迭代式插补器#
- 类 sklearn.impute.IterativeImputer(estimator=None, *, missing_values=nan, sample_posterior=False, max_iter=10, tol=0.001, n_nearest_features=None, initial_strategy='mean', fill_value=None, imputation_order='ascending', skip_complete=False, min_value=-inf, max_value=inf, verbose=0, random_state=None, add_indicator=False, keep_empty_features=False)[source]#
一种多元插补器,用于从所有其他特征估计每个特征。
一种通过将每个具有缺失值的特征建模为其他特征的函数,以循环方式(round-robin fashion)插补缺失值的策略。
在用户指南中阅读更多。
在 0.21 版本中添加。
注意
此估计器目前仍处于**实验阶段**:其预测结果和API可能在没有任何弃用周期的情况下发生变化。要使用它,您需要显式导入
enable_iterative_imputer>>> # explicitly require this experimental feature >>> from sklearn.experimental import enable_iterative_imputer # noqa >>> # now you can import normally from sklearn.impute >>> from sklearn.impute import IterativeImputer
- 参数:
- estimator估计器对象,默认值=BayesianRidge()
在循环插补的每个步骤中使用的估计器。如果
sample_posterior=True,则估计器必须在其predict方法中支持return_std。- missing_valuesint 或 np.nan,默认值=np.nan
缺失值的占位符。所有
missing_values的出现都将被插补。对于带有可空整数数据类型和缺失值的 pandas 数据帧,missing_values应设置为np.nan,因为pd.NA将被转换为np.nan。- sample_posteriorbool,默认值=False
是否从拟合估计器的(高斯)预测后验中采样进行每次插补。如果设置为
True,估计器必须在其predict方法中支持return_std。如果将IterativeImputer用于多次插补,则设置为True。- max_iterint,默认值=10
在返回最后一轮计算的插补结果之前,执行的最大插补轮数。一轮是指对每个具有缺失值的特征进行一次插补。当
max(abs(X_t - X_{t-1}))/max(abs(X[known_vals])) < tol时,达到停止准则,其中X_t是第t次迭代时的X。请注意,只有当sample_posterior=False时才应用早期停止。- tolfloat,默认值=1e-3
停止条件的容差。
- n_nearest_featuresint,默认值=None
用于估计每个特征列缺失值的其他特征的数量。特征之间的接近度通过每个特征对之间的绝对相关系数(在初始插补之后)来衡量。为了确保在整个插补过程中特征的覆盖,邻近特征不一定是最近的,而是以与每个插补目标特征的相关性成比例的概率抽取的。当特征数量巨大时,可以显著提高速度。如果为
None,将使用所有特征。- initial_strategy{‘mean’, ‘median’, ‘most_frequent’, ‘constant’},默认值=’mean’
用于初始化缺失值的策略。与
SimpleImputer中的strategy参数相同。- fill_valuestr 或数值,默认值=None
当
strategy="constant"时,fill_value用于替换所有缺失值的出现。对于字符串或对象数据类型,fill_value必须是字符串。如果为None,则在插补数值数据时fill_value将为 0,对于字符串或对象数据类型,则为“missing_value”。在 1.3 版本中添加。
- imputation_order{‘ascending’, ‘descending’, ‘roman’, ‘arabic’, ‘random’},默认值=’ascending’
特征将被插补的顺序。可能的值有
'ascending': 从缺失值最少的特征到最多的特征。'descending': 从缺失值最多的特征到最少的特征。'roman': 从左到右。'arabic': 从右到左。'random': 每轮使用随机顺序。
- skip_completebool,默认值=False
如果为
True,则在transform期间具有缺失值但在fit期间没有任何缺失值的特征将仅使用初始插补方法进行插补。如果您在fit和transform时都有许多无缺失值的特征,设置为True可以节省计算量。- min_valuefloat 或 形状为 (n_features,) 的类数组,默认值=-np.inf
最小可能的插补值。如果是标量,则广播到形状
(n_features,)。如果是类数组,则期望形状为(n_features,),每个特征一个最小值。默认值为-np.inf。在 0.23 版本中更改: 添加了对类数组的支持。
- max_valuefloat 或 形状为 (n_features,) 的类数组,默认值=np.inf
最大可能的插补值。如果是标量,则广播到形状
(n_features,)。如果是类数组,则期望形状为(n_features,),每个特征一个最大值。默认值为np.inf。在 0.23 版本中更改: 添加了对类数组的支持。
- verboseint,默认值=0
详细程度标志,控制函数评估时发出的调试消息。值越高,越详细。可以是 0、1 或 2。
- random_stateint, RandomState 实例或 None,默认值=None
要使用的伪随机数生成器的种子。如果
n_nearest_features不为None,则随机化估计器特征的选择;如果imputation_order为random,则随机化插补顺序;如果sample_posterior=True,则从后验中随机采样。使用整数以确保确定性。请参阅术语表。- add_indicatorbool,默认值=False
如果为
True,则MissingIndicator变换将堆叠到插补器的变换输出上。这使得预测估计器即使在插补后也能考虑缺失值。如果一个特征在 fit/train 期间没有缺失值,那么即使在 transform/test 期间有缺失值,该特征也不会出现在缺失指示器上。- keep_empty_featuresbool,默认值=False
如果为 True,则当调用
transform时,在调用fit时完全由缺失值组成的特征将在结果中返回。插补值始终为0,除非initial_strategy="constant",在这种情况下将使用fill_value。在 1.2 版本中添加。
- 属性:
- initial_imputer_
SimpleImputer类型的对象 用于初始化缺失值的插补器。
- imputation_sequence_元组列表
每个元组包含
(feat_idx, neighbor_feat_idx, estimator),其中feat_idx是当前要插补的特征,neighbor_feat_idx是用于插补当前特征的其他特征的数组,estimator是用于插补的已训练估计器。长度为self.n_features_with_missing_ * self.n_iter_。- n_iter_int
已发生的迭代轮数。如果达到早期停止准则,将小于
self.max_iter。- n_features_in_int
在 fit 期间见到的特征数量。
在 0.24 版本中添加。
- feature_names_in_形状为 (
n_features_in_,) 的 ndarray 在 fit 期间见到的特征名称。仅当
X的所有特征名称都是字符串时才定义。在 1.0 版本中添加。
- n_features_with_missing_int
具有缺失值的特征数量。
- indicator_
MissingIndicator 用于添加缺失值的二进制指示器的指示器。如果
add_indicator=False,则为None。- random_state_RandomState 实例
从种子、随机数生成器或
np.random生成的 RandomState 实例。
- initial_imputer_
另请参阅
SimpleImputer用于使用简单策略补全缺失值的单变量插补器。
KNNImputer使用最近样本估计缺失特征的多元插补器。
备注
为了支持归纳模式下的插补,我们在
fit阶段存储每个特征的估计器,并在transform阶段按顺序进行预测而无需重新拟合。在
fit时包含所有缺失值的特征将在transform时被丢弃。在默认设置下,插补器的复杂度为 \(\mathcal{O}(knp^3\min(n,p))\),其中 \(k\) =
max_iter,\(n\) 为样本数量,\(p\) 为特征数量。因此,当特征数量增加时,其计算成本会变得高得令人望而却步。设置n_nearest_features << n_features,skip_complete=True或增加tol有助于降低其计算成本。根据缺失值的性质,在预测情境中,简单的插补器可能更受欢迎。
参考文献
示例
>>> import numpy as np >>> from sklearn.experimental import enable_iterative_imputer >>> from sklearn.impute import IterativeImputer >>> imp_mean = IterativeImputer(random_state=0) >>> imp_mean.fit([[7, 2, 3], [4, np.nan, 6], [10, 5, 9]]) IterativeImputer(random_state=0) >>> X = [[np.nan, 2, 3], [4, np.nan, 6], [10, np.nan, 9]] >>> imp_mean.transform(X) array([[ 6.9584, 2. , 3. ], [ 4. , 2.6000, 6. ], [10. , 4.9999, 9. ]])
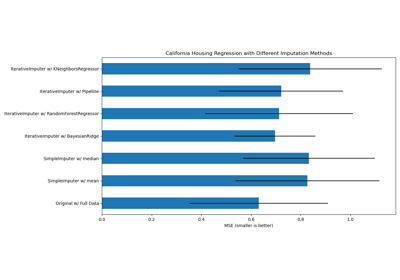
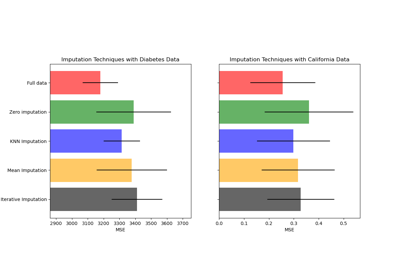
有关更详细的示例,请参阅在构建估计器之前插补缺失值或使用迭代式插补器变体插补缺失值。
- fit(X, y=None, **fit_params)[source]#
在
X上拟合插补器并返回自身。- 参数:
- X类数组,形状为 (n_samples, n_features)
输入数据,其中
n_samples是样本数量,n_features是特征数量。- y忽略
未使用,按惯例为保持 API 一致性而存在。
- **fit_paramsdict
通过元数据路由 API 传递给子估计器
fit方法的参数。在 1.5 版本中添加: 仅当设置了
sklearn.set_config(enable_metadata_routing=True)时可用。有关详细信息,请参阅元数据路由用户指南。
- 返回:
- self对象
已拟合的估计器。
- fit_transform(X, y=None, **params)[source]#
在
X上拟合插补器并返回转换后的X。- 参数:
- X类数组,形状为 (n_samples, n_features)
输入数据,其中
n_samples是样本数量,n_features是特征数量。- y忽略
未使用,按惯例为保持 API 一致性而存在。
- **paramsdict
通过元数据路由 API 传递给子估计器
fit方法的参数。在 1.5 版本中添加: 仅当设置了
sklearn.set_config(enable_metadata_routing=True)时可用。有关详细信息,请参阅元数据路由用户指南。
- 返回:
- Xt类数组,形状为 (n_samples, n_features)
插补后的输入数据。
- get_feature_names_out(input_features=None)[source]#
获取变换后的输出特征名称。
- 参数:
- input_featuresstr 类型或 None 的类数组,默认值=None
输入特征。
如果
input_features为None,则使用feature_names_in_作为输入特征名称。如果未定义feature_names_in_,则生成以下输入特征名称:["x0", "x1", ..., "x(n_features_in_ - 1)"]。如果
input_features是类数组,则如果定义了feature_names_in_,input_features必须与feature_names_in_匹配。
- 返回:
- feature_names_outstr 对象的 ndarray
转换后的特征名称。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查看用户指南以了解路由机制的工作原理。
在 1.5 版本中添加。
- 返回:
- routingMetadataRouter
一个封装路由信息的
MetadataRouter。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool,默认值=True
如果为 True,将返回此估计器及其包含的作为估计器的子对象的参数。
- 返回:
- paramsdict
参数名称与其值之间的映射。
- set_output(*, transform=None)[source]#
设置输出容器。
有关如何使用 API 的示例,请参阅介绍 set_output API。
- 参数:
- transform{“default”, “pandas”, “polars”},默认值=None
配置
transform和fit_transform的输出。"default": 变换器的默认输出格式"pandas": DataFrame 输出"polars": Polars 输出None: 变换配置不变
在 1.4 版本中添加: 添加了
"polars"选项。
- 返回:
- self估计器实例
估计器实例。