章节导航
__sklearn_is_fitted__
FrozenEstimator
set_output
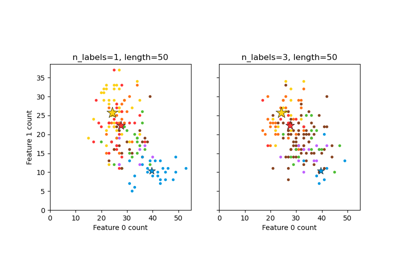
关于 sklearn.datasets 模块的示例。
sklearn.datasets
绘制随机生成的多标签数据集