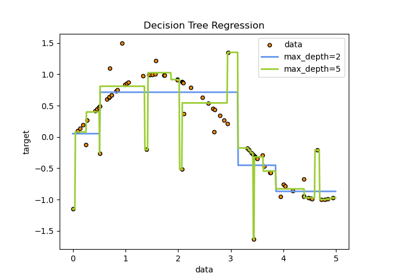
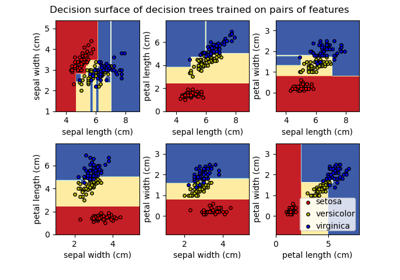
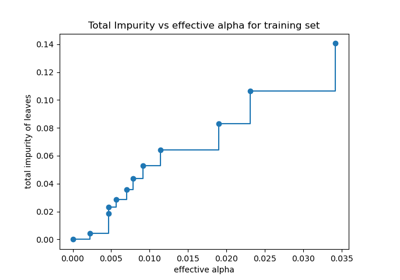
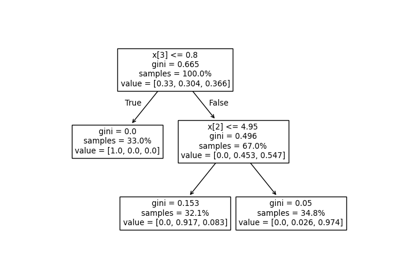
决策树# 关于 sklearn.tree 模块的示例。 决策树回归 决策树回归 绘制鸢尾花数据集上训练的决策树的决策边界 绘制鸢尾花数据集上训练的决策树的决策边界 使用成本复杂度剪枝对决策树进行后剪枝 使用成本复杂度剪枝对决策树进行后剪枝 理解决策树结构 理解决策树结构