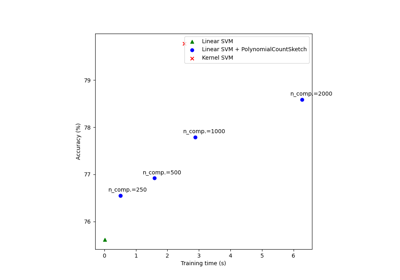
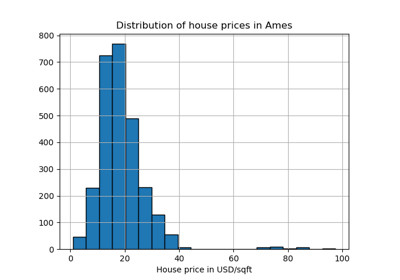
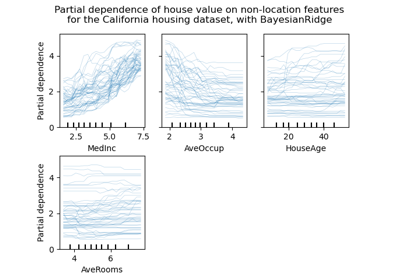
fetch_covtype#
- sklearn.datasets.fetch_covtype(*, data_home=None, download_if_missing=True, random_state=None, shuffle=False, return_X_y=False, as_frame=False, n_retries=3, delay=1.0)[source]#
加载 covertype 数据集(分类)。
如果需要,请下载。
类别
7
总样本数
581012
维度
54
特征
int
在用户指南中阅读更多内容。
- 参数:
- data_homestr 或 path-like,默认值=None
为数据集指定另一个下载和缓存文件夹。默认情况下,所有 scikit-learn 数据都存储在“~/scikit_learn_data”子文件夹中。
- download_if_missingbool,默认值=True
如果为 False,则如果数据在本地不可用,则会引发 OSError,而不是尝试从源站点下载数据。
- random_stateint, RandomState 实例或 None,默认值=None
确定数据集洗牌的随机数生成。传入一个 int 以便在多次函数调用中获得可重现的输出。请参阅术语表。
- shufflebool,默认值=False
是否打乱数据集。
- return_X_ybool,默认值=False
如果为 True,则返回
(data.data, data.target)而不是 Bunch 对象。0.20 版本新增。
- as_framebool,默认值=False
如果为 True,则数据是 pandas DataFrame,包含具有适当数据类型(数值)的列。目标是 pandas DataFrame 或 Series,具体取决于目标列的数量。如果
return_X_y为 True,则 (data,target) 将是如下所述的 pandas DataFrames 或 Series。0.24 版本新增。
- n_retriesint,默认值=3
遇到 HTTP 错误时的重试次数。
1.5 版本新增。
- delayfloat,默认值=1.0
每次重试之间的秒数。
1.5 版本新增。
- 返回:
- dataset
Bunch 类字典对象,具有以下属性。
- data形状为 (581012, 54) 的 ndarray
每行对应数据集中的 54 个特征。
- target形状为 (581012,) 的 ndarray
每个值对应 7 种森林覆盖类型中的一种,值范围为 1 到 7。
- frame形状为 (581012, 55) 的 dataframe
仅当
as_frame=True时存在。包含data和target。- DESCRstr
森林覆盖类型数据集的描述。
- feature_nameslist
数据集列的名称。
- target_names: list
目标列的名称。
- (data, target)如果
return_X_y为 True,则为 tuple 一个包含两个 ndarray 的元组。第一个 ndarray 包含形状为 (n_samples, n_features) 的 2D 数组,其中每行代表一个样本,每列代表特征。第二个 ndarray 形状为 (n_samples,),包含目标样本。
0.20 版本新增。
- dataset
示例
>>> from sklearn.datasets import fetch_covtype >>> cov_type = fetch_covtype() >>> cov_type.data.shape (581012, 54) >>> cov_type.target.shape (581012,) >>> # Let's check the 4 first feature names >>> cov_type.feature_names[:4] ['Elevation', 'Aspect', 'Slope', 'Horizontal_Distance_To_Hydrology']