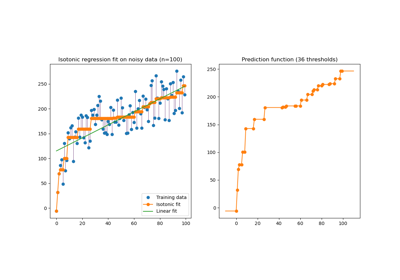
IsotonicRegression#
- class sklearn.isotonic.IsotonicRegression(*, y_min=None, y_max=None, increasing=True, out_of_bounds='nan')[source]#
等渗回归模型。
在用户指南中阅读更多内容。
在 0.13 版本中添加。
- 参数:
- y_min浮点数,默认值=None
最低预测值的下限(最小值仍可能更高)。如果未设置,则默认为-inf。
- y_max浮点数,默认值=None
最高预测值的上限(最大值仍可能更低)。如果未设置,则默认为+inf。
- increasing布尔值或“auto”,默认值=True
确定预测值是应随
X增加还是减少而受约束。“auto”将根据 Spearman 相关估计的符号来决定。- out_of_bounds{‘nan’, ‘clip’, ‘raise’},默认值=’nan’
处理训练域之外的
X值在预测期间的处理方式。‘nan’,预测值将为 NaN。
‘clip’,预测值将被设置为最接近的训练区间端点对应的值。
‘raise’,将引发
ValueError。
- 属性:
- X_min_浮点数
输入数组
X_的最小值,用于左边界。- X_max_浮点数
输入数组
X_的最大值,用于右边界。- X_thresholds_形状为 (n_thresholds,) 的 ndarray
用于插值 y = f(X) 单调函数的唯一升序
X值。在 0.24 版本中添加。
- y_thresholds_形状为 (n_thresholds,) 的 ndarray
适合插值 y = f(X) 单调函数的去重
y值。在 0.24 版本中添加。
- f_函数
覆盖输入域
X的分段插值函数。- increasing_布尔值
推断出的
increasing值。
另请参阅
sklearn.linear_model.LinearRegression普通最小二乘线性回归。
sklearn.ensemble.HistGradientBoostingRegressor接受单调性约束的非参数梯度提升模型。
isotonic_regression用于求解等渗回归模型的函数。
注意事项
平局使用 de Leeuw (1977) 的次要方法打破。
参考文献
Isotonic Median Regression: A Linear Programming Approach Nilotpal Chakravarti Mathematics of Operations Research Vol. 14, No. 2 (May, 1989), pp. 303-308
Isotone Optimization in R : Pool-Adjacent-Violators Algorithm (PAVA) and Active Set Methods de Leeuw, Hornik, Mair Journal of Statistical Software 2009
Correctness of Kruskal’s algorithms for monotone regression with ties de Leeuw, Psychometrica, 1977
示例
>>> from sklearn.datasets import make_regression >>> from sklearn.isotonic import IsotonicRegression >>> X, y = make_regression(n_samples=10, n_features=1, random_state=41) >>> iso_reg = IsotonicRegression().fit(X, y) >>> iso_reg.predict([.1, .2]) array([1.8628, 3.7256])
- fit(X, y, sample_weight=None)[source]#
使用 X, y 作为训练数据拟合模型。
- 参数:
- X形状为 (n_samples,) 或 (n_samples, 1) 的类数组
训练数据。
0.24 版本中的更改: 也接受具有 1 个特征的二维数组。
- y形状为 (n_samples,) 的类数组
训练目标。
- sample_weight形状为 (n_samples,) 的类数组,默认值=None
权重。如果设置为 None,所有权重都将设置为 1(等权重)。
- 返回:
- self对象
返回自身的一个实例。
注意事项
X 被存储以备将来使用,因为
transform需要 X 来插值新的输入数据。
- fit_transform(X, y=None, **fit_params)[source]#
拟合数据,然后进行转换。
使用可选参数
fit_params将转换器拟合到X和y,并返回X的转换版本。- 参数:
- X形状为 (n_samples, n_features) 的类数组
输入样本。
- y形状为 (n_samples,) 或 (n_samples, n_outputs) 的类数组,默认值=None
目标值(无监督转换时为 None)。
- **fit_params字典
额外的拟合参数。
- 返回:
- X_new形状为 (n_samples, n_features_new) 的 ndarray 数组
转换后的数组。
- get_feature_names_out(input_features=None)[source]#
获取转换的输出特征名称。
- 参数:
- input_features字符串类数组或 None,默认值=None
已忽略。
- 返回:
- feature_names_out字符串对象组成的 ndarray
包含一个字符串的 ndarray,例如 [“isotonicregression0”]。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查看用户指南以了解路由机制的工作原理。
- 返回:
- routingMetadataRequest
一个封装路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deep布尔值,默认值=True
如果为 True,将返回此估计器及其包含的作为估计器的子对象的参数。
- 返回:
- params字典
参数名称及其对应值的映射。
- predict(T)[source]#
通过线性插值预测新数据。
- 参数:
- T形状为 (n_samples,) 或 (n_samples, 1) 的类数组
要转换的数据。
- 返回:
- y_pred形状为 (n_samples,) 的 ndarray
转换后的数据。
- score(X, y, sample_weight=None)[source]#
返回测试数据的决定系数。
决定系数 \(R^2\) 定义为 \((1 - \frac{u}{v})\),其中 \(u\) 是残差平方和
((y_true - y_pred)** 2).sum(),\(v\) 是总平方和((y_true - y_true.mean()) ** 2).sum()。最佳得分是 1.0,它也可以是负数(因为模型可能任意地差)。一个总是预测y的期望值,而忽略输入特征的常数模型,将获得 0.0 的 \(R^2\) 分数。- 参数:
- X形状为 (n_samples, n_features) 的类数组
测试样本。对于某些估计器,这可能是一个预计算的核矩阵,或者是一个通用对象列表,形状为
(n_samples, n_samples_fitted),其中n_samples_fitted是估计器拟合中使用的样本数量。- y形状为 (n_samples,) 或 (n_samples, n_outputs) 的类数组
X的真实值。- sample_weight形状为 (n_samples,) 的类数组,默认值=None
样本权重。
- 返回:
- score浮点数
self.predict(X)相对于y的 \(R^2\) 值。
注意事项
从 0.23 版本开始,在回归器上调用
score时使用的 \(R^2\) 分数使用multioutput='uniform_average',以与r2_score的默认值保持一致。这会影响所有多输出回归器(除了MultiOutputRegressor)的score方法。
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') IsotonicRegression[source]#
请求传递给
fit方法的元数据。请注意,此方法仅在
enable_metadata_routing=True时才相关(参见sklearn.set_config)。请参阅用户指南以了解路由机制的工作原理。每个参数的选项有
True:请求元数据,如果提供则传递给fit。如果未提供元数据,则忽略该请求。False:不请求元数据,元估计器不会将其传递给fit。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:元数据应以给定的别名而不是原始名称传递给元估计器。
默认值 (
sklearn.utils.metadata_routing.UNCHANGED) 保留现有请求。这允许您更改某些参数的请求而不更改其他参数。在 1.3 版本中添加。
注意
此方法仅在将此估计器用作元估计器的子估计器时才相关,例如在
Pipeline内部使用时。否则,它没有效果。- 参数:
- sample_weight字符串、True、False 或 None,默认值=sklearn.utils.metadata_routing.UNCHANGED
fit方法中sample_weight参数的元数据路由。
- 返回:
- self对象
更新后的对象。
- set_output(*, transform=None)[source]#
设置输出容器。
有关如何使用此 API 的示例,请参阅Introducing the set_output API。
- 参数:
- transform{“default”, “pandas”, “polars”},默认值=None
配置
transform和fit_transform的输出。"default":转换器的默认输出格式"pandas":DataFrame 输出"polars":Polars 输出None:转换配置未更改
在 1.4 版本中添加: 添加了
"polars"选项。
- 返回:
- self估计器实例
估计器实例。
- set_params(**params)[source]#
设置此估计器的参数。
此方法适用于简单的估计器以及嵌套对象(例如
Pipeline)。后者具有<component>__<parameter>形式的参数,以便可以更新嵌套对象的每个组件。- 参数:
- **params字典
估计器参数。
- 返回:
- self估计器实例
估计器实例。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') IsotonicRegression[source]#
请求传递给
score方法的元数据。请注意,此方法仅在
enable_metadata_routing=True时才相关(参见sklearn.set_config)。请参阅用户指南以了解路由机制的工作原理。每个参数的选项有
True:请求元数据,如果提供则传递给score。如果未提供元数据,则忽略该请求。False:不请求元数据,元估计器不会将其传递给score。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:元数据应以给定的别名而不是原始名称传递给元估计器。
默认值 (
sklearn.utils.metadata_routing.UNCHANGED) 保留现有请求。这允许您更改某些参数的请求而不更改其他参数。在 1.3 版本中添加。
注意
此方法仅在将此估计器用作元估计器的子估计器时才相关,例如在
Pipeline内部使用时。否则,它没有效果。- 参数:
- sample_weight字符串、True、False 或 None,默认值=sklearn.utils.metadata_routing.UNCHANGED
score方法中sample_weight参数的元数据路由。
- 返回:
- self对象
更新后的对象。