注意
转到末尾 下载完整示例代码。或通过 JupyterLite 或 Binder 在浏览器中运行此示例
普通最小二乘法和岭回归#
普通最小二乘法:我们演示如何在糖尿病数据集的单个特征上使用普通最小二乘法 (OLS) 模型,
LinearRegression。我们在数据子集上进行训练,在测试集上进行评估,并可视化预测。普通最小二乘法和岭回归方差:我们接着展示当数据稀疏或嘈杂时,OLS 如何通过重复拟合非常小的合成样本而导致高方差。岭回归(
Ridge)通过惩罚(收缩)系数来减少这种方差,从而产生更稳定的预测。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
数据加载与准备#
加载糖尿病数据集。为简单起见,我们只保留数据中的一个特征。然后,我们将数据和目标拆分为训练集和测试集。
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
X, y = load_diabetes(return_X_y=True)
X = X[:, [2]] # Use only one feature
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=20, shuffle=False)
线性回归模型#
我们创建一个线性回归模型并在训练数据上拟合它。请注意,默认情况下,模型会添加一个截距。我们可以通过设置 fit_intercept 参数来控制此行为。
from sklearn.linear_model import LinearRegression
regressor = LinearRegression().fit(X_train, y_train)
模型评估#
我们使用均方误差和决定系数评估模型在测试集上的性能。
from sklearn.metrics import mean_squared_error, r2_score
y_pred = regressor.predict(X_test)
print(f"Mean squared error: {mean_squared_error(y_test, y_pred):.2f}")
print(f"Coefficient of determination: {r2_score(y_test, y_pred):.2f}")
Mean squared error: 2548.07
Coefficient of determination: 0.47
绘制结果#
最后,我们可视化训练和测试数据上的结果。
import matplotlib.pyplot as plt
fig, ax = plt.subplots(ncols=2, figsize=(10, 5), sharex=True, sharey=True)
ax[0].scatter(X_train, y_train, label="Train data points")
ax[0].plot(
X_train,
regressor.predict(X_train),
linewidth=3,
color="tab:orange",
label="Model predictions",
)
ax[0].set(xlabel="Feature", ylabel="Target", title="Train set")
ax[0].legend()
ax[1].scatter(X_test, y_test, label="Test data points")
ax[1].plot(X_test, y_pred, linewidth=3, color="tab:orange", label="Model predictions")
ax[1].set(xlabel="Feature", ylabel="Target", title="Test set")
ax[1].legend()
fig.suptitle("Linear Regression")
plt.show()
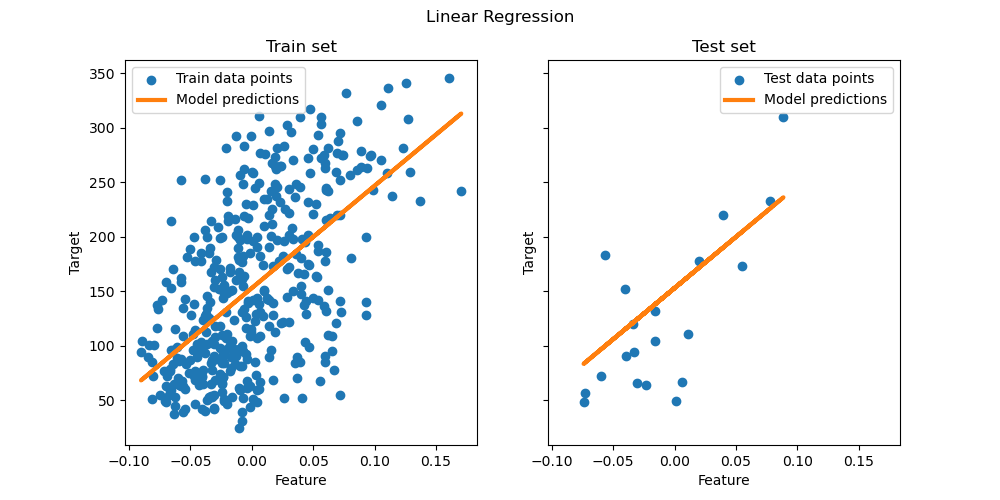
在此单特征子集上,OLS 学习一个线性函数,该函数使训练数据上的均方误差最小化。通过查看测试集上的 R^2 分数和均方误差,我们可以了解其泛化能力(好坏)。在更高维度中,纯 OLS 经常过拟合,特别是当数据嘈杂时。正则化技术(如 Ridge 或 Lasso)可以帮助减少这种情况。
普通最小二乘法和岭回归方差#
接下来,我们通过使用一个微小的合成数据集更清楚地说明高方差问题。我们只采样两个数据点,然后重复地向它们添加小的 Gaussian 噪声并重新拟合 OLS 和 Ridge。我们绘制每条新线以查看 OLS 的波动程度,而 Ridge 由于其惩罚项而保持更稳定。
import matplotlib.pyplot as plt
import numpy as np
from sklearn import linear_model
X_train = np.c_[0.5, 1].T
y_train = [0.5, 1]
X_test = np.c_[0, 2].T
np.random.seed(0)
classifiers = dict(
ols=linear_model.LinearRegression(), ridge=linear_model.Ridge(alpha=0.1)
)
for name, clf in classifiers.items():
fig, ax = plt.subplots(figsize=(4, 3))
for _ in range(6):
this_X = 0.1 * np.random.normal(size=(2, 1)) + X_train
clf.fit(this_X, y_train)
ax.plot(X_test, clf.predict(X_test), color="gray")
ax.scatter(this_X, y_train, s=3, c="gray", marker="o", zorder=10)
clf.fit(X_train, y_train)
ax.plot(X_test, clf.predict(X_test), linewidth=2, color="blue")
ax.scatter(X_train, y_train, s=30, c="red", marker="+", zorder=10)
ax.set_title(name)
ax.set_xlim(0, 2)
ax.set_ylim((0, 1.6))
ax.set_xlabel("X")
ax.set_ylabel("y")
fig.tight_layout()
plt.show()
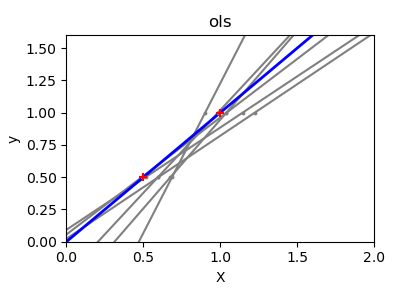
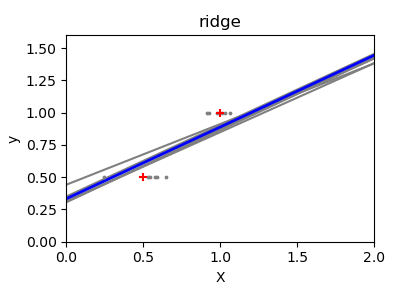
结论#
在第一个示例中,我们将 OLS 应用于真实数据集,展示了简单线性模型如何通过最小化训练集上的平方误差来拟合数据。
在第二个示例中,每次添加噪声时 OLS 直线都发生剧烈变化,这反映了当数据稀疏或嘈杂时其高方差。相比之下,岭回归引入了一个正则化项,该项收缩系数,从而稳定预测。
像 Ridge 或 Lasso(应用 L1 惩罚)这样的技术都是提高泛化能力和减少过拟合的常用方法。当特征相关、数据嘈杂或样本量较小时,经过良好调整的 Ridge 或 Lasso 通常优于纯 OLS。
脚本总运行时间: (0 分钟 0.411 秒)
相关示例