount"] > 0
glm_sev = GammaRegressor(alpha=10.0, solver="newton-cholesky")
glm_sev.fit(
X_train[mask_train.values],
df_train.loc[mask_train, "AvgClaimAmount"],
sample_weight=df_train.loc[mask_train, "ClaimNb"],
)
scores = score_estimator(
glm_sev,
X_train[mask_train.values],
X_test[mask_test.values],
df_train[mask_train],
df_test[mask_test],
target="AvgClaimAmount",
weights="ClaimNb",
)
print("Evaluation of GammaRegressor on target AvgClaimAmount")
print(scores)
Evaluation of GammaRegressor on target AvgClaimAmount
subset train test
metric
D² explained 3.900000e-03 4.400000e-03
mean abs. error 1.756752e+03 1.744055e+03
mean squared error 5.801775e+07 5.030676e+07
这些指标值不一定容易解释。在相同设置下,将它们与不使用任何输入特征且始终预测一个常数值(即平均理赔金额)的模型进行比较可能会很有启发性
from sklearn.dummy import DummyRegressor
dummy_sev = DummyRegressor(strategy="mean")
dummy_sev.fit(
X_train[mask_train.values],
df_train.loc[mask_train, "AvgClaimAmount"],
sample_weight=df_train.loc[mask_train, "ClaimNb"],
)
scores = score_estimator(
dummy_sev,
X_train[mask_train.values],
X_test[mask_test.values],
df_train[mask_train],
df_test[mask_test],
target="AvgClaimAmount",
weights="ClaimNb",
)
print("Evaluation of a mean predictor on target AvgClaimAmount")
print(scores)
Evaluation of a mean predictor on target AvgClaimAmount
subset train test
metric
D² explained 0.000000e+00 -0.000000e+00
mean abs. error 1.756687e+03 1.744497e+03
mean squared error 5.803882e+07 5.033764e+07
我们得出结论,理赔金额非常难以预测。尽管如此,GammaRegressor 仍能利用输入特征中的一些信息,在 D² 方面略微优于平均基线。
请注意,由此产生的模型是每次理赔的平均金额。因此,它以至少有一个理赔为条件,不能用于预测每份保单的平均理赔金额。为此,它需要与理赔频率模型结合使用。
print(
"Mean AvgClaim Amount per policy: %.2f "
% df_train["AvgClaimAmount"].mean()
)
print(
"Mean AvgClaim Amount | NbClaim > 0: %.2f"
% df_train["AvgClaimAmount"][df_train["AvgClaimAmount"] > 0].mean()
)
print(
"Predicted Mean AvgClaim Amount | NbClaim > 0: %.2f"
% glm_sev.predict(X_train).mean()
)
print(
"Predicted Mean AvgClaim Amount (dummy) | NbClaim > 0: %.2f"
% dummy_sev.predict(X_train).mean()
)
Mean AvgClaim Amount per policy: 71.78
Mean AvgClaim Amount | NbClaim > 0: 1951.21
Predicted Mean AvgClaim Amount | NbClaim > 0: 1940.95
Predicted Mean AvgClaim Amount (dummy) | NbClaim > 0: 1978.59
我们可以可视化比较按驾驶员年龄 (DrivAge) 聚合的观测值和预测值。
fig, ax = plt.subplots(ncols=1, nrows=2, figsize=(16, 6))
plot_obs_pred(
df=df_train.loc[mask_train],
feature="DrivAge",
weight="Exposure",
observed="AvgClaimAmount",
predicted=glm_sev.predict(X_train[mask_train.values]),
y_label="Average Claim Severity",
title="train data",
ax=ax[0],
)
plot_obs_pred(
df=df_test.loc[mask_test],
feature="DrivAge",
weight="Exposure",
observed="AvgClaimAmount",
predicted=glm_sev.predict(X_test[mask_test.values]),
y_label="Average Claim Severity",
title="test data",
ax=ax[1],
fill_legend=True,
)
plt.tight_layout()
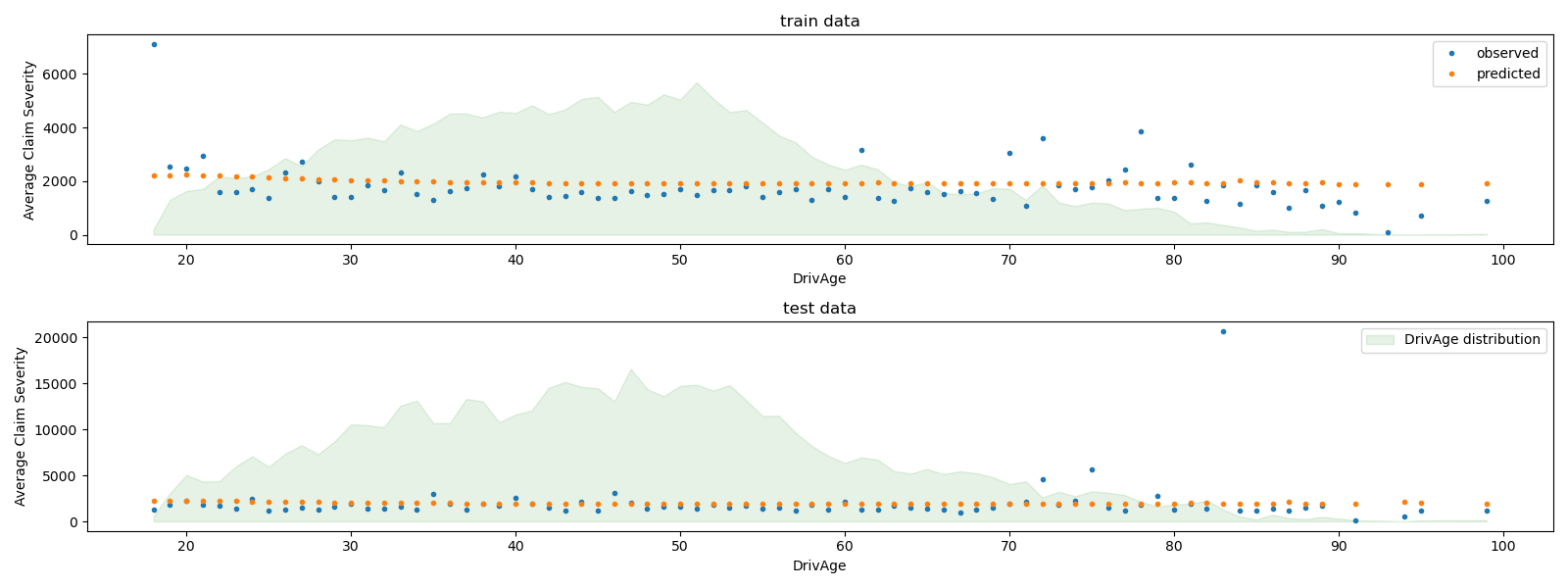
总体而言,驾驶员年龄 (DrivAge) 对理赔赔付金额的影响很小,无论是观测数据还是预测数据均如此。
通过乘积模型与单个 TweedieRegressor 进行纯保费建模#
如引言所述,每单位风险暴露的总理赔金额可以建模为频率模型预测与赔付金额模型预测的乘积。
或者,可以直接使用独特的复合泊松-Gamma 广义线性模型(带对数链接函数)来建模总损失。此模型是 Tweedie GLM 的特例,其“幂”参数为 \(p \in (1, 2)\)。在此,我们预先将 Tweedie 模型的 power 参数固定为有效范围内的某个任意值(1.9)。理想情况下,可以通过网格搜索,最小化 Tweedie 模型的负对数似然来选择此值,但遗憾的是,当前实现(尚)不支持此功能。
我们将比较这两种方法的性能。为了量化两个模型的性能,可以计算训练数据和测试数据的平均离差,假设总理赔金额遵循复合泊松-Gamma 分布。这等同于使用幂参数在 1 到 2 之间的 Tweedie 分布。
sklearn.metrics.mean_tweedie_deviance 依赖于一个 power 参数。由于我们不知道 power 参数的真实值,因此在此我们计算一系列可能值的平均离差,并并排比较这些模型,即在相同的 power 值下进行比较。理想情况下,我们希望一个模型能够持续优于另一个模型,无论 power 值如何。
from sklearn.linear_model import TweedieRegressor
glm_pure_premium = TweedieRegressor(power=1.9, alpha=0.1, solver="newton-cholesky")
glm_pure_premium.fit(
X_train, df_train["PurePremium"], sample_weight=df_train["Exposure"]
)
tweedie_powers = [1.5, 1.7, 1.8, 1.9, 1.99, 1.999, 1.9999]
scores_product_model = score_estimator(
(glm_freq, glm_sev),
X_train,
X_test,
df_train,
df_test,
target="PurePremium",
weights="Exposure",
tweedie_powers=tweedie_powers,
)
scores_glm_pure_premium = score_estimator(
glm_pure_premium,
X_train,
X_test,
df_train,
df_test,
target="PurePremium",
weights="Exposure",
tweedie_powers=tweedie_powers,
)
scores = pd.concat(
[scores_product_model, scores_glm_pure_premium],
axis=1,
sort=True,
keys=("Product Model", "TweedieRegressor"),
)
print("Evaluation of the Product Model and the Tweedie Regressor on target PurePremium")
with pd.option_context("display.expand_frame_repr", False):
print(scores)
Evaluation of the Product Model and the Tweedie Regressor on target PurePremium
Product Model TweedieRegressor
subset train test train test
metric
D² explained NaN NaN 1.640000e-02 1.370000e-02
mean Tweedie dev p=1.5000 7.670090e+01 7.616900e+01 7.640460e+01 7.641980e+01
mean Tweedie dev p=1.7000 3.695810e+01 3.683920e+01 3.682720e+01 3.692730e+01
mean Tweedie dev p=1.8000 3.046050e+01 3.040490e+01 3.037490e+01 3.045690e+01
mean Tweedie dev p=1.9000 3.387610e+01 3.384970e+01 3.382040e+01 3.388020e+01
mean Tweedie dev p=1.9900 2.015718e+02 2.015412e+02 2.015342e+02 2.015600e+02
mean Tweedie dev p=1.9990 1.914574e+03 1.914370e+03 1.914537e+03 1.914388e+03
mean Tweedie dev p=1.9999 1.904751e+04 1.904556e+04 1.904747e+04 1.904558e+04
mean abs. error 2.730129e+02 2.722124e+02 2.740176e+02 2.731633e+02
mean squared error 3.295040e+07 3.212197e+07 3.295518e+07 3.213087e+07
在本示例中,两种建模方法都产生了可比较的性能指标。出于实现原因,乘积模型没有解释方差百分比 \(D^2\)。
我们还可以通过比较测试集和训练子集上的观测和预测总理赔金额来额外验证这些模型。我们看到,平均而言,两个模型都倾向于低估总理赔金额(但这种行为取决于正则化量)。
res = []
for subset_label, X, df in [
("train", X_train, df_train),
("test", X_test, df_test),
]:
exposure = df["Exposure"].values
res.append(
{
"subset": subset_label,
"observed": df["ClaimAmount"].values.sum(),
"predicted, frequency*severity model": np.sum(
exposure * glm_freq.predict(X) * glm_sev.predict(X)
),
"predicted, tweedie, power=%.2f" % glm_pure_premium.power: np.sum(
exposure * glm_pure_premium.predict(X)
),
}
)
print(pd.DataFrame(res).set_index("subset").T)
subset train test
observed 3.917618e+07 1.299546e+07
predicted, frequency*severity model 3.916579e+07 1.313280e+07
predicted, tweedie, power=1.90 3.952914e+07 1.325666e+07
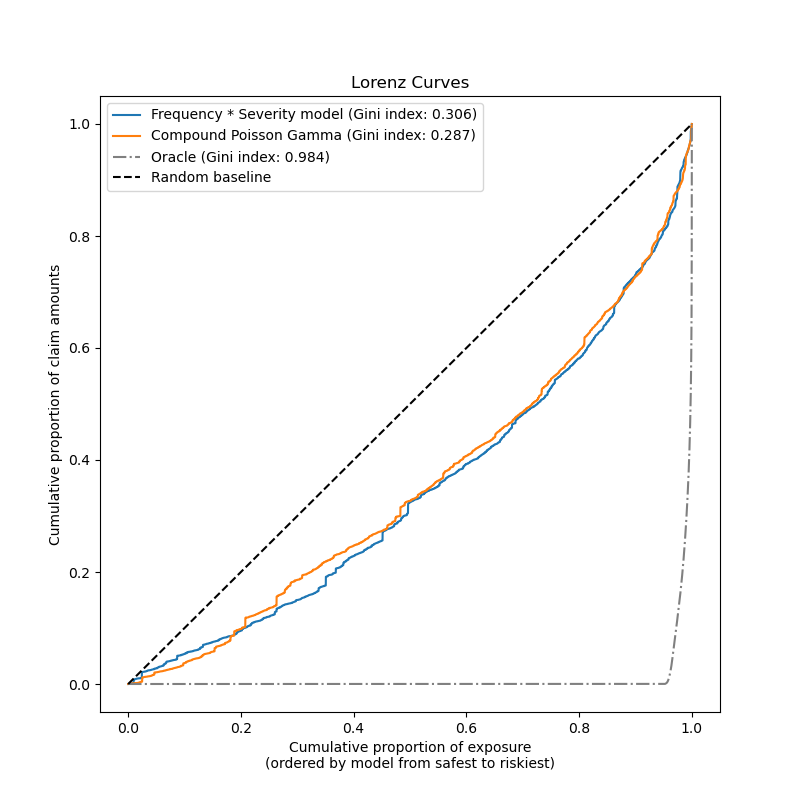
最后,我们可以使用累计理赔图来比较这两个模型:对于每个模型,根据模型预测将投保人从最安全到最风险进行排名,并绘制理赔金额的累计比例与风险暴露的累计比例的图。此图通常称为模型的有序 Lorenz 曲线。
基尼系数(基于曲线与对角线之间的面积)可以用作模型选择指标,以量化模型对投保人进行排名的能力。请注意,此指标不反映模型在总理赔金额绝对值方面进行准确预测的能力,而仅反映作为排名指标的相对金额。基尼系数的上限为 1.0,但即使是根据观测理赔金额对投保人进行排名的神谕模型也无法达到 1.0 的分数。
我们观察到,尽管这两个模型都因预测问题的内在难度(基于少量特征)而远未达到神谕模型的水平,但它们在按风险程度对投保人进行排名方面,均显著优于随机猜测:大多数事故是不可预测的,并且可能由模型的输入特征完全未描述的环境因素引起。
请注意,基尼指数仅表征模型的排名性能,而非其校准:任何对预测的单调变换都不会改变模型的基尼指数。
最后应该强调的是,直接拟合纯保费的复合泊松-Gamma 模型在操作上更易于开发和维护,因为它只包含一个 scikit-learn 估计器,而不是一对各自具有超参数的模型。
from sklearn.metrics import auc
def lorenz_curve(y_true, y_pred, exposure):
y_true, y_pred = np.asarray(y_true), np.asarray(y_pred)
exposure = np.asarray(exposure)
# order samples by increasing predicted risk:
ranking = np.argsort(y_pred)
ranked_exposure = exposure[ranking]
ranked_pure_premium = y_true[ranking]
cumulative_claim_amount = np.cumsum(ranked_pure_premium * ranked_exposure)
cumulative_claim_amount /= cumulative_claim_amount[-1]
cumulative_exposure = np.cumsum(ranked_exposure)
cumulative_exposure /= cumulative_exposure[-1]
return cumulative_exposure, cumulative_claim_amount
fig, ax = plt.subplots(figsize=(8, 8))
y_pred_product = glm_freq.predict(X_test) * glm_sev.predict(X_test)
y_pred_total = glm_pure_premium.predict(X_test)
for label, y_pred in [
("Frequency * Severity model", y_pred_product),
("Compound Poisson Gamma", y_pred_total),
]:
cum_exposure, cum_claims = lorenz_curve(
df_test["PurePremium"], y_pred, df_test["Exposure"]
)
gini = 1 - 2 * auc(cum_exposure, cum_claims)
label += " (Gini index: {:.3f})".format(gini)
ax.plot(cum_exposure, cum_claims, linestyle="-", label=label)
# Oracle model: y_pred == y_test
cum_exposure, cum_claims = lorenz_curve(
df_test["PurePremium"], df_test["PurePremium"], df_test["Exposure"]
)
gini = 1 - 2 * auc(cum_exposure, cum_claims)
label = "Oracle (Gini index: {:.3f})".format(gini)
ax.plot(cum_exposure, cum_claims, linestyle="-.", color="gray", label=label)
# Random baseline
ax.plot([0, 1], [0, 1], linestyle="--", color="black", label="Random baseline")
ax.set(
title="Lorenz Curves",
xlabel=(
"Cumulative proportion of exposure\n(ordered by model from safest to riskiest)"
),
ylabel="Cumulative proportion of claim amounts",
)
ax.legend(loc="upper left")
plt.plot()
[]
脚本总运行时间: (0 分钟 7.329 秒)
相关示例