注意
跳转到末尾下载完整示例代码,或通过JupyterLite或Binder在浏览器中运行此示例
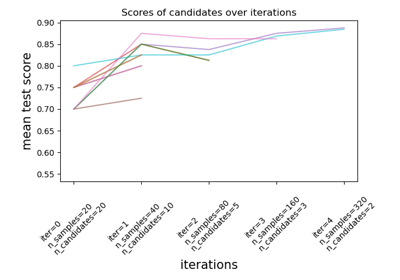
比较用于超参数估计的随机搜索和网格搜索#
比较随机搜索和网格搜索在SGD训练的线性SVM中优化超参数。所有影响学习的参数同时进行搜索(除了估计器数量,这涉及到时间/质量权衡)。
随机搜索和网格搜索探索完全相同的参数空间。参数设置的结果非常相似,但随机搜索的运行时间大大缩短。
随机搜索的性能可能略差,这很可能是由于噪声效应,并且不会延续到保留的测试集。
请注意,在实践中,人们不会使用网格搜索同时搜索如此多的不同参数,而只会选择那些被认为最重要的参数。
RandomizedSearchCV took 0.58 seconds for 15 candidates parameter settings.
Model with rank: 1
Mean validation score: 0.987 (std: 0.011)
Parameters: {'alpha': np.float64(0.01001911984591966), 'average': False, 'l1_ratio': np.float64(0.7665012035905148)}
Model with rank: 2
Mean validation score: 0.987 (std: 0.011)
Parameters: {'alpha': np.float64(0.40134964872774576), 'average': False, 'l1_ratio': np.float64(0.05033776045421079)}
Model with rank: 3
Mean validation score: 0.983 (std: 0.011)
Parameters: {'alpha': np.float64(0.1352374671440465), 'average': False, 'l1_ratio': np.float64(0.6719936995475292)}
GridSearchCV took 3.28 seconds for 60 candidate parameter settings.
Model with rank: 1
Mean validation score: 0.994 (std: 0.005)
Parameters: {'alpha': np.float64(0.1), 'average': False, 'l1_ratio': np.float64(0.1111111111111111)}
Model with rank: 2
Mean validation score: 0.991 (std: 0.008)
Parameters: {'alpha': np.float64(0.1), 'average': False, 'l1_ratio': np.float64(0.0)}
Model with rank: 3
Mean validation score: 0.989 (std: 0.018)
Parameters: {'alpha': np.float64(1.0), 'average': False, 'l1_ratio': np.float64(0.0)}
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
from time import time
import numpy as np
import scipy.stats as stats
from sklearn.datasets import load_digits
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
# get some data
X, y = load_digits(return_X_y=True, n_class=3)
# build a classifier
clf = SGDClassifier(loss="hinge", penalty="elasticnet", fit_intercept=True)
# Utility function to report best scores
def report(results, n_top=3):
for i in range(1, n_top + 1):
candidates = np.flatnonzero(results["rank_test_score"] == i)
for candidate in candidates:
print("Model with rank: {0}".format(i))
print(
"Mean validation score: {0:.3f} (std: {1:.3f})".format(
results["mean_test_score"][candidate],
results["std_test_score"][candidate],
)
)
print("Parameters: {0}".format(results["params"][candidate]))
print("")
# specify parameters and distributions to sample from
param_dist = {
"average": [True, False],
"l1_ratio": stats.uniform(0, 1),
"alpha": stats.loguniform(1e-2, 1e0),
}
# run randomized search
n_iter_search = 15
random_search = RandomizedSearchCV(
clf, param_distributions=param_dist, n_iter=n_iter_search
)
start = time()
random_search.fit(X, y)
print(
"RandomizedSearchCV took %.2f seconds for %d candidates parameter settings."
% ((time() - start), n_iter_search)
)
report(random_search.cv_results_)
# use a full grid over all parameters
param_grid = {
"average": [True, False],
"l1_ratio": np.linspace(0, 1, num=10),
"alpha": np.power(10, np.arange(-2, 1, dtype=float)),
}
# run grid search
grid_search = GridSearchCV(clf, param_grid=param_grid)
start = time()
grid_search.fit(X, y)
print(
"GridSearchCV took %.2f seconds for %d candidate parameter settings."
% (time() - start, len(grid_search.cv_results_["params"]))
)
report(grid_search.cv_results_)
脚本总运行时间: (0分钟 3.871秒)
相关示例