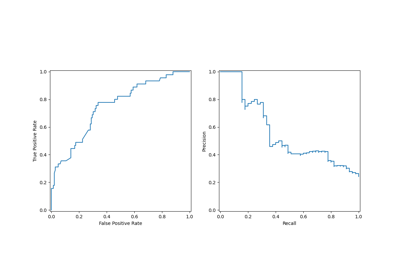
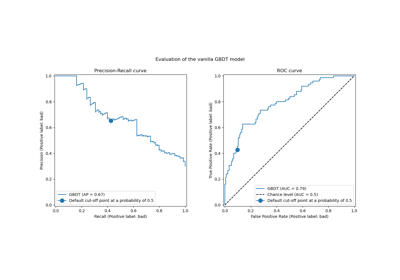
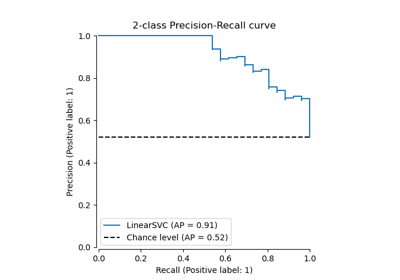
PrecisionRecallDisplay#
- class sklearn.metrics.PrecisionRecallDisplay(precision, recall, *, average_precision=None, estimator_name=None, pos_label=None, prevalence_pos_label=None)[source]#
精确度-召回率可视化。
建议使用
from_estimator或from_predictions来创建PrecisionRecallDisplay。所有参数都作为属性存储。有关
scikit-learn可视化工具的一般信息,请参阅 可视化指南。有关如何解释这些图表的指导,请参阅 模型评估指南。- 参数:
- precisionndarray
精确度值。
- recallndarray
召回率值。
- average_precisionfloat, default=None
平均精确度。如果为 None,则不显示平均精确度。
- estimator_namestr, default=None
估计器名称。如果为 None,则不显示估计器名称。
- pos_labelint, float, bool or str, default=None
被视为正类的类别。如果为 None,则图例中不显示该类别。
在 0.24 版本新增。
- prevalence_pos_labelfloat, default=None
正标签的流行度。它用于绘制偶然水平线。如果为 None,则即使在绘图时
plot_chance_level设置为 True,也不会绘制偶然水平线。在 1.3 版本新增。
- 属性:
- line_matplotlib Artist
精确度-召回率曲线。
- chance_level_matplotlib Artist or None
偶然水平线。如果未绘制偶然水平,则为
None。在 1.3 版本新增。
- ax_matplotlib Axes
带有精确度-召回率曲线的坐标轴。
- figure_matplotlib Figure
包含曲线的图。
另请参阅
precision_recall_curve计算不同概率阈值下的精确度-召回率对。
PrecisionRecallDisplay.from_estimator给定二元分类器绘制精确度-召回率曲线。
PrecisionRecallDisplay.from_predictions使用二元分类器的预测绘制精确度-召回率曲线。
注意
scikit-learn 中的平均精确度(参见
average_precision_score)在计算时没有进行任何插值。为了与该指标保持一致,精确度-召回率曲线也以无插值方式(阶梯状)绘制。您可以通过在
plot、from_estimator或from_predictions中传入关键字参数drawstyle="default"来更改此样式。但是,曲线将不会与报告的平均精确度严格一致。示例
>>> import matplotlib.pyplot as plt >>> from sklearn.datasets import make_classification >>> from sklearn.metrics import (precision_recall_curve, ... PrecisionRecallDisplay) >>> from sklearn.model_selection import train_test_split >>> from sklearn.svm import SVC >>> X, y = make_classification(random_state=0) >>> X_train, X_test, y_train, y_test = train_test_split(X, y, ... random_state=0) >>> clf = SVC(random_state=0) >>> clf.fit(X_train, y_train) SVC(random_state=0) >>> predictions = clf.predict(X_test) >>> precision, recall, _ = precision_recall_curve(y_test, predictions) >>> disp = PrecisionRecallDisplay(precision=precision, recall=recall) >>> disp.plot() <...> >>> plt.show()
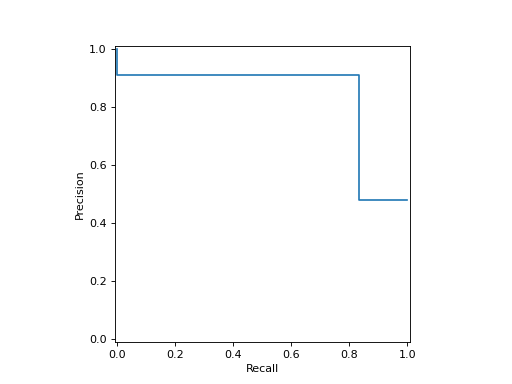
- classmethod from_estimator(estimator, X, y, *, sample_weight=None, drop_intermediate=False, response_method='auto', pos_label=None, name=None, ax=None, plot_chance_level=False, chance_level_kw=None, despine=False, **kwargs)[source]#
给定估计器和一些数据绘制精确度-召回率曲线。
有关
scikit-learn可视化工具的一般信息,请参阅 可视化指南。有关如何解释这些图表的指导,请参阅 模型评估指南。- 参数:
- estimator估计器实例
拟合的分类器或拟合的
Pipeline,其中最后一个估计器是分类器。- X{array-like, sparse matrix} 形状 (n_samples, n_features)
输入值。
- yarray-like 形状 (n_samples,)
目标值。
- sample_weightarray-like 形状 (n_samples,), default=None
样本权重。
- drop_intermediatebool, default=False
是否删除一些次优阈值,这些阈值不会出现在绘制的精确度-召回率曲线上。这有助于创建更轻量的精确度-召回率曲线。
在 1.3 版本新增。
- response_method{‘predict_proba’, ‘decision_function’, ‘auto’}, default=’auto’
指定是使用 predict_proba 还是 decision_function 作为目标响应。如果设置为 'auto',则首先尝试 predict_proba,如果不存在则尝试 decision_function。
- pos_labelint, float, bool or str, default=None
在计算精确度和召回率指标时被视为正类的类别。默认情况下,
estimators.classes_[1]被视为正类。- namestr, default=None
曲线的标签名称。如果为
None,则不使用名称。- axmatplotlib axes, default=None
绘图的坐标轴对象。如果为
None,则创建新的图形和坐标轴。- plot_chance_levelbool, default=False
是否绘制偶然水平。偶然水平是根据在
from_estimator或from_predictions调用期间传入的数据计算出的正标签的流行度。在 1.3 版本新增。
- chance_level_kwdict, default=None
要传递给 matplotlib
plot函数以渲染偶然水平线的关键字参数。在 1.3 版本新增。
- despinebool, default=False
是否移除图表的顶部和右侧边框线。
在 1.6 版本新增。
- **kwargsdict
要传递给 matplotlib
plot函数的关键字参数。
- 返回:
- display
PrecisionRecallDisplay
- display
另请参阅
PrecisionRecallDisplay.from_predictions使用估计概率或决策函数输出绘制精确度-召回率曲线。
注意
scikit-learn 中的平均精确度(参见
average_precision_score)在计算时没有进行任何插值。为了与该指标保持一致,精确度-召回率曲线也以无插值方式(阶梯状)绘制。您可以通过传入关键字参数
drawstyle="default"来更改此样式。但是,曲线将不会与报告的平均精确度严格一致。示例
>>> import matplotlib.pyplot as plt >>> from sklearn.datasets import make_classification >>> from sklearn.metrics import PrecisionRecallDisplay >>> from sklearn.model_selection import train_test_split >>> from sklearn.linear_model import LogisticRegression >>> X, y = make_classification(random_state=0) >>> X_train, X_test, y_train, y_test = train_test_split( ... X, y, random_state=0) >>> clf = LogisticRegression() >>> clf.fit(X_train, y_train) LogisticRegression() >>> PrecisionRecallDisplay.from_estimator( ... clf, X_test, y_test) <...> >>> plt.show()
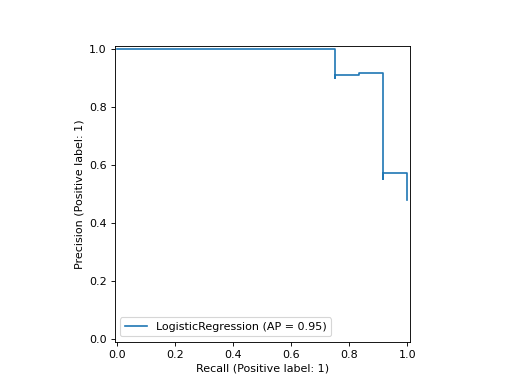
- classmethod from_predictions(y_true, y_pred, *, sample_weight=None, drop_intermediate=False, pos_label=None, name=None, ax=None, plot_chance_level=False, chance_level_kw=None, despine=False, **kwargs)[source]#
给定二元类别预测绘制精确度-召回率曲线。
有关
scikit-learn可视化工具的一般信息,请参阅 可视化指南。有关如何解释这些图表的指导,请参阅 模型评估指南。- 参数:
- y_truearray-like 形状 (n_samples,)
真实二元标签。
- y_predarray-like 形状 (n_samples,)
估计概率或决策函数输出。
- sample_weightarray-like 形状 (n_samples,), default=None
样本权重。
- drop_intermediatebool, default=False
是否删除一些次优阈值,这些阈值不会出现在绘制的精确度-召回率曲线上。这有助于创建更轻量的精确度-召回率曲线。
在 1.3 版本新增。
- pos_labelint, float, bool or str, default=None
在计算精确度和召回率指标时被视为正类的类别。
- namestr, default=None
曲线的标签名称。如果为
None,名称将设置为"Classifier"。- axmatplotlib axes, default=None
绘图的坐标轴对象。如果为
None,则创建新的图形和坐标轴。- plot_chance_levelbool, default=False
是否绘制偶然水平。偶然水平是根据在
from_estimator或from_predictions调用期间传入的数据计算出的正标签的流行度。在 1.3 版本新增。
- chance_level_kwdict, default=None
要传递给 matplotlib
plot函数以渲染偶然水平线的关键字参数。在 1.3 版本新增。
- despinebool, default=False
是否移除图表的顶部和右侧边框线。
在 1.6 版本新增。
- **kwargsdict
要传递给 matplotlib
plot函数的关键字参数。
- 返回:
- display
PrecisionRecallDisplay
- display
另请参阅
PrecisionRecallDisplay.from_estimator使用估计器绘制精确度-召回率曲线。
注意
scikit-learn 中的平均精确度(参见
average_precision_score)在计算时没有进行任何插值。为了与该指标保持一致,精确度-召回率曲线也以无插值方式(阶梯状)绘制。您可以通过传入关键字参数
drawstyle="default"来更改此样式。但是,曲线将不会与报告的平均精确度严格一致。示例
>>> import matplotlib.pyplot as plt >>> from sklearn.datasets import make_classification >>> from sklearn.metrics import PrecisionRecallDisplay >>> from sklearn.model_selection import train_test_split >>> from sklearn.linear_model import LogisticRegression >>> X, y = make_classification(random_state=0) >>> X_train, X_test, y_train, y_test = train_test_split( ... X, y, random_state=0) >>> clf = LogisticRegression() >>> clf.fit(X_train, y_train) LogisticRegression() >>> y_pred = clf.predict_proba(X_test)[:, 1] >>> PrecisionRecallDisplay.from_predictions( ... y_test, y_pred) <...> >>> plt.show()
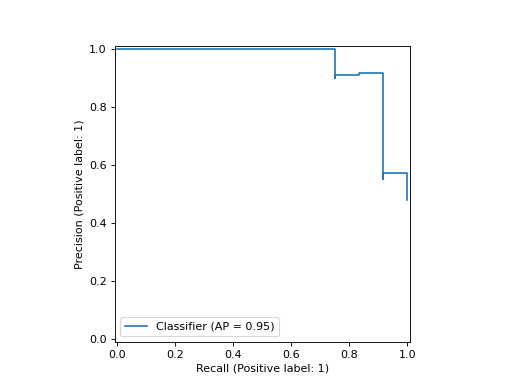
- plot(ax=None, *, name=None, plot_chance_level=False, chance_level_kw=None, despine=False, **kwargs)[source]#
绘制可视化图。
额外的关键字参数将传递给 matplotlib 的
plot函数。- 参数:
- axMatplotlib Axes, default=None
绘图的坐标轴对象。如果为
None,则创建新的图形和坐标轴。- namestr, default=None
精确度-召回率曲线的标签名称。如果为
None,则在estimator_name不为None时使用estimator_name,否则不显示标签。- plot_chance_levelbool, default=False
是否绘制偶然水平。偶然水平是根据在
from_estimator或from_predictions调用期间传入的数据计算出的正标签的流行度。在 1.3 版本新增。
- chance_level_kwdict, default=None
要传递给 matplotlib
plot函数以渲染偶然水平线的关键字参数。在 1.3 版本新增。
- despinebool, default=False
是否移除图表的顶部和右侧边框线。
在 1.6 版本新增。
- **kwargsdict
要传递给 matplotlib
plot函数的关键字参数。
- 返回:
- display
PrecisionRecallDisplay 存储计算值的对象。
- display
注意
scikit-learn 中的平均精确度(参见
average_precision_score)在计算时没有进行任何插值。为了与该指标保持一致,精确度-召回率曲线也以无插值方式(阶梯状)绘制。您可以通过传入关键字参数
drawstyle="default"来更改此样式。但是,曲线将不会与报告的平均精确度严格一致。