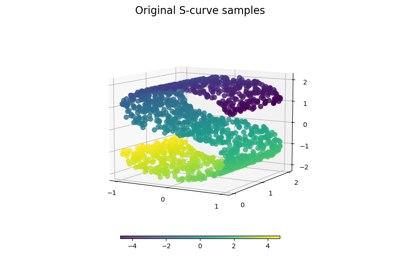
make_s_curve#
- sklearn.datasets.make_s_curve(n_samples=100, *, noise=0.0, random_state=None)[source]#
生成 S 曲线数据集。
在《用户指南》中阅读更多内容。
- 参数:
- n_samplesint, 默认值=100
S 曲线上的样本点数量。
- noisefloat, 默认值=0.0
高斯噪声的标准差。
- random_stateint, RandomState 实例或 None, 默认值=None
确定数据集创建的随机数生成。传入一个整数可在多次函数调用中获得可重现的输出。请参阅《术语表》。
- 返回值:
- X形状为 (n_samples, 3) 的 ndarray
点。
- t形状为 (n_samples,) 的 ndarray
样本在流形中点的主维度上的一元位置。
示例
>>> from sklearn.datasets import make_s_curve >>> X, t = make_s_curve(noise=0.05, random_state=0) >>> X.shape (100, 3) >>> t.shape (100,)