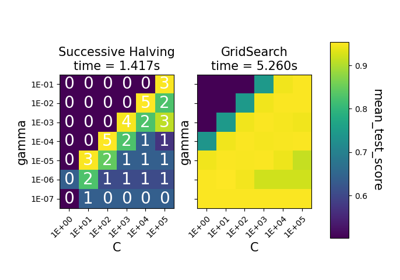
GridSearchCV#
- class sklearn.model_selection.GridSearchCV(estimator, param_grid, *, scoring=None, n_jobs=None, refit=True, cv=None, verbose=0, pre_dispatch='2*n_jobs', error_score=nan, return_train_score=False)[source]#
对估计器的指定参数值进行详尽搜索。
重要的成员包括 fit 和 predict。
GridSearchCV 实现了“fit”和“score”方法。如果所使用的估计器中实现了“score_samples”、“predict”、“predict_proba”、“decision_function”、“transform”和“inverse_transform”,它也会实现这些方法。
用于应用这些方法的估计器参数通过交叉验证的网格搜索在参数网格上进行优化。
欲了解更多信息,请参阅用户指南。
- 参数:
- estimator估计器对象
假定此估计器实现了 scikit-learn 估计器接口。估计器需要提供一个
score函数,或者必须传入scoring参数。- param_grid字典或字典列表
字典的键是参数名称 (
str),值是要尝试的参数设置列表;或者是一个包含此类字典的列表,在这种情况下,将探索列表中每个字典所涵盖的网格。这使得可以搜索任何参数设置序列。- scoring字符串、可调用对象、列表、元组或字典,默认为 None
用于评估交叉验证模型在测试集上性能的策略。
如果
scoring表示单个评分,可以使用:如果
scoring表示多个评分,可以使用:唯一的字符串列表或元组;
返回字典的可调用对象,其中键是度量名称,值是度量分数;
以度量名称为键,以可调用对象为值的字典。
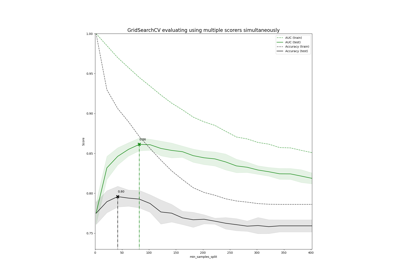
有关示例,请参阅指定多个评估指标。
- n_jobs整数,默认为 None
并行运行的作业数量。
None表示 1,除非在joblib.parallel_backend上下文中。-1表示使用所有处理器。有关更多详细信息,请参阅术语表。v0.20 版本中的变化:
n_jobs的默认值从 1 更改为 None。- refit布尔值、字符串或可调用对象,默认为 True
使用在整个数据集上找到的最佳参数重新拟合估计器。
对于多指标评估,这需要是一个
str,表示用于在结束时找到最佳参数以重新拟合估计器的评分器。如果在选择最佳估计器时除了最大分数之外还有其他考虑因素,
refit可以设置为一个函数,该函数在给定cv_results_的情况下返回选定的best_index_。在这种情况下,best_estimator_和best_params_将根据返回的best_index_设置,而best_score_属性将不可用。重新拟合的估计器可在
best_estimator_属性处获得,并允许直接在此GridSearchCV实例上使用predict。此外,对于多指标评估,只有在设置了
refit且所有属性都相对于此特定评分器确定时,属性best_index_、best_score_和best_params_才可用。有关多指标评估的更多信息,请参阅
scoring参数。请参阅带交叉验证的网格搜索的自定义重新拟合策略,了解如何通过
refit使用可调用对象设计自定义选择策略。有关如何使用
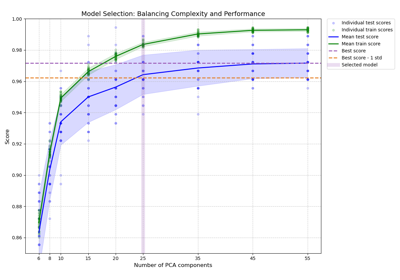
refit=callable来平衡模型复杂度和交叉验证分数的示例,请参阅此示例。0.20 版本中的变化: 增加了对可调用对象的支持。
- cv整数、交叉验证生成器或可迭代对象,默认为 None
确定交叉验证的拆分策略。cv 的可能输入包括:
None,使用默认的 5 折交叉验证;
整数,用于指定
(Stratified)KFold中的折叠数量;一个可迭代对象,生成 (训练集,测试集) 分割作为索引数组。
对于整数/None 输入,如果估计器是分类器且
y是二分类或多分类,则使用StratifiedKFold。在所有其他情况下,使用KFold。这些分割器在实例化时使用shuffle=False,因此在不同调用中分割将保持一致。有关此处可使用的各种交叉验证策略,请参阅用户指南。
0.22 版本中的变化: 如果为 None,
cv的默认值从 3 折交叉验证更改为 5 折交叉验证。- verbose整数
控制详细程度:值越高,消息越多。
>1:显示每个折叠和参数候选项的计算时间;
>2:同时显示分数;
>3:同时显示折叠和候选参数索引以及计算开始时间。
- pre_dispatch整数或字符串,默认为 ‘2*n_jobs’
控制并行执行期间分派的作业数量。当分派的作业数量多于 CPU 能处理的数量时,减少此数字有助于避免内存消耗的急剧增加。此参数可以是:
None,在这种情况下,所有作业会立即创建并启动。适用于轻量级和快速运行的作业,以避免因按需启动作业而导致的延迟。
一个整数,给出启动的总作业的确切数量。
一个字符串,给出作为 n_jobs 函数的表达式,例如 ‘2*n_jobs’。
- error_score‘raise’ 或数值,默认为 np.nan
如果估计器拟合过程中发生错误,则分配给分数的 S 值。如果设置为 ‘raise’,则会引发错误。如果给出数值,则会引发 FitFailedWarning。此参数不影响重新拟合步骤,重新拟合步骤将始终引发错误。
- return_train_score布尔值,默认为 False
如果为
False,则cv_results_属性将不包含训练分数。计算训练分数用于深入了解不同参数设置如何影响过拟合/欠拟合的权衡。然而,在训练集上计算分数可能计算量很大,并且并非严格需要才能选择产生最佳泛化性能的参数。0.19 版本新增。
0.21 版本中的变化: 默认值从
True更改为False。
- 属性:
- cv_results_numpy(掩码)ndarray 的字典
一个字典,其键为列标题,值为列数据,可以导入到 pandas
DataFrame中。例如,下表:
param_kernel
param_gamma
param_degree
split0_test_score
…
rank_t…
‘poly’
–
2
0.80
…
2
‘poly’
–
3
0.70
…
4
‘rbf’
0.1
–
0.80
…
3
‘rbf’
0.2
–
0.93
…
1
将由一个
cv_results_字典表示:{ 'param_kernel': masked_array(data = ['poly', 'poly', 'rbf', 'rbf'], mask = [False False False False]...) 'param_gamma': masked_array(data = [-- -- 0.1 0.2], mask = [ True True False False]...), 'param_degree': masked_array(data = [2.0 3.0 -- --], mask = [False False True True]...), 'split0_test_score' : [0.80, 0.70, 0.80, 0.93], 'split1_test_score' : [0.82, 0.50, 0.70, 0.78], 'mean_test_score' : [0.81, 0.60, 0.75, 0.85], 'std_test_score' : [0.01, 0.10, 0.05, 0.08], 'rank_test_score' : [2, 4, 3, 1], 'split0_train_score' : [0.80, 0.92, 0.70, 0.93], 'split1_train_score' : [0.82, 0.55, 0.70, 0.87], 'mean_train_score' : [0.81, 0.74, 0.70, 0.90], 'std_train_score' : [0.01, 0.19, 0.00, 0.03], 'mean_fit_time' : [0.73, 0.63, 0.43, 0.49], 'std_fit_time' : [0.01, 0.02, 0.01, 0.01], 'mean_score_time' : [0.01, 0.06, 0.04, 0.04], 'std_score_time' : [0.00, 0.00, 0.00, 0.01], 'params' : [{'kernel': 'poly', 'degree': 2}, ...], }
注意
键
'params'用于存储所有参数候选项的参数设置字典列表。mean_fit_time、std_fit_time、mean_score_time和std_score_time都以秒为单位。对于多指标评估,所有评分器的分数都可以在
cv_results_字典中找到,键名以该评分器的名称结尾('_<scorer_name>'),而不是上面显示的'_score'。(例如 ‘split0_test_precision’,‘mean_train_precision’ 等)- best_estimator_估计器
由搜索选择的估计器,即在留出数据上给出最高分数(或最小损失,如果指定)的估计器。如果
refit=False,则不可用。有关允许值的更多信息,请参阅
refit参数。- best_score_浮点数
best_estimator 的平均交叉验证分数
对于多指标评估,仅当指定了
refit时才存在。如果
refit是一个函数,则此属性不可用。- best_params_字典
在留出数据上给出最佳结果的参数设置。
对于多指标评估,仅当指定了
refit时才存在。- best_index_整数
与最佳候选参数设置相对应的索引(
cv_results_数组中的)。search.cv_results_['params'][search.best_index_]处的字典给出了最佳模型的参数设置,该模型给出了最高的平均分数(search.best_score_)。对于多指标评估,仅当指定了
refit时才存在。- scorer_函数或字典
用于在留出数据上选择模型最佳参数的评分函数。
对于多指标评估,此属性包含经过验证的
scoring字典,该字典将评分器键映射到可调用的评分器。- n_splits_整数
交叉验证分割(折叠/迭代)的数量。
- refit_time_浮点数
用于在整个数据集上重新拟合最佳模型的秒数。
仅当
refit不为 False 时才存在。0.20 版本新增。
- multimetric_布尔值
评分器是否计算多个指标。
classes_形状为 (n_classes,) 的 ndarray类别标签。
n_features_in_整数在拟合(fit)过程中看到的特征数量。
- feature_names_in_形状为 (
n_features_in_,) 的 ndarray 在拟合(fit)过程中看到的特征名称。仅当
best_estimator_已定义(有关详细信息,请参阅refit参数的文档)并且best_estimator_在拟合时公开feature_names_in_时才定义。1.0 版本新增。
另请参阅
ParameterGrid生成超参数网格的所有组合。
train_test_split将数据拆分为可用于拟合 GridSearchCV 实例的开发集和用于最终评估的评估集的实用函数。
sklearn.metrics.make_scorer从性能指标或损失函数创建评分器。
注意事项
选择的参数是那些最大化留出数据分数的参数,除非传入了显式分数,否则使用该分数。
如果
n_jobs设置为大于 1 的值,则数据会为网格中的每个点复制(而不是n_jobs倍)。这样做是为了效率考虑,如果单个作业耗时很短,但如果数据集很大且可用内存不足,则可能会引发错误。在这种情况下,一个解决方法是设置pre_dispatch。然后,内存只复制pre_dispatch次。pre_dispatch的合理值为2 * n_jobs。示例
>>> from sklearn import svm, datasets >>> from sklearn.model_selection import GridSearchCV >>> iris = datasets.load_iris() >>> parameters = {'kernel':('linear', 'rbf'), 'C':[1, 10]} >>> svc = svm.SVC() >>> clf = GridSearchCV(svc, parameters) >>> clf.fit(iris.data, iris.target) GridSearchCV(estimator=SVC(), param_grid={'C': [1, 10], 'kernel': ('linear', 'rbf')}) >>> sorted(clf.cv_results_.keys()) ['mean_fit_time', 'mean_score_time', 'mean_test_score',... 'param_C', 'param_kernel', 'params',... 'rank_test_score', 'split0_test_score',... 'split2_test_score', ... 'std_fit_time', 'std_score_time', 'std_test_score']
- decision_function(X)[source]#
使用找到的最佳参数调用估计器上的 `decision_function`。
仅当
refit=True且底层估计器支持decision_function时可用。- 参数:
- X可索引对象,长度为 n_samples
必须满足底层估计器的输入假设。
- 返回:
- y_score形状为 (n_samples,) 或 (n_samples, n_classes) 或 (n_samples, n_classes * (n_classes-1) / 2) 的 ndarray
基于使用最佳参数的估计器,对
X进行决策函数计算的结果。
- fit(X, y=None, **params)[source]#
使用所有参数集运行拟合。
- 参数:
- X形状为 (n_samples, n_features) 或 (n_samples, n_samples) 的类数组对象
训练向量,其中
n_samples是样本数量,n_features是特征数量。对于预计算的核或距离矩阵,X 的预期形状为 (n_samples, n_samples)。- y形状为 (n_samples, n_output) 或 (n_samples,) 的类数组对象,默认为 None
相对于 X 的分类或回归目标;无监督学习为 None。
- **params字符串到对象的字典
传递给估计器、评分器和 CV 分割器的
fit方法的参数。如果拟合参数是一个长度等于
num_samples的类数组,那么它将与X和y一起通过交叉验证进行分割。例如,sample_weight 参数会被分割,因为len(sample_weights) = len(X)。但是,此行为不适用于groups,后者通过构造函数的cv参数配置的分割器传递。因此,groups用于执行分割并确定哪些样本分配到分割的每一侧。
- 返回:
- self对象
拟合估计器的实例。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查阅用户指南以了解路由机制的工作原理。
1.4 版本新增。
- 返回:
- routingMetadataRouter
一个封装路由信息的
MetadataRouter。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deep布尔值,默认为 True
如果为 True,将返回此估计器及其包含的作为估计器的子对象的参数。
- 返回:
- params字典
参数名称及其对应值的映射。
- inverse_transform(X)[source]#
使用找到的最佳参数调用估计器上的 `inverse_transform`。
仅当底层估计器实现了
inverse_transform且refit=True时可用。- 参数:
- X可索引对象,长度为 n_samples
必须满足底层估计器的输入假设。
- 返回:
- X_original形状为 (n_samples, n_features) 的 {ndarray, 稀疏矩阵}
基于使用最佳参数的估计器,对
X执行inverse_transform函数的结果。
- predict(X)[source]#
使用找到的最佳参数调用估计器上的 `predict`。
仅当
refit=True且底层估计器支持predict时可用。- 参数:
- X可索引对象,长度为 n_samples
必须满足底层估计器的输入假设。
- 返回:
- y_pred形状为 (n_samples,) 的 ndarray
基于使用最佳参数的估计器,对
X的预测标签或值。
- predict_log_proba(X)[source]#
使用找到的最佳参数调用估计器上的 `predict_log_proba`。
仅当
refit=True且底层估计器支持predict_log_proba时可用。- 参数:
- X可索引对象,长度为 n_samples
必须满足底层估计器的输入假设。
- 返回:
- y_pred形状为 (n_samples,) 或 (n_samples, n_classes) 的 ndarray
基于使用最佳参数的估计器,对
X的预测类别对数概率。类别的顺序与拟合属性 classes_ 中的顺序一致。
- predict_proba(X)[source]#
使用找到的最佳参数调用估计器上的 `predict_proba`。
仅当
refit=True且底层估计器支持predict_proba时可用。- 参数:
- X可索引对象,长度为 n_samples
必须满足底层估计器的输入假设。
- 返回:
- y_pred形状为 (n_samples,) 或 (n_samples, n_classes) 的 ndarray
基于使用最佳参数的估计器,对
X的预测类别概率。类别的顺序与拟合属性 classes_ 中的顺序一致。
- score(X, y=None, **params)[source]#
如果估计器已重新拟合,则返回给定数据上的分数。
这会使用
scoring定义的分数(如果已提供),否则使用best_estimator_.score方法。- 参数:
- X形状为 (n_samples, n_features) 的类数组对象
输入数据,其中
n_samples是样本数量,n_features是特征数量。- y形状为 (n_samples, n_output) 或 (n_samples,) 的类数组对象,默认为 None
相对于 X 的分类或回归目标;无监督学习为 None。
- **params字典
要传递给底层评分器(一个或多个)的参数。
1.4 版本新增: 仅当
enable_metadata_routing=True时可用。有关更多详细信息,请参阅元数据路由用户指南。
- 返回:
- score浮点数
如果提供了
scoring,则为scoring定义的分数,否则为best_estimator_.score方法的分数。
- score_samples(X)[source]#
使用找到的最佳参数调用估计器上的 `score_samples`。
仅当
refit=True且底层估计器支持score_samples时可用。0.24 版本新增。
- 参数:
- X可迭代对象
用于预测的数据。必须满足底层估计器的输入要求。
- 返回:
- y_score形状为 (n_samples,) 的 ndarray
The
best_estimator_.score_samples方法。