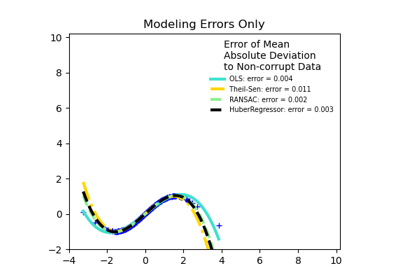
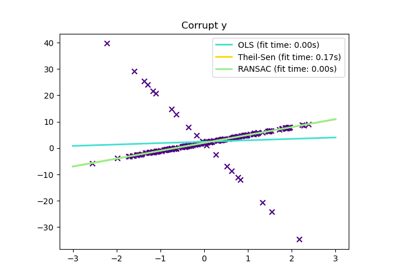
TheilSenRegressor#
- class sklearn.linear_model.TheilSenRegressor(*, fit_intercept=True, copy_X='deprecated', max_subpopulation=10000.0, n_subsamples=None, max_iter=300, tol=0.001, random_state=None, n_jobs=None, verbose=False)[source]#
Theil-Sen 估计器:鲁棒多元回归模型。
该算法在 X 中大小为 n_subsamples 的样本子集上计算最小二乘解。n_subsamples 在特征数量和样本数量之间的任何值都会导致估计器在鲁棒性和效率之间取得折衷。由于最小二乘解的数量是“n_samples 选 n_subsamples”,它可能非常大,因此可以通过 max_subpopulation 限制。如果达到此限制,子集将随机选择。在最后一步,计算所有最小二乘解的空间中位数(或 L1 中位数)。
在用户指南中阅读更多。
- 参数:
- fit_interceptbool, default=True
是否为该模型计算截距。如果设置为 false,则计算中不使用截距。
- copy_Xbool, default=True
如果为 True,X 将被复制;否则,它可能会被覆盖。
自 1.6 版本弃用:
copy_X在 1.6 中已弃用,并将在 1.8 中移除。由于始终会进行复制,因此它没有效果。- max_subpopulationint, default=1e4
如果“n 选 k”(其中 n 是样本数量,k 是子样本数量(至少是特征数量))大于 max_subpopulation,则考虑给定最大大小的随机子总体,而不是使用基数为“n 选 k”的集合进行计算。对于非小型问题,如果 n_subsamples 未更改,此参数将决定内存使用和运行时间。请注意,数据类型应为 int,但也可以接受 1e4 等浮点数。
- n_subsamplesint, default=None
用于计算参数的样本数量。这至少是特征数量(如果 fit_intercept=True 则加 1),最大为样本数量。较低的数字导致较高的击穿点和较低的效率,而较高的数字导致较低的击穿点和较高的效率。如果为 None,则取导致最大鲁棒性的最小子样本数量。如果 n_subsamples 设置为 n_samples,则 Theil-Sen 与最小二乘法相同。
- max_iterint, default=300
空间中位数计算的最大迭代次数。
- tolfloat, default=1e-3
计算空间中位数时的容差。
- random_stateint, RandomState 实例或 None, default=None
一个随机数生成器实例,用于定义随机排列生成器的状态。传入一个 int 以在多个函数调用中获得可重现的输出。请参阅术语表。
- n_jobsint, default=None
交叉验证期间使用的 CPU 数量。
None表示 1,除非在joblib.parallel_backend上下文中。-1表示使用所有处理器。有关更多详细信息,请参阅术语表。- verbosebool, default=False
拟合模型时的详细模式。
- 属性:
- coef_形状为 (n_features,) 的 ndarray
回归模型的系数(分布的中位数)。
- intercept_float
回归模型的估计截距。
- breakdown_float
近似击穿点。
- n_iter_int
空间中位数所需的迭代次数。
- n_subpopulation_int
从“n 选 k”中考虑的组合数量,其中 n 是样本数量,k 是子样本数量。
- n_features_in_int
拟合期间看到的特征数量。
在 0.24 版本中新增。
- feature_names_in_形状为 (
n_features_in_,) 的 ndarray 拟合期间看到的特征名称。仅当
X的所有特征名称均为字符串时才定义。在 1.0 版本中新增。
另请参阅
HuberRegressor对异常值鲁棒的线性回归模型。
RANSACRegressorRANSAC(RANdom SAmple Consensus)算法。
SGDRegressor通过最小化带有 SGD 的正则化经验损失来拟合。
参考文献
多元线性回归模型中的 Theil-Sen 估计器,2009 Xin Dang, Hanxiang Peng, Xueqin Wang and Heping Zhang http://home.olemiss.edu/~xdang/papers/MTSE.pdf
示例
>>> from sklearn.linear_model import TheilSenRegressor >>> from sklearn.datasets import make_regression >>> X, y = make_regression( ... n_samples=200, n_features=2, noise=4.0, random_state=0) >>> reg = TheilSenRegressor(random_state=0).fit(X, y) >>> reg.score(X, y) 0.9884 >>> reg.predict(X[:1,]) array([-31.5871])
- fit(X, y)[source]#
拟合线性模型。
- 参数:
- X形状为 (n_samples, n_features) 的 ndarray
训练数据。
- y形状为 (n_samples,) 的 ndarray
目标值。
- 返回:
- self返回 self 的实例。
拟合的
TheilSenRegressor估计器。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查看用户指南,了解路由机制如何工作。
- 返回:
- routingMetadataRequest
一个包含路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,将返回此估计器及其包含的子对象(如果它们也是估计器)的参数。
- 返回:
- paramsdict
参数名称映射到其值。
- predict(X)[source]#
使用线性模型进行预测。
- 参数:
- X类数组或稀疏矩阵,形状为 (n_samples, n_features)
样本。
- 返回:
- C数组,形状为 (n_samples,)
返回预测值。
- score(X, y, sample_weight=None)[source]#
返回测试数据上的决定系数。
决定系数 \(R^2\) 定义为 \((1 - \frac{u}{v})\),其中 \(u\) 是残差平方和
((y_true - y_pred)** 2).sum(),\(v\) 是总平方和((y_true - y_true.mean()) ** 2).sum()。最佳可能分数为 1.0,它也可以为负(因为模型可能任意地差)。一个始终预测y期望值而不考虑输入特征的常数模型将获得 0.0 的 \(R^2\) 分数。- 参数:
- X形状为 (n_samples, n_features) 的类数组
测试样本。对于某些估计器,这可能是一个预计算的核矩阵或一个通用对象列表,形状为
(n_samples, n_samples_fitted),其中n_samples_fitted是估计器拟合中使用的样本数量。- y形状为 (n_samples,) 或 (n_samples, n_outputs) 的类数组
X的真实值。- sample_weight形状为 (n_samples,) 的类数组, default=None
样本权重。
- 返回:
- scorefloat
self.predict(X)相对于y的 \(R^2\)。
注意事项
在调用回归器上的
score时使用的 \(R^2\) 分数从 0.23 版本开始使用multioutput='uniform_average',以与r2_score的默认值保持一致。这会影响所有多输出回归器(除了MultiOutputRegressor)的score方法。
- set_params(**params)[source]#
设置此估计器的参数。
此方法适用于简单的估计器以及嵌套对象(例如
Pipeline)。后者具有<component>__<parameter>形式的参数,以便可以更新嵌套对象的每个组件。- 参数:
- **paramsdict
估计器参数。
- 返回:
- self估计器实例
估计器实例。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') TheilSenRegressor[source]#
请求传递给
score方法的元数据。请注意,此方法仅在
enable_metadata_routing=True时相关(请参阅sklearn.set_config)。请参阅用户指南,了解路由机制如何工作。每个参数的选项是
True: 请求元数据,如果提供则传递给score。如果未提供元数据,则请求被忽略。False: 不请求元数据,并且元估计器不会将其传递给score。None: 不请求元数据,如果用户提供,元估计器将引发错误。str: 元数据应以给定的别名而不是原始名称传递给元估计器。
默认值(
sklearn.utils.metadata_routing.UNCHANGED)保留现有请求。这允许您更改某些参数的请求而不更改其他参数。在 1.3 版本中新增。
注意
此方法仅当此估计器用作元估计器的子估计器时才相关,例如在
Pipeline内部使用时。否则它没有效果。- 参数:
- sample_weightstr, True, False, 或 None, default=sklearn.utils.metadata_routing.UNCHANGED
score方法中sample_weight参数的元数据路由。
- 返回:
- self对象
更新后的对象。