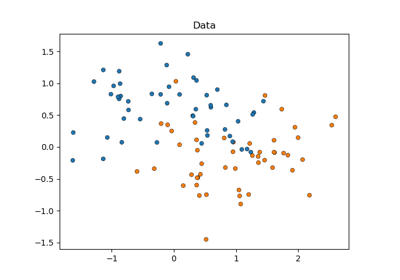
make_moons#
- sklearn.datasets.make_moons(n_samples=100, *, shuffle=True, noise=None, random_state=None)[source]#
生成两个交错的半圆形。
一个简单的玩具数据集,用于可视化聚类和分类算法。在用户指南中阅读更多信息。
- 参数:
- n_samplesint 或 shape 为 (2,) 的元组, dtype=int, 默认为 100
如果为整数,则为生成的总点数。如果为包含两个元素的元组,则为两个半圆中每个半圆的点数。
版本 0.23 中的更改:增加了包含两个元素的元组。
- shufflebool, 默认为 True
是否混洗样本。
- noisefloat, 默认为 None
添加到数据的 Gaussian 噪声的标准差。
- random_stateint, RandomState 实例或 None, 默认为 None
确定数据集混洗和噪声的随机数生成。传入一个整数可在多次函数调用中获得可复现的输出。请参见术语表。
- 返回值:
- Xshape 为 (n_samples, 2) 的 ndarray
生成的样本。
- yshape 为 (n_samples,) 的 ndarray
每个样本的类别成员资格的整数标签(0 或 1)。
示例
>>> from sklearn.datasets import make_moons >>> X, y = make_moons(n_samples=200, noise=0.2, random_state=42) >>> X.shape (200, 2) >>> y.shape (200,)