GraphicalLassoCV#
- 类 sklearn.covariance.GraphicalLassoCV(*, alphas=4, n_refinements=4, cv=None, tol=0.0001, enet_tol=0.0001, max_iter=100, mode='cd', n_jobs=None, verbose=False, eps=np.float64(2.220446049250313e-16), assume_centered=False)[source]#
带有交叉验证的L1惩罚项选择的稀疏逆协方差。
请参见术语表中的交叉验证估计器条目。
更多信息请阅读用户指南。
v0.20 版本中的变化: GraphLassoCV 已更名为 GraphicalLassoCV
- 参数:
- alphasint 或 形状为 (n_alphas,) 的类数组,dtype=float,默认值=4
如果给定一个整数,它将固定要使用的 alpha 网格上的点数。如果给定一个列表,它将提供要使用的网格。更多详细信息请参见类文档字符串中的说明。整数的范围是 [1, 无穷大)。浮点数类数组的范围是 (0, 无穷大]。
- n_refinementsint,默认值=4
网格被细化的次数。如果传递了显式的 alphas 值,则不使用此参数。范围是 [1, 无穷大)。
- cvint, 交叉验证生成器 或 可迭代对象,默认值=None
确定交叉验证的拆分策略。cv 的可能输入为
None,使用默认的 5 折交叉验证,
整数,指定折叠次数。
一个可迭代对象,产生 (训练集, 测试集) 拆分作为索引数组。
对于整数/None 输入,将使用
KFold。有关可在此处使用的各种交叉验证策略,请参阅用户指南。
0.20 版本中的变化:
cv在为 None 时的默认值从 3 折变为 5 折。- tolfloat,默认值=1e-4
声明收敛的容差:如果对偶间隙低于此值,则停止迭代。范围是 (0, 无穷大]。
- enet_tolfloat,默认值=1e-4
用于计算下降方向的弹性网络求解器的容差。此参数控制给定列更新的搜索方向的准确性,而非整体参数估计的准确性。仅用于 mode='cd'。范围是 (0, 无穷大]。
- max_iterint,默认值=100
最大迭代次数。
- mode{‘cd’, ‘lars’},默认值=’cd’
要使用的 Lasso 求解器:坐标下降或 LARS。对于非常稀疏的底层图,其中特征数量大于样本数量,请使用 LARS。其他情况首选 cd,它在数值上更稳定。
- n_jobsint,默认值=None
并行运行的作业数。
None表示 1,除非在joblib.parallel_backend上下文中。-1表示使用所有处理器。更多详细信息请参见术语表。v0.20 版本中的变化:
n_jobs的默认值从 1 更改为 None- verbosebool,默认值=False
如果 verbose 为 True,则在每次迭代时打印目标函数和对偶间隙。
- epsfloat,默认值=eps
Cholesky 对角因子计算中的机器精度正则化。对于病态系统,请增加此值。默认值为
np.finfo(np.float64).eps。在 1.3 版本中新增。
- assume_centeredbool,默认值=False
如果为 True,则在计算前不进行数据中心化。当处理均值接近但不完全为零的数据时很有用。如果为 False,则在计算前进行数据中心化。
- 属性:
- location_形状为 (n_features,) 的 ndarray
估计的位置,即估计的均值。
- covariance_形状为 (n_features, n_features) 的 ndarray
估计的协方差矩阵。
- precision_形状为 (n_features, n_features) 的 ndarray
估计的精度矩阵(逆协方差)。
- costs_(目标,对偶间隙) 对的列表
每次迭代时目标函数和对偶间隙的值列表。仅当 return_costs 为 True 时返回。
在 1.3 版本中新增。
- alpha_float
选定的惩罚参数。
- cv_results_ndarrays 字典
一个包含以下键的字典
- alphas形状为 (n_alphas,) 的 ndarray
所有探索过的惩罚参数。
- split(k)_test_score形状为 (n_alphas,) 的 ndarray
在第 (k) 折留出数据上的对数似然得分。
在 1.0 版本中新增。
- mean_test_score形状为 (n_alphas,) 的 ndarray
各折得分的均值。
在 1.0 版本中新增。
- std_test_score形状为 (n_alphas,) 的 ndarray
各折得分的标准差。
在 1.0 版本中新增。
- n_iter_int
为找到最优 alpha 运行的迭代次数。
- n_features_in_int
在 fit 期间见到的特征数量。
在 0.24 版本中新增。
- feature_names_in_形状为 (
n_features_in_,) 的 ndarray 在 fit 期间见到的特征名称。仅当
X的所有特征名称都是字符串时才定义。在 1.0 版本中新增。
另请参见
graphical_lassoL1 惩罚协方差估计器。
GraphicalLasso使用 L1 惩罚估计器进行稀疏逆协方差估计。
备注
对最优惩罚参数 (
alpha) 的搜索是在迭代细化的网格上进行的:首先计算网格上的交叉验证分数,然后围绕最大值建立一个新的细化网格,以此类推。这里面临的挑战之一是求解器可能无法收敛到条件良好的估计。相应的
alpha值会显示为缺失值,但最优值可能接近这些缺失值。在
fit中,一旦通过交叉验证找到最佳参数alpha,模型将再次使用整个训练集进行拟合。示例
>>> import numpy as np >>> from sklearn.covariance import GraphicalLassoCV >>> true_cov = np.array([[0.8, 0.0, 0.2, 0.0], ... [0.0, 0.4, 0.0, 0.0], ... [0.2, 0.0, 0.3, 0.1], ... [0.0, 0.0, 0.1, 0.7]]) >>> np.random.seed(0) >>> X = np.random.multivariate_normal(mean=[0, 0, 0, 0], ... cov=true_cov, ... size=200) >>> cov = GraphicalLassoCV().fit(X) >>> np.around(cov.covariance_, decimals=3) array([[0.816, 0.051, 0.22 , 0.017], [0.051, 0.364, 0.018, 0.036], [0.22 , 0.018, 0.322, 0.094], [0.017, 0.036, 0.094, 0.69 ]]) >>> np.around(cov.location_, decimals=3) array([0.073, 0.04 , 0.038, 0.143])
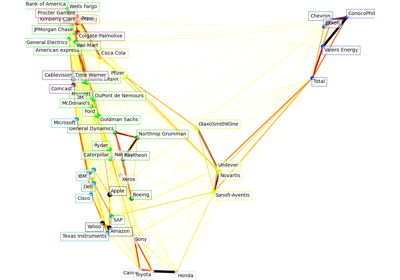
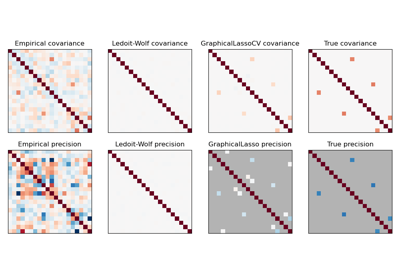
有关
sklearn.covariance.GraphicalLassoCV、sklearn.covariance.ledoit_wolf收缩和高维高斯数据上的经验协方差的比较示例,请参阅稀疏逆协方差估计。- error_norm(comp_cov, norm='frobenius', scaling=True, squared=True)[source]#
计算两个协方差估计器之间的均方误差。
- 参数:
- comp_cov形状为 (n_features, n_features) 的类数组
要比较的协方差。
- norm{“frobenius”, “spectral”},默认值=”frobenius”
用于计算误差的范数类型。可用的误差类型:- ‘frobenius’ (默认):sqrt(tr(A^t.A)) - ‘spectral’:sqrt(max(特征值(A^t.A))),其中 A 是误差
(comp_cov - self.covariance_)。- scalingbool,默认值=True
如果为 True (默认),则平方误差范数除以 n_features。如果为 False,则平方误差范数不重新缩放。
- squaredbool,默认值=True
是否计算平方误差范数或误差范数。如果为 True (默认),则返回平方误差范数。如果为 False,则返回误差范数。
- 返回:
- resultfloat
在 Frobenius 范数意义下,
self和comp_cov协方差估计器之间的均方误差。
- fit(X, y=None, **params)[source]#
将 GraphicalLasso 协方差模型拟合到 X。
- 参数:
- X形状为 (n_samples, n_features) 的类数组
用于计算协方差估计的数据。
- y忽略
不使用,按约定为保持 API 一致性而存在。
- **paramsdict,默认值=None
要传递给 CV 分割器和 cross_val_score 函数的参数。
在 1.5 版本中新增: 仅当
enable_metadata_routing=True时可用,可通过使用sklearn.set_config(enable_metadata_routing=True)进行设置。更多详细信息请参见元数据路由用户指南。
- 返回:
- self对象
返回实例本身。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查阅用户指南以了解路由机制的工作原理。
在 1.5 版本中新增。
- 返回:
- routingMetadataRouter
一个封装了路由信息的
MetadataRouter。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool,默认值=True
如果为 True,将返回此估计器及其包含的作为估计器的子对象的参数。
- 返回:
- paramsdict
参数名称及其对应的值。
- mahalanobis(X)[source]#
计算给定观测值的平方马哈拉诺比斯距离。
- 参数:
- X形状为 (n_samples, n_features) 的类数组
我们计算其马哈拉诺比斯距离的观测值。观测值被假定为来自与 fit 中使用的数据相同的分布。
- 返回:
- dist形状为 (n_samples,) 的 ndarray
观测值的平方马哈拉诺比斯距离。
- score(X_test, y=None)[source]#
计算在估计的高斯模型下
X_test的对数似然。高斯模型由其均值和协方差矩阵定义,分别由
self.location_和self.covariance_表示。- 参数:
- X_test形状为 (n_samples, n_features) 的类数组
用于计算似然的测试数据,其中
n_samples是样本数,n_features是特征数。X_test被假定为来自与 fit 中使用的数据相同的分布(包括中心化)。- y忽略
不使用,按约定为保持 API 一致性而存在。
- 返回:
- resfloat
使用
self.location_和self.covariance_分别作为高斯模型均值和协方差矩阵的估计器时,X_test的对数似然。