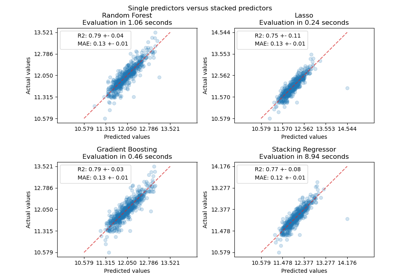
StackingRegressor#
- class sklearn.ensemble.StackingRegressor(estimators, final_estimator=None, *, cv=None, n_jobs=None, passthrough=False, verbose=0)[source]#
带有最终回归器的估计器堆栈。
堆叠泛化(Stacked generalization)在于堆叠各个估计器的输出,并使用一个回归器来计算最终预测。堆叠允许通过将每个独立估计器的输出作为最终估计器的输入来利用其优势。
请注意,
estimators_在完整的X上拟合,而final_estimator_则使用基估计器的交叉验证预测(通过cross_val_predict)进行训练。在用户指南中了解更多信息。
0.22 版本新增。
- 参数:
- estimators列表,包含 (str, estimator)
将要堆叠在一起的基估计器。列表的每个元素定义为一个字符串(即名称)和估计器实例的元组。可以使用
set_params将估计器设置为“drop”。- final_estimator估计器,默认为 None
用于组合基估计器的回归器。默认回归器是
RidgeCV。- cv整数,交叉验证生成器,可迭代对象,或“prefit”,默认为 None
确定在
cross_val_predict中用于训练final_estimator的交叉验证分割策略。cv 的可能输入包括:None,使用默认的 5 折交叉验证,
整数,指定(分层)KFold 中的折数,
用作交叉验证生成器的对象,
一个产生训练、测试分割的可迭代对象,
"prefit",假定estimators已经预拟合。在这种情况下,估计器将不会被重新拟合。
对于整数/None 输入,如果估计器是分类器且 y 是二元或多类,则使用
StratifiedKFold。在所有其他情况下,使用KFold。这些分割器以shuffle=False实例化,因此分割在不同调用之间将保持一致。有关此处可用的各种交叉验证策略,请参阅用户指南。
如果传入“prefit”,则假定所有
estimators均已拟合。final_estimator_在完整训练集上根据estimators的预测进行训练,且**不**是交叉验证的预测。请注意,如果模型在训练堆叠模型时使用了相同的数据进行训练,则存在很高的过拟合风险。1.1 版本新增:‘prefit’ 选项在 1.1 版本中添加。
注意
如果训练样本数量足够大,则更多的分割次数不会带来任何好处。实际上,训练时间会增加。
cv不用于模型评估,而用于预测。- n_jobs整数,默认为 None
所有
estimators进行fit时并行运行的作业数。None表示 1,除非在joblib.parallel_backend上下文中。-1 表示使用所有处理器。有关更多详细信息,请参阅术语表。- passthrough布尔值,默认为 False
当为 False 时,只有估计器的预测将用作
final_estimator的训练数据。当为 True 时,final_estimator将在预测以及原始训练数据上进行训练。- verbose整数,默认为 0
详细程度。
- 属性:
- estimators_估计器列表
estimators参数的元素,已在训练数据上拟合。如果一个估计器被设置为'drop',它将不会出现在estimators_中。当cv="prefit"时,estimators_被设置为estimators且不再重新拟合。- named_estimators_
Bunch 通过名称访问任何已拟合的子估计器的属性。
n_features_in_整数在拟合期间看到的特征数量。
- feature_names_in_形状为 (
n_features_in_,) 的 ndarray 在拟合期间看到的特征名称。仅当底层估计器在拟合时公开此属性时才定义。
1.0 版本新增。
- final_estimator_估计器
在
estimators_的输出上拟合的回归器,负责最终预测。- stack_method_字符串列表
每个基估计器使用的方法。
另请参阅
StackingClassifier带有最终分类器的估计器堆栈。
参考文献
[1]Wolpert, David H. “Stacked generalization.” Neural networks 5.2 (1992): 241-259.
示例
>>> from sklearn.datasets import load_diabetes >>> from sklearn.linear_model import RidgeCV >>> from sklearn.svm import LinearSVR >>> from sklearn.ensemble import RandomForestRegressor >>> from sklearn.ensemble import StackingRegressor >>> X, y = load_diabetes(return_X_y=True) >>> estimators = [ ... ('lr', RidgeCV()), ... ('svr', LinearSVR(random_state=42)) ... ] >>> reg = StackingRegressor( ... estimators=estimators, ... final_estimator=RandomForestRegressor(n_estimators=10, ... random_state=42) ... ) >>> from sklearn.model_selection import train_test_split >>> X_train, X_test, y_train, y_test = train_test_split( ... X, y, random_state=42 ... ) >>> reg.fit(X_train, y_train).score(X_test, y_test) 0.3...
- fit(X, y, **fit_params)[source]#
拟合估计器。
- 参数:
- X形状为 (n_samples, n_features) 的 {类数组,稀疏矩阵}
训练向量,其中
n_samples是样本数量,n_features是特征数量。- y形状为 (n_samples,) 的类数组
目标值。
- **fit_params字典
要传递给底层估计器的参数。
1.6 版本新增:仅当
enable_metadata_routing=True时可用,可通过使用sklearn.set_config(enable_metadata_routing=True)进行设置。有关更多详细信息,请参阅元数据路由用户指南。
- 返回:
- self对象
返回一个已拟合的实例。
- fit_transform(X, y, **fit_params)[source]#
拟合估计器并返回每个估计器对 X 的预测。
- 参数:
- X形状为 (n_samples, n_features) 的 {类数组,稀疏矩阵}
训练向量,其中
n_samples是样本数量,n_features是特征数量。- y形状为 (n_samples,) 的类数组
目标值。
- **fit_params字典
要传递给底层估计器的参数。
1.6 版本新增:仅当
enable_metadata_routing=True时可用,可通过使用sklearn.set_config(enable_metadata_routing=True)进行设置。有关更多详细信息,请参阅元数据路由用户指南。
- 返回:
- y_preds形状为 (n_samples, n_estimators) 的 ndarray
每个估计器的预测输出。
- get_feature_names_out(input_features=None)[source]#
获取转换后的输出特征名称。
- 参数:
- input_features字符串或 None 的类数组,默认为 None
输入特征。输入特征名称仅在
passthrough为True时使用。如果
input_features为None,则使用feature_names_in_作为输入特征名称。如果feature_names_in_未定义,则生成名称:[x0, x1, ..., x(n_features_in_ - 1)]。如果
input_features是类数组,则如果feature_names_in_已定义,则input_features必须与feature_names_in_匹配。
如果
passthrough为False,则仅使用estimators的名称来生成输出特征名称。
- 返回:
- feature_names_out字符串对象的 ndarray
转换后的特征名称。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查看用户指南以了解路由机制的工作原理。
1.6 版本新增。
- 返回:
- routingMetadataRouter
一个封装路由信息的
MetadataRouter。
- get_params(deep=True)[source]#
获取集成中估计器的参数。
返回构造函数中给定的参数以及
estimators参数中包含的估计器。- 参数:
- deep布尔值,默认为 True
设置为 True 将获取各种估计器及其参数。
- 返回:
- params字典
参数和估计器名称与其值映射,或参数名称与其值映射。
- predict(X, **predict_params)[source]#
预测 X 的目标。
- 参数:
- X形状为 (n_samples, n_features) 的 {类数组,稀疏矩阵}
训练向量,其中
n_samples是样本数量,n_features是特征数量。- **predict_params字典,键为字符串,值为对象
传递给
final_estimator调用的predict方法的参数。请注意,这可能用于通过return_std或return_cov从某些估计器返回不确定性。请注意,它只计算最终估计器中的不确定性。如果
enable_metadata_routing=False(默认):参数直接传递给final_estimator的predict方法。如果
enable_metadata_routing=True:参数安全地路由到final_estimator的predict方法。有关更多详细信息,请参阅元数据路由用户指南。
1.6 版本更改:
**predict_params可以通过元数据路由 API 进行路由。
- 返回:
- y_pred形状为 (n_samples,) 或 (n_samples, n_output) 的 ndarray
预测目标。
- score(X, y, sample_weight=None)[source]#
返回测试数据上的决定系数。
决定系数 \(R^2\) 定义为 \((1 - \frac{u}{v})\),其中 \(u\) 是残差平方和
((y_true - y_pred)** 2).sum(),\(v\) 是总平方和((y_true - y_true.mean()) ** 2).sum()。最佳得分是 1.0,也可能是负值(因为模型可能任意地差)。一个始终预测y的期望值而忽略输入特征的常数模型,将获得 0.0 的 \(R^2\) 分数。- 参数:
- X形状为 (n_samples, n_features) 的类数组
测试样本。对于某些估计器,这可能是预计算的核矩阵,或者是一个通用对象的列表,形状为
(n_samples, n_samples_fitted),其中n_samples_fitted是估计器拟合中使用的样本数量。- y形状为 (n_samples,) 或 (n_samples, n_outputs) 的类数组
X的真实值。- sample_weight形状为 (n_samples,) 的类数组,默认为 None
样本权重。
- 返回:
- score浮点数
相对于
y的self.predict(X)的 \(R^2\) 分数。
注意事项
在回归器上调用
score时使用的 \(R^2\) 分数从 0.23 版本开始使用multioutput='uniform_average',以与r2_score的默认值保持一致。这影响了所有多输出回归器(除了MultiOutputRegressor)的score方法。
- set_output(*, transform=None)[source]#
设置输出容器。
有关如何使用此 API 的示例,请参阅set_output API 介绍。
- 参数:
- transform{“default”, “pandas”, “polars”},默认为 None
配置
transform和fit_transform的输出。"default":转换器的默认输出格式"pandas":DataFrame 输出"polars":Polars 输出None:转换配置不变
1.4 版本新增:添加了
"polars"选项。
- 返回:
- self估计器实例
估计器实例。
- set_params(**params)[source]#
设置集成中估计器的参数。
有效的参数键可以通过
get_params()列出。请注意,您可以直接设置estimators中包含的估计器的参数。- 参数:
- **params关键字参数
使用例如
set_params(parameter_name=new_value)设置特定参数。此外,除了设置估计器的参数外,也可以设置估计器中的单个估计器,或者通过将其设置为“drop”来移除它们。
- 返回:
- self对象
估计器实例。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') StackingRegressor[source]#
请求传递给
score方法的元数据。请注意,此方法仅在
enable_metadata_routing=True时相关(参见sklearn.set_config)。请参阅用户指南以了解路由机制的工作原理。每个参数的选项是:
True:请求元数据,如果提供则传递给score。如果未提供元数据,则忽略该请求。False:不请求元数据,元估计器不会将其传递给score。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:元数据应以给定的别名而不是原始名称传递给元估计器。
默认值 (
sklearn.utils.metadata_routing.UNCHANGED) 保留现有请求。这允许您更改某些参数的请求而不更改其他参数。1.3 版本新增。
注意
此方法仅当此估计器用作元估计器的子估计器时才相关,例如在
Pipeline内部使用。否则,它没有效果。- 参数:
- sample_weight字符串,True,False 或 None,默认为 sklearn.utils.metadata_routing.UNCHANGED
在
score中sample_weight参数的元数据路由。
- 返回:
- self对象
更新后的对象。